이번 리뷰 논문은 딥러닝이 적용된 Vision-IMU Odometry(VIO, mono)이며, 상황에 따라 센서의 가중치를 조절하여 환경 강인성을 갖춘 방법론을 소개합니다.
Intro
이전 세미나 및 리뷰를 통해 Odometry는 주체의 움직임을 센서를 이용하여 측정하는 방법이라고 설명을 했습니다.
그럼 사람은 어떻게 자신의 움직임을 인지할까요?
다양한 방법 중 위의 자기 움직임 인지에 가장 중요한 감각 신호 두 가지 중 하나는 눈을 이용한 방법입니다. 눈으로부터 획득한 시각적인 정보로 움직임에 따라 발생하는 광학 흐름을 이용하여 움직임을 인지 합니다. 또 다른 한가지는 전정기관(귀의 내이)으로부터 감지되는 관성의 변화를 이용하여 움직임을 인지하는 방법이 있습니다. 전정기관의 내부에는 림프액이 가득 차있고, 그 안에 다양한 크기의 이석이라는 작은 돌들이 있어 중력 및 선형 가속도 운동을 감지합니다. 이러한 구조로 전정기관은 이석을 이용하여 선형적인 가속도 운동을 감지하고 림프액을 통해 몸의 회전 움직임을 감지합니다. 두 감각은 상호보완적인 특징을 가집니다. 예를 들어 신체를 빙글빙글 돌리고 앞으로 똑바로 걸을 경우, 우리는 비틀거리며 걸어가게 됩니다. 이 때, 시각적인 정보는 정상적인 상태지만 전정기관이 아직 정상적인 상태가 아니기 때문에 제대로된 균형 감각을 회복하기 힘듭니다. 또는 눈을 가리고 의자에 앉은 상태에서 타인의 힘으로 이동을 할 경우에도 우리는 움직임을 감지 할 수 있습니다. 하지만 가속도적인 측위만 가능하지 이동 정도에 대한 측정이 힘듭니다. 이처럼 두 감각은 상호보완적으로 움직임을 예측합니다.
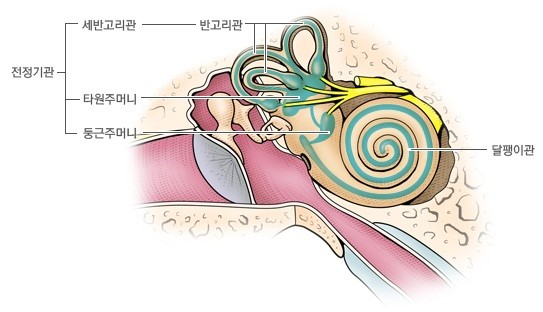
VIO는 카메라와 IMU 센서를 위에서 설명한 눈과 전정기관을 모사하여 카메라의 움직임을 측정합니다. 카메라는 눈과 동일하게 촬영된 연속적인 영상으로부터 광학 흐름을 측정하여 자신의 움직임을 관측하고, IMU는 전정기관과 동일하게 관성을 측정하여 움직임을 측정합니다.
++ IMU(Inertial Measurement Unit) : 선형적인 가속도를 측정하는 가속도계와 회전에 대한 가속도(각가속도)를 측정하는 자이로스코프로 구성된 관성 측정 센서
두 신체의 감각을 모사한 방법인 만큼 보다 강력하고 정확한 카메라 움직임에 추정이 가능해집니다. 또한 카메라와 IMU 센서는 타센서보다 비교적 값싸고 대부분의 스마트폰, 무인 항공기, 지상로봇에서 널리 사용되어지기 때문에 많은 연구가 진행되어져 왔습니다.
하지만 많은 연구들을 실제 어플리케이션에 적용 시, 기대 했던 성능보다 저하된 결과를 보여줍니다. 이는 센서 이상 상황의 영향이 크기 때문입니다. 발생 가능한 센서 이상에는 카메라의 가려짐, 저조도의 환경이 있으며, IMU 관점에서는 심한 노이즈와 지속된 측정으로 발생하는 drift 현상이 있습니다. 또한 두 센서의 동기화의 어긋남이 있습니다. 센서 이상 상황 문제로 실사용 시, 성능 저하가 발생하게 됩니다.
이런 문제를 해결하기 위해서 해당 연구는 선택적 센서 융합 모델링 방법을 제안합니다.
