이번에 리뷰할 주제도 최근 계속 리뷰해온 6D DoF pose estimation입니다. 아무래도 과제, 시험, 논문 등등으로 바쁜 관계로 개인적으로 논문읽는 시간 확보가 힘들어서 X-review에서만큼은 관심분야인 X-review를 주로 다루고자 합니다.
6DoF에 관심이 있는 이유는 Robotics와 연관시키기 좋아서 인데요. 로보이나 6DoF에 관심이 있으신 분들에게는 큰 의미있는 리뷰가 될거라고 생각합니다.
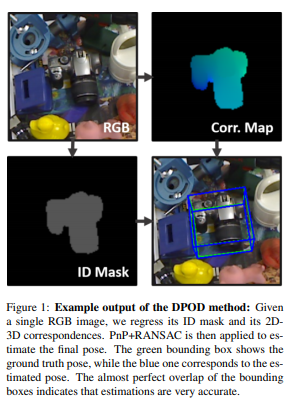
제 리뷰들을 구독해오셨다면, 이 티저영상을 보고 어떠한 논문인지 대충 감이 오실거 같은데요. 일단 특징으로는 RGB이미지를 사용하고, ID 마스크와 Corr map을 만들고 그를 이용해 6D pose를 구하는 그런 방법론입니다. 기존 방법들에 비하면 굉장히 간단해 보이는데요. 여기서 주목해야할점은 RGB만을 사용한단거고, end-to-end라는 점 입니다.
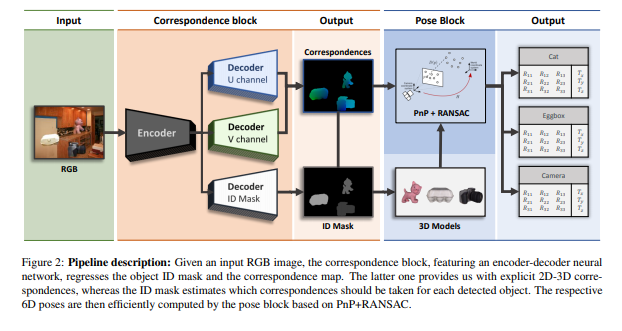
아키텍처를 살펴보시면, RGB 이미지가 인풋으로 들어가고 Encoder를 거친다음, 3개의 decoder로 나누어집니다. 각각 위의 2개의 encoder는 3D bounding box를 2D로 projection 시켜서 해당 좌표값을 regression하는 것이 아닌 U,V 채널을 구하고, dense한 correspondences를 얻는 방식입니다. 그리고 마지막으로 3번째 디코더는 ID mask를 segmentation합니다.
이후, pixel-level로 분할된 segmentation 정보와 dense correspondences는 PnP알고리즘과 RANSAC를 거쳐 6자유도 자세를 추론하는데 사용됩니다.
해당 논문에서는 real데이터와 synthetic 데이터 모두에 대해서 학습및 평가를 진애합니다. 그 이유는 각각의 데이터들이 가지는 장점이 있기 때문입니다. 먼저 real데이터는 실제상황에서 찍은 데이터들이기때문에 실제 implementation하는 관점에서 보면 유의미한 데이터입니다. 그러나 이러한 real data에는 단점이 존재합니다. 우선 light condition에 편향될 수 있습니다. 이게 무슨소리냐면, dataset을 촬영할 때, 조명 조건에 편향되서 학습을하게되면, 실제로 모델이 추론을 할때, 해당 조명조건에서만 좋은 성능이 나올 수 있는 것 입니다. 또한, 또 다른 단점으로, annotation을 하는데 cost가 많이 듭니다.
이와 반대로, synthetic data셋은 기존의 데이터를 기반으로 인위적으로 만드는 데이터셋을 의미합니다. 따라서, 한개의 3D 모델을 이용해서 다양한 viewpoint에서 바라보는 무한대의 이미지를 생성 할 수 있습니다. 이와 더불어 data augmentation을 적용하면 light condition, blur 등… 다양한 조건에 대해 만들어 낼 수 있습니다. Occlusion을 일부러 재현하여 occlusion에 대한 강인성을 테스트해보기 위해 제작된 LINEMONE OCCLUSION도 있듯이, synthetic dataset은 real dataset에는 존재하지 않는 이점을 가집니다. 따라서 논문에서는 두개의 데이터셋을 각각 고려하여, 학습 및 평가를 해보았습니다. 주저리 주저리 써보았는데, 실제로 논문에서도 방법론파트에 데이터셋에 대한 설명이 길게 되어있고 상당한 부분을 차지합니다.
