Transformer가 CNN을 대체하고 있는 요즘 트렌드에 맞춰 Monocular depth estimation 또한 Transformer를 이용해서 높은 성능을 낸 논문이 등장해서 공유하고자 리뷰한다. 이 리뷰에서는 Transformer가 무엇인지는 알고 있다는 가정하에 이야기를 할 것이다.
- Introduction
CNN의 등장으로 다양한 분야(Semantic segmentation, Monocular Depth Estimation, Pedestrian Detection)에서 기존엔 볼 수 없었던 성능의 도약이 있었다. 특히 Pixel level prediction에서 높은 성능 향상이 있었는데 그건 좋은 CNN 모델 ( VGG,ResNet) 들의 Encoder를 보면 spatial resolution을 줄이면서 receptive field를 넓혀서 영상의 global context를 보는 것이 이 중요한 영향을 끼쳐서 그렇다. 하지만 이런 성능 향상이 있었음에도 아직 global context를 modeling 하는 것은 CNN의 한계로 작용하고 있다. 이러한 문제를 해결하기 위해서 커널사이즈를 키우거나 피라미도로 모델을 구성하거나 하는 등을 많은 연구에서 도입했지만 성능의 퀀텀 점프를 할만한 방법론은 없었다. 이러한 문제를 해결하기 위해서 이 논문에서는 Transformer를 Monocular depth estimation에 적용한 것을 제안한다.
Transformer는 원래는 NLP 분야에서 넓은 Receptive field를 가지기 위해서 사용되던 방식으로 최근 VIT라는 vision 분야에 적용할 수 있는 방식이 제안된 후 CNN과 비교되는 높은 성능을 보인 후 다양한 변화를 거치며 연구되고 있다. 이 논문에서 Transformer를 이용한 방법론의 주요 특징은 다음과 같다.
- Monocualr depth estimation과 surface noramal prediction 을 Transformer로 해결한 것은 이 논문이 처음이며, 기존 CNN 방식들 보다 높은 성능향상을 보여준다.
- 멀티 스케일 정보를 활용하고 융합하며 멀티 스케일을 더 잘 모델링하기 위해 어텐션 게이트 디코더의 서로 다른 affinity 맵 간에 정보를 전달하도록 설계된 새롭고 효과적인 통합 어텐션 게이트 구조를 제안했다.
- Method
1.1 Enoder
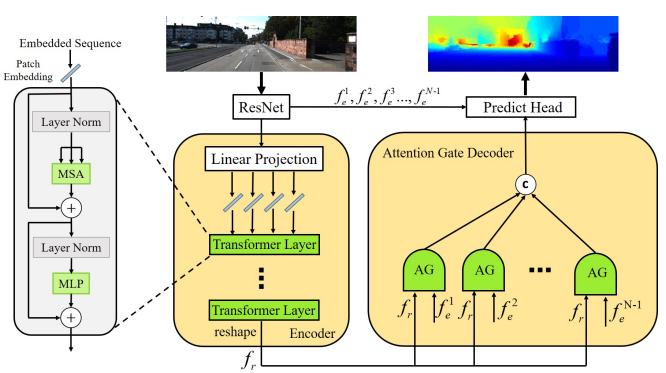
그림 1에 이 논문에서 제안하는 모델의 주요 방식을 볼 수 있다. 기존의 visual transformer 방법론들은 3채널 이미지를 Flatten 해서 Transformer를 진행했지만 이 논문에서는 CNN과 Transformer의 하이브리드 방식을 제안한다고 한다. 그림 1을 보면 Resnet을 이용해 영상을 encode한 후 그 output에 patch를 적용해서 각 patch 마다 flatten 하게 된다. 이렇게 CNN 모델을 태우게 되면 각 픽셀의 물리적의미가 사라졌기 때문에 position embedding을 제거했다고 한다.