Method
Neural VIO Models with Selective Fusion
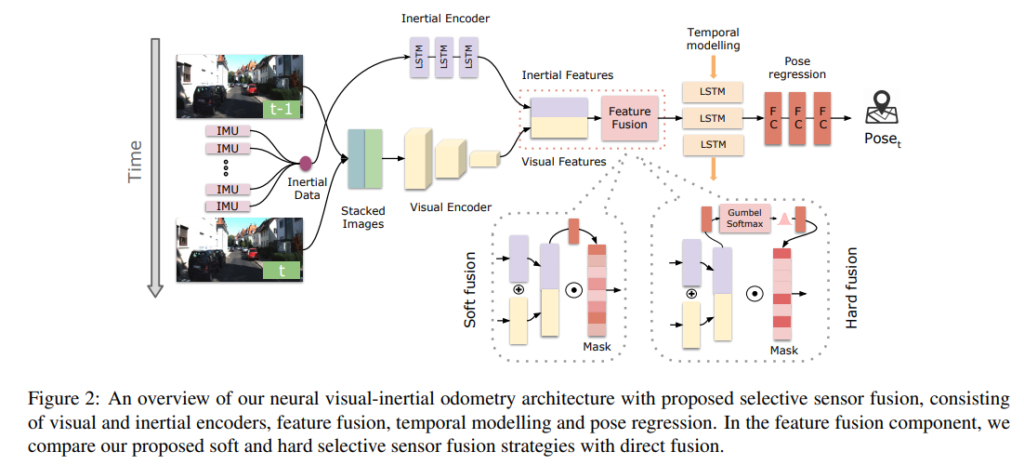
해당 섹션에서는 end-to-end의 NN을 이용한 VIO 구조를 소개합니다. 영상과 IMU Encoder, feature fusion, temporal modeling, pose regression에 대해 다룹니다.
Visual Feature Encoder
Visual Encoder는 단안 카메라로부터 촬영된 두 장의 연속적인 영상들(x_v)로부터 latent feature a_v를 추출합니다. 영상의 컨테스트를 추출하기보다는 기하학적 특징을 학습하고 추출하기 원하기 때문에 flowNet_simple을 encoder로 이용합니다.
++ flowNet : NN 기반의 optical flow
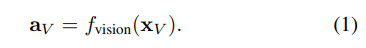
Inertial Feature Encoder
IMU 센서의 데이터 x_I는 영상 센서보다 빠른 속도로 취득이 됩니다. IONet에 영감을 받아 두 계층의 양방향 LSTM(128 hidden states)을 이용하여 feature vector a_I를 추출하여 사용합니다.
++IONet : NN기반의 Inertial odomety
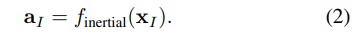
Fusion Function
앞에서 생성한 visual feature a_v와 inertial feature a_I를 fusion function g를 이용하여 합성한 feature z를 생성합니다.

합성 방법에는 직접적으로 concat하는 방법도 있지만, 보다 강인한 센서 융합 모델을 만들기 위해서 결정론적 방법을 사용하는 g_soft와 확률적인 방법을 적용하는 g_hard 두 방법을 제안합니다. 두 모델은 inertial-visual feature로부터 weight를 추출하는 방식을 이용하며, 또다른 NN 모델을 이용하여 생성됩니다. 구체적인 방법은 아래에서 추가적을 다루도록 하겠습니다.
Temporal Modelling and Pose Regression
Odeometry는 상대적인 움직임 측정으로 정확한 포즈를 측정하기 위해서는 시간적 흐름에 의존적이게 됩니다. 그렇기에 시간 의존성을 고려하여 모델링이 되어야 합니다. 그렇기에 RNN 구조를 가지며, Inertial Feature Encoder에서 사용된 모델과 동일한 두 계층을 가진 양방향 LSTM을 이용합니다. 추론된 값은 두 개의 FC를 넘어 시간적 포즈 정보가 담긴 y_t를 추정합니다.