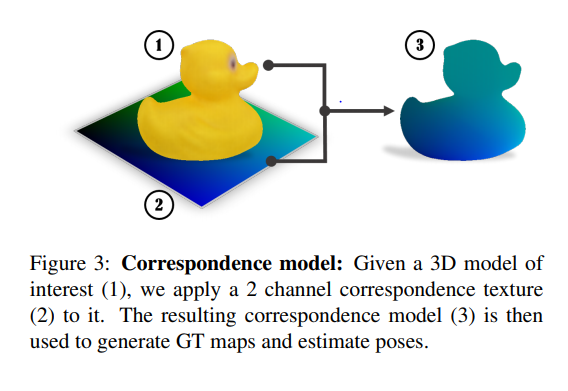
다음으로는 2D-3D correspondence에 대해서 얘기 해보겠습니다. 위와 같이 오리가 있으면, 2D-3D correspondence를 구해서 texture를 부여하는 식인데요. 무슨소리냐면…

3D좌표계상에있는 물체가 2D 이미지 평면하고 correspond하는 점을 찾고, 해당 corresponding point들을 거리에따라 0~255 의 intensity로 바운딩시키는 것 입니다. 해당 논문에서 U, V는 이미지평면위의 좌표를 의미하고, 2채널의 0~255사이의 intensity를 가집니다.
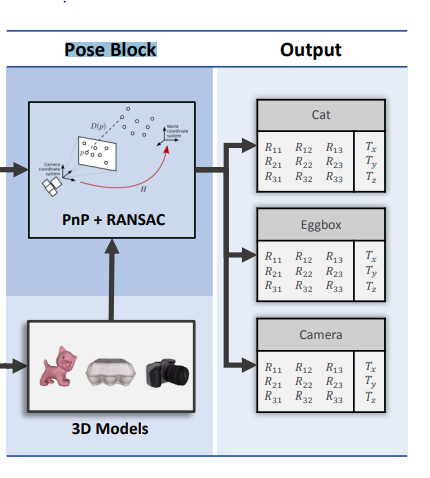
이 후 pose block에서는 해당 정보들을 이용해서 PnP와 RANSAC을 수행합니다. 이 때, PnP는 6DoF 자세 추정 테스크에서는 상당히 많이 나오는 개념인데요. 해당 위키에 설명이 자세히 나와있습니다. 결국에 PnP는 2D-3D correspondences와 3D물체의 좌표가 주어져있을때, 캘리브레이션된 카메라의 6DoF 자세를 구하는 알고리즘입니다. 이를 역이용해서 6DoF pose estimation에서는 물체의 자세를 구하는데 사용합니다. 이때, PnP알고리즘에는 여러가지가 있으며, 고전적인 방법으로 RANSAC과 같이사용되는 경우가 많은데 이는 아웃라이어를 제거하기 위함입니다.
그렇게 6D 자세를 구한 것이 최종 output으로 나오는데요. 위의 그림에서는 인풋인 RGB이미지에 3개의 인스턴스만이 존재하기 때문에 총 3개의 output이 나왔습니다. 그리고 각각의 아웃풋은 rotation 과 translation 컴포넌트로 구성되어있으며, 이는 6자유도 자세를 의미합니다.
예시
이제 이해를 돕기위해 예시를 살펴보겠습니다. 먼저 아키텍쳐를 보시면, 320 × 240 × 3의 RGB이미지를 인풋으로 받습니다. ResNet기반으로된 12개의 레이어를 가진 인코더를 통과하고 이미지로부터 피쳐를 뽑게 됩니다.
해당 피쳐는 3개의 디코더로 들어가며, 각각의 디코더는 원본의 이미지 사이즈를 복원합니다.