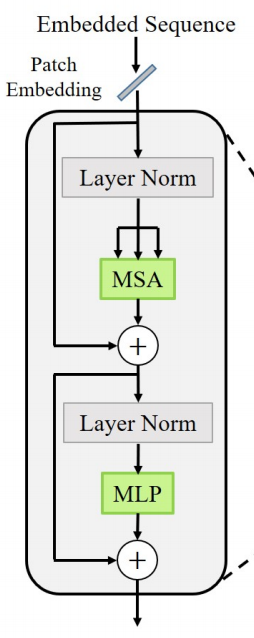
Resnet을 Patch 로 나누어 Embedding 한 후 Tranformer layer의 입력으로 사용하게 되는데 Transformer layer는 그림 2와 같다. MSA는 Multi headed self-attention module로 독립적인 학습 파라미터를 가진 매트릭스에 의해 m 곱으로 계산된다는 것을 의미한다. 여기서 MSA의 식은 다음과 같다.
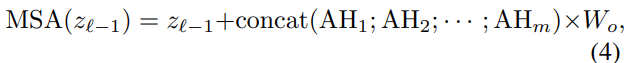
그리고 위의 식에서 AH는 다음과 같다.
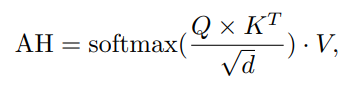
이 식에서 Q,K,V는 Query, Key Value이며 이는 기존 Transformer에서 사용되는 방식과 동일하다. MSA를 이용해 각 특징에 대해 학습한 후 Multi-layer Perceptron(MLP) bloch과 layer noramalization을 이용해 전체적인 Normalization 해준다.
1. 2 Attention gate
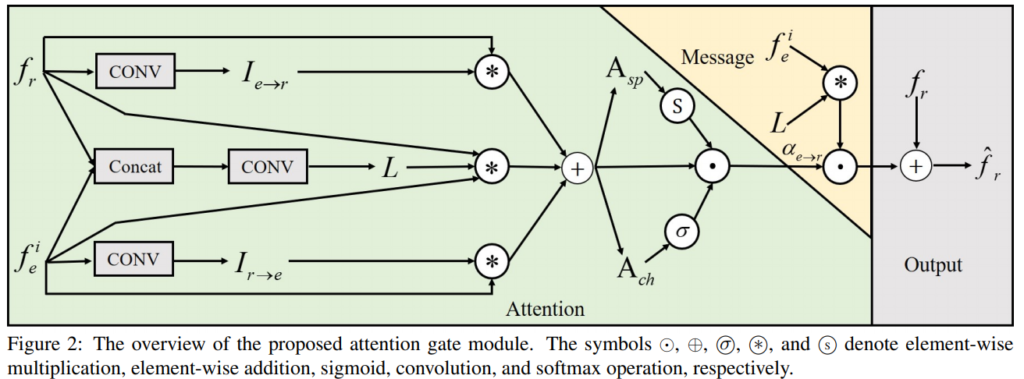
기존 Visual Tranformer 방법론들은 이 Attention Gate에서 단순히 concatenate와 Weight Average를 사용했던 것과는 다르게 그림 3 와 같이 Multi-sclae feature map을 사용할 수 있도록 변경했다고 한다. 그림 1과 그림 3를 같이 봐야 이해가 좀 더 편한데 요기서 fr은 encoder를 통해 나온 feature이고 e는 resnet에서 추출한 feature이다.
세부적으로 Attention 모듈을 보면 Attention과 message 두 부분으로 나눌 수 있다. 이 논문에서는 Attention 파트에 대한 새로운 결합 방식을 제안한다.
저자는 두 개의 공간 및 채널별 예측이 계산되는 Dual attention network 에서 영감을 받아, 다른 spatial 및 channel attention 변수를 추론하는 것을 선택했다.
그림 3 과 같은 Attention module을 통해서 Depth 가 예측이 되고 predict Depth를 실제 Depth와 Log Distantance를 이용해 Loss를 계산하여 학습한다.