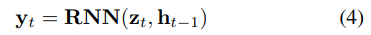
Selective Sensor Fusion
Direct Fusion
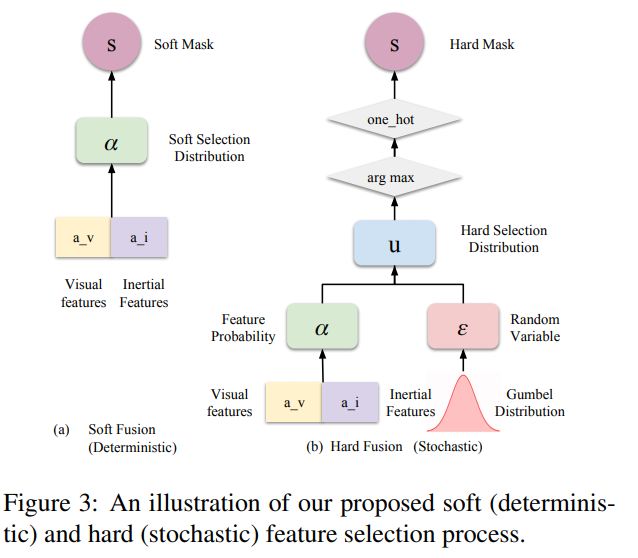
해당 방법은 두 feature를 concat 후, MLP 진행하는 방법입니다. 가장 나이브한 방법이지만, end-to-end 방법으로는 가장 이상적인 방법으로 feature selection에 대한 선택 및 예측을 학습하도록 합니다. 베이스가 되는 방법에 해당합니다.
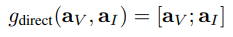
Soft Fusion (Deterministic)
Soft Fusion은 self-attention mechanism과 동일한 구조입니다. MLP와 sigmoid로 구성된 모듈을 통해 센서 선택을 잘하도록 feature를 re-weighted를 하는 것이 목표로 합니다. [0, 1] 사이의 값으로 구성되며 visual Score S_v와 inertial score S_I로 요소별 곱을 통해 결정론적이고 차별성을 갖추도록 합니다.
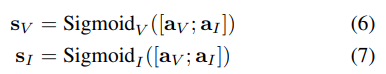
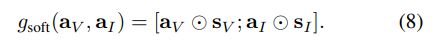
Hard Fusion (Stochastic)
해당 연구에서는 연속적인 가중치로 재측정하는 soft fusion 외에도 이진 마스크로 가중치를 재측정하여 보다 강력한 전달/차단하는 hard fusion을 제안합니다. 해당 모듈은 이진 마스크를 생성하는 확률 함수를 학습합니다. 여러 확률 함수 중 대표적인 이산 확률 분포인 베르누이 분포를 이용하여 이진 마스크를 추정하고자 합니다.
즉, 우리는 visual과 inertial에서의 내부적인 확률을 추론 한 alpha 값(수식 (12)~(13) )의 베르누이 분포로부터 이진 마스크 형태의 re-weight 값 s_v, s_I을 획득하여 강력한 전달/차단 fusion 기법 g_hard을 이용하는 것이 목표입니다.
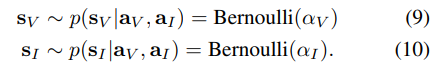
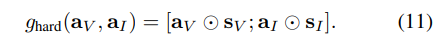
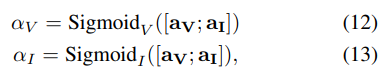
하지만 확률 분포를 미분하는 일은 어렵습니다. 그렇기에 여기서는 트릭이 사용되어집니다. re-parameterization trick 중 Gumbel Softmax(Gumbel max trick)라는 기법을 이용합니다. (Fig 3-(b))
수식 (12), (13)에서 얻은 n차원의 벡터 alpah=(π1,π2,…,πn)가 주어졌을 때 카테고리 확률 변수라고 칭합니다. 즉, 각 feature의 신뢰성에 대한 카테고리별 확률로 가정합니다.
그 후, epsilon e_i는 stander gumbel 분포를 따르고 독립적인라고 할 때, 클래스 확률이 π _i인 카테고리 분포에서의 샘플 s를 다음과 같이 나타낼 수 있습니다.
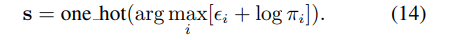
하지만 argmax는 미분이 불가능 하기 때문에 softmax에 근사하고, temperture tau를 이용하여 수식 14를 미분이 가능한 수식으로 근사를 하여 사용합니다.
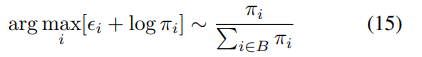
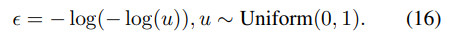
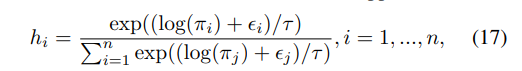
해당 형태는 tau가 0이면 수식 14와 유사한 형태를 가지고 tau가 무한대에 가까워질 수록 uniform 분포와 유사해지는 특징을 가지고 있습니다.