1, 2번 디코더는 H,W,C의 아웃풋을 가지며 이때, C는 유니크한 컬러의 갯수, 즉, 256을 의미합니다. 아까 앞에서 설명드렸듯이, C에는 0~255의 수를 가진다고 하였습니다. 이렇게 1번 디코더로부터 U를 뽑아내고, 같은원리로 2번으로부터 V를 뽑아냅니다. 그리고 해당 값들은 이미지평면에서 correspondences에 texture를 부여하는 색상을 의미합니다. 이 때, 직접적으로 correspondences를 regression하는 것보다. 색상으로 regression하는 것이 좀 더 빠르게 수렴한다고 합니다. 그래서 해당 논문에서는 그 부분을 강조하고 있습니다.
3번 디코더에서는 H,W,O 텐서를 아웃풋으로 내보냅니다. 이 때, O는 클래스의갯수입니다. Segmentation이기 때문에 어렵지않게 이해되리라고 생각합니다.
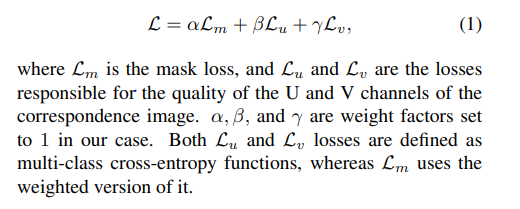
Loss는 간단하게 멀티클래스에 대한 classification으로 보고, cross entropy를 사용하였습니다. 그리고 각각의 loss에 weight factor를 붙혔습니다. 이와같은 테크닉은 다른논문에서도 많이 사용하는 방법이기 때문에 어렵지 않은거 같습니다.
이제 이러한 값들이 PnP, RANSAC알고리즘에 태워져 각각의 인스턴스마다의 6D 포즈를 구합니다.
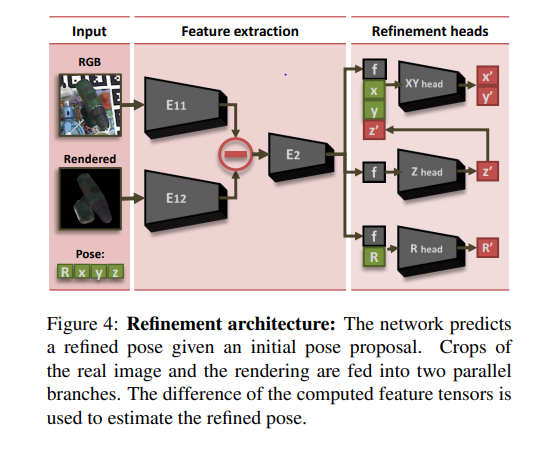
마지막으로 Refinement에 대해서 이야기해보겠습니다. 해당 논문에서는 refinement를 네트워크를 통해 해결합니다. object를 찾고 crop된 부분과 predicted된 pose로 부터 뽑아낸 redering값을 인풋으로 받습니다. 그리고, 각각 네트워크에 태워지고 아웃풋값의 차이를 계산합니다. 해당 차이를 다시 네트워크에 태워서 피쳐맵을 뽑아내고 해당 피쳐맵을 이용하여 refine된 x’,y’,z’,R’ 의 재추정된 포즈를 구합니다.