Result
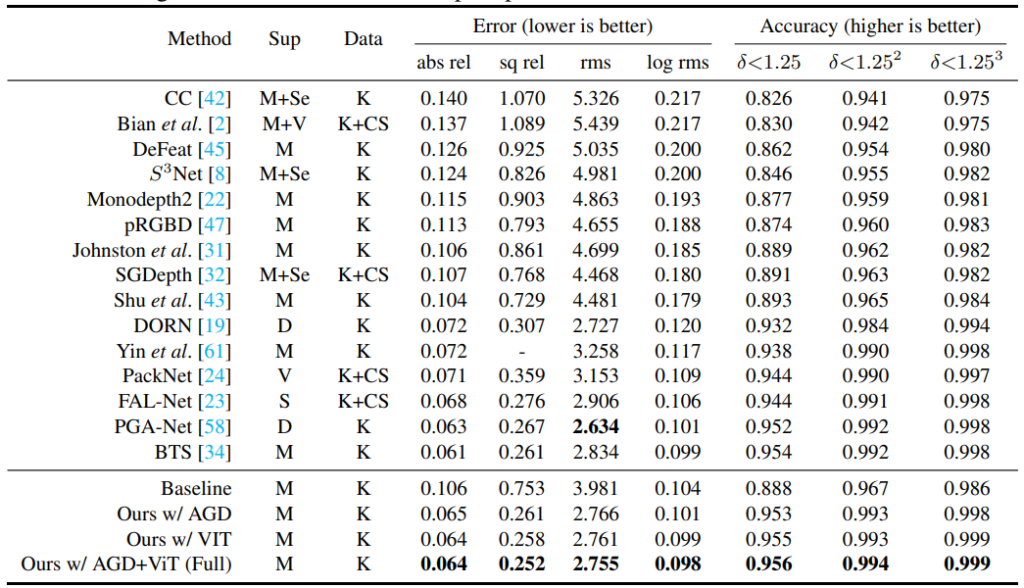
KITTI 데이터 셋에서 정량적 평가는 표 1 과 같다. Supervised 방식의 기존 방법론 BTS나 PGA-Net 과 같은 방법론들과 성능이 유사하거나 조금 높은 것은 볼 수 있다.사실 Monodepth2(Semi-supervised) 와의 성능차이를 보고 와 진짜 성능 좋다라고 생각하고 논문을 읽었었는데, 다시 보니 성능이 그렇게 차이가 나며 좋은 것은 아니라 실망했지만, 그래도 CNN 베이스 방법론들 보다 Transofomer 방법론을 적용하니 성능이 높은 것을 보면, Transformer로 변환해야 되는 방향성이 맞는 것 같다. 이 외에도 다양한 정성적 결과와 다양한 데이터 셋에서 의 성능을 볼 수 있는데 그건 세미나에서 다뤄보도록 하겠다.
Visual Transformer와 관련된 논문을 아직 읽지 않아서 Attention Gate에 대해 잘 알지 못하는데, Attention Gate에 대해서 설명 부탁드립니다.
CNN에서 나온 feature를 Transformer의 input으로 갖는다는 것은 어떤 의미를 가질까요?
Transformer 구조가 CNN보다 나은 성능을 보였던건 Inductive bias가 적어 표현력에 있어 범위가 넓어져 대용량 데이터 셋에 보다 유리했던 점으로 알고 있었는데, Inductive bias가 큰 CNN을 우선적으로 사용해 표현력의 범위의 제약을 두고 그것을 transformer 구조에 넣은 것은 근본적으로 표현력에 제한이 생겨 표현력 관점에서 transformer 구조의 장점을 살리지 못하는 것으로 보입니다.
표현력의 범위가 넓어진다는 장점을 포기하고서라도 생기는 장점이 있어 CNN과 transformer를 결합한 것이라면 어떤 것이 있을까요?