++ 그리고 loss 수식에 대한 언급이 없음… 음.. VINet이 베이스 논문인 것으로 보아, 같은 Loss를 사용했을 거라고 보는데… 코드도 공개 한다고 했으면서; 곧 공개한다는데 이슈에는 언제 공개하냐는 글 뿐….
_________________________________________________________________

정리하자면 feature selection의 [0, 1] 사이 가중치를 학습 통하여 얻는 soft fusion과 이진 마스크를 이용하여 강력한 전달/차단을 하는 hard fusion 기법을 소개했습니다. soft fusion 기법은 latent feature 간 불확실성을 처리하는 데 좋은 방법입니다. 그에 비해 hard fusion은 정규 분포를 이용하기 때문에 보다 나은 일반화된 능력과 불완전한 sensor data에 높은 내성을 가지는 특징을 가집니다.
Experiment
해당 실험에서는 제안한 모델이 불확실성을 가진 센서 데이터로부터 얼마나 강인한지 테스트를 하기 위해 KITTI(실외-차량), EuRoC MAV(실내-드론), PennCOSUVIO(실내/외-hand-held)에서 가상의 센서 이상 상황을 만들어 실험을 진행하였습니다.
vision에서는 아래와 같은 가상 상황을 만들었습니다.
– Occlusion : 128×128 크기의 mask를 샘플 이미지에 오버레이하여 생성
– blur+noise : 블러는 가우시안 블러, 노이즈는 솔트페퍼를 사용
– Missing data : 랜덤하게 10%를 black out.
IMU는 아래와 같은 가상 상황을 만들었습니다.
– Noise-bias : 가속도계에는 화이트 노이즈, 자이로스코프에는 고정 bias를 추가함.
– Missing data : 무작위로 두개의 연속적인 데이터를 제거함.
추가로 공간적/시간적 오정렬을 추가함.
– Spatial misalignment : 초기 정렬 값을 10도 틀어서 모델링
– Temporal misalignment : 비동기화. 구체적인 방법은 미기재함.
++ Vision Only : DeepVO, VIO Direct : VINet
(각 실험의 1-2열은 translation에 대한 MAE, rotation에 대한 MAE 입니다)
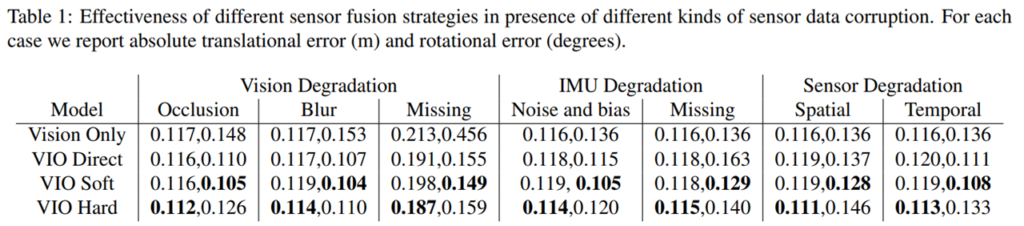
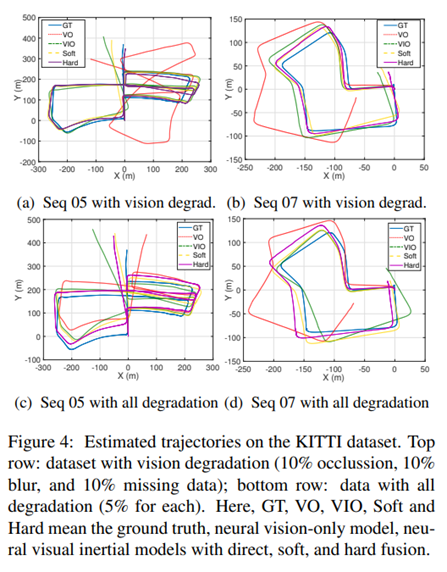
Table 1을 보면 제안된 퓨전 기법을 사용할 경우, 성능이 향상되는 것을 볼 수 있다. 특징적인 부분은 hard fusuin을 사용할 경우 vision에서 높은 성능과 translation에서 높은 성능을 가진 걸 볼 수 있다. 이를 통해 vison의 특징이 지역적이고 이산적인 특징을 가지고 있음을 알 수 있다. 그렇기에 이진 마스크를 사용하는 hard fusion에서 보다 강인한 특징을 보여준다. 반면에 soft fusion인 경우, 연속적인 weight를 이용하기 때문에 연속적 특징을 가진 inertial data의 장점인 rotation에서 보다 높은 성능을 가진 걸 볼 수 있다. (정성적 결과는 fig 4에서 확인 가능)
Conclusion
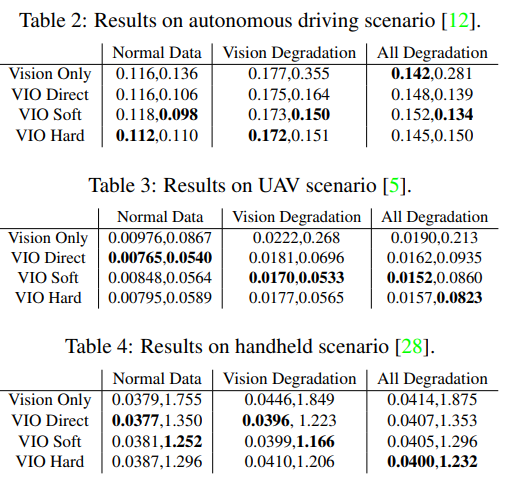
이번 리뷰는 기본 연구와 매우 직관되는 연구 주제이다. Hard fusion의 이진 마스크를 이용하여 inertial sensor와 vision sensor에 대한 정량적인 결과에 대해 분석 또한 존재한다.