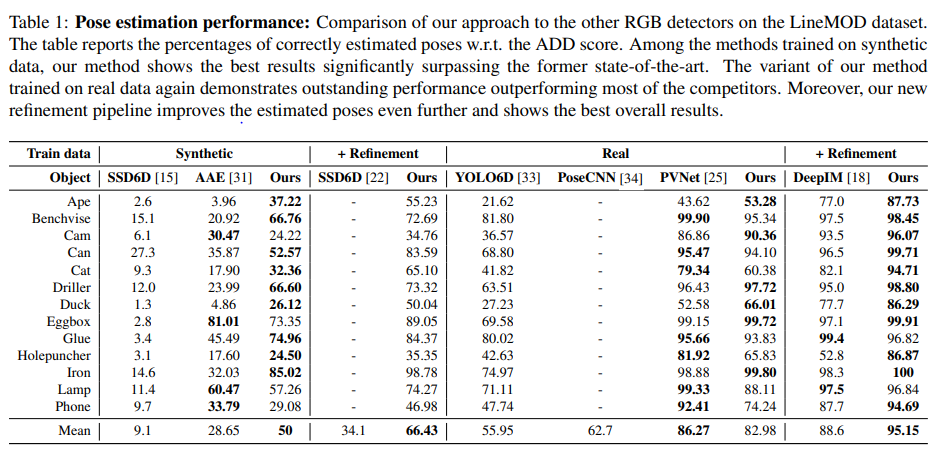
실험이 굉장히 다양한데, synthetic과 real데이터 // refinement 전과 후로 나뉘어서 진행하였습니다. 그 결과 2*2로 총 4개의 조합에서 real+without refinement를 제외하고 모두 해당시기 당시에 large margin으로 SOTA를 찍었습니다
Evaluation metric은 ADD로 실제 GT와의 거리값을 의미하는데요 해당 ADD가 일정 임계치 이상이면 맞게 pose를 추정했다고 하고, 그 맞게 추정한 pose를 Accuracy score로 다시 구합니다. 이러한 매트릭은 6DoF에서는 항상 사용하는거 같습니다.
정성적인 결과이구요.
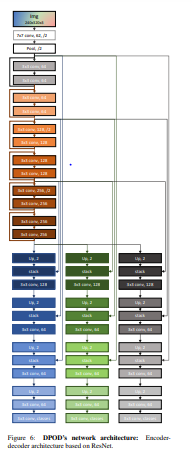
음… 사진이 잘 안보이는데 논문을 참고해보시면 좀 더 아키텍쳐에 대해 자세히 나옵니다. 워낙 자세히 나와있어서 구현하는데 그리 어렵워보이진 않네요.
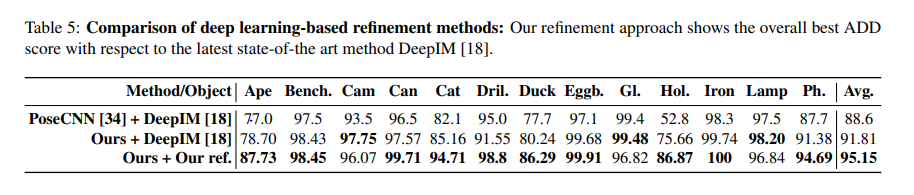
다른 DNN기반 / refinement 모델과 비교했을때, 좋은 성능을 보였습니다.
후기
비교적 간단하면서도 좋은 성능을 낸 논문인거 같습니다. 핵심으로는, end-to-end라는 점이고, 2D-3D correspondences를 바로 regression하지 않고, U, V의 색상값으로 regression한점이 특이했습니다. 이상 리뷰 마치겠습니다.
해당모델은 기본적으로 3D모델링데이터가 필요한건가요?
아뇨 RGB만을 이용합니다 .다만, 다양한 viewpoint에서 synthetic 데이터셋을 만들 때는 3D 모델링 데이터를 사용합니다.
음… PnP를 수행하려면 2쌍의 이차원의 대응점과 3차원의 대응점, 즉 최소 3개의 점이 필요합니다. 근데 해당 방법에서는 u,v를 대응쌍으로 사용하고 ID map으로부터 3차원 대응점을 추정하여 pnp를 진행해 6DoF를 구하겠다는 걸로 이해를 했습니다….
질문드리고자 하는 내용은
– u,v를 0~255의 색상으로 회귀하는 건 알겠지만… 어떻게 대응쌍을 구하는지 이해를 못하겠습니다.
– 해당 방법론은 모노 영상을 이용한 방법인가요? 스테레오인가요?
– PnP 이전까지가 end-to-end인거죠? 아니라면 역전파 시, PnP와 RANSAC 어떻게 처리 했나요?
1. u, v와 corresponding 하는 3D상의 점들이 여러개 있기 때문에 해당 부분을 이용해서 PnP를 태웁니다.
2. 모노영상을 이용한 방법론입니다.
3. 네 pnp이전까지가 end-to-end이고 기존의 방법론에서는 해당부분을 2 stage로 처리했었습니다. 즉, segmentation하고 3D 좌표 regression을 end-to-end로 처리했다 이런 의미였는데, 제가 글을 잘못적은거 같습니다.