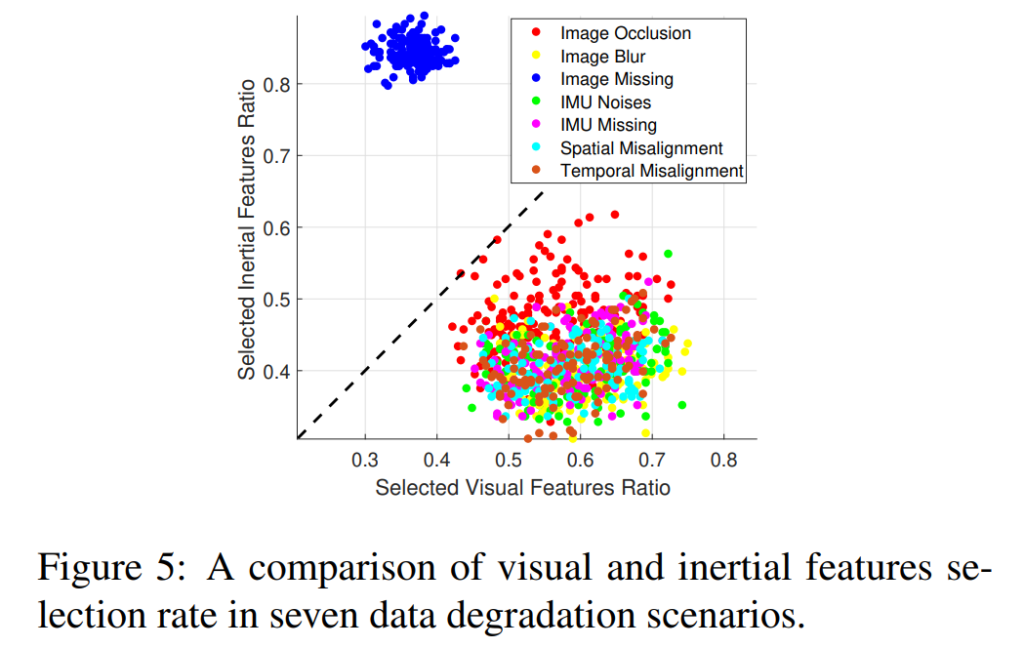
Fig 5을 보면 대부분의 이상 상화에서 vision의 비율이 압도적인 걸 확인 할 수 있다. 하지만 시각적인 정보가 Missing인 경우 IMU 센서가 중요해진다. 하지만 그외의 vision의 이상 상황에서도 시각적 특징의 비율이 높지만, 다른 이상 상황에 비해 IMU 센서의 비율이 높아진 걸 확인 할 수 있다. 이러한 원인으로는 vison의 베이스 모델인 FlowNet에서 시각에서의 이상 상황을 어느 정도 해결하기 때문이라고 한다. 즉, 다시 말하면 시각과 관성의 모델의 불균형이 원인이라는 것. 또는 데이터 상의 궤도가 원인이라고 해석 할 수 있다. 비전인 경우 점진적인(선형적인) 변화에서 신뢰도가 높은 모습을 보여준다. 반면에 관성 센서는 갑작스런 변화와 회전에 강인한 모습을 보여준다. 그렇기에 이전 궤도의 정보도 가중치의 정보로 준다면 보다 강인한 모델이 만들어지지 않을까 하는 생각을 한다.