안녕하세요 흥미로운 주제로 리뷰를 시작하겠습니다. 해당논문은 2017 CVPR에서 공개된 논문으로 6DoF 자세추정 분야에서는 아주 아주 아주 유명한 논문입니다. 그럼에도 제가 여태 리뷰한적이 없었던 이유는 저희 연구실에서 김지원 연구원님이 이미 좋은 리뷰를 남기어주셔서 한적이 없었는데요. 그 리뷰는 아래와 같습니다.
그럼에도 불구하고 제가 이번에 다시 리뷰하려는 이유는 이전에 제가 리뷰한 논문들인 [1], [2] 에서 Hough voting 방법, metric 등을 이번에 리뷰할 PoseCNN에서 사용한대로 그대로 사용하였기 때문인데요. 이에 궁금증이 생겨서 직접읽고 리뷰하게되었습니다. 이글을 읽으시는분중에 6DoF에 관심이있고, PoseCNN논문을 읽은적이 없으시다면, 김지원연구원님의 리뷰를 먼저읽고, 제 리뷰를 읽으신 다음 반드시 직접 논문을 읽어보시기 바랍니다.
이미 한번 리뷰했던 논문이므로 최대하 안겹치는 방향으로 리뷰해보겠습니다. 기존 리뷰에서 배경적인면과 방법론을 아주 친절하게 설명하기 때문에 한번 읽고오시면 이해하는데 많은 도움이 되실거라 믿습니다. 그럼 바로 본론으로 들어가겠습니다.
리뷰 시작
먼저, 해당 논문은 6DoF 자세추정에 대한 논문입니다. 기존 연구에서는 clutter, occlusion한 상황에서 성능저하가 발생하였고, 해당 문제들이 challenging한 요소들로 작용했습니다.
이를 극복하기위해 PoseCNN은 Hough voting방식을 도입한 novel한 프레임워크를 사용합니다.
또한, 물체들의 center를 localizing하는 과정에서 2D 이미지에서의 x, y좌표값과 depth정보를 사용합니다. 즉, 카메라로부터 얼마나 떨어져있나를 사용합니다.
이와 더불어 짐벌락문제를 방지하기위한 quaternion representation , symmetric한 objects를 위한 loss및 metric설계를 했습니다.
추가적으로 YCB-Video 라는 데이터셋을 만들고 공개하였고, 해당분야에서 아주 유명한 데이터셋인 OccludedLINEMOD에서 SOTA를 달성했습니다.
이렇듯 contribution만 간략하게 요약해봤는데 상당히 많네요. 아마 이중에 절반만 했어도 accept될 수 있을 정도일거같은데 상당히 많은 contribution이 눈에 돋보이네요.
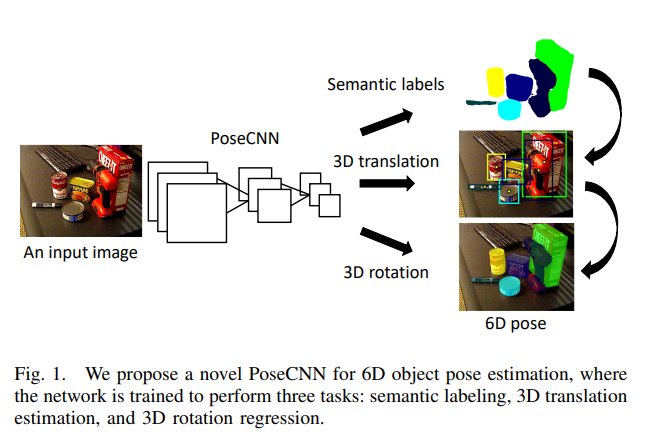
논문의 1페이지의 영상을 같이 살펴봅시다. RGB 이미지를 input으로 받고 PoseCNN 네트워크를 태운 후, 해당 피쳐를 이용하여 segmentation과 3D translation, 3D rotation을 동시에 수행합니다. 즉, 이미지에서 피쳐를 뽑아낸 후 해당 피쳐를 이용하여 픽셀마다 어떠한 label에 속하는지를 예측하고, object의 center를 regression합니다. 그리고 3D rotation을 quaternion representation 방식으로 regression한 후 최종적으로 합쳐진 6D pose를 구합니다.
해당 과정들에서는 엄청 많은 디테일이 생략되어있으며, 이해가 안되는 것이 당연합니다. 그럼 좀 더 자세히 설명해보겠습니다.
쉽게 말해서 결론적으로 우리가 얻고싶은 것은 3가지 입니다.
- 각각의 pixel이 어떠한 class에 속하는지. (label정보)
- 각각 instance들의 center좌표
- 각각 instance들이 어떠한 식으로 rotation이 되어있는지
파이프라인을 본격적으로 분석하기전에 2번에 대해서 일단 좀 알아봅시다.
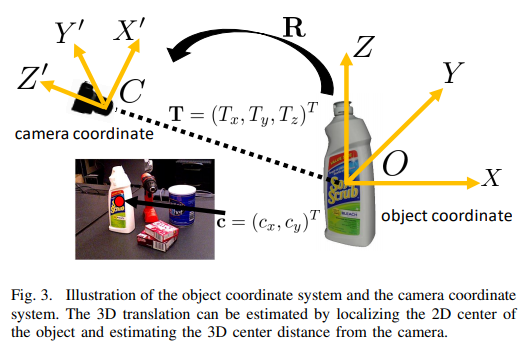
위의 그림을 보시면 우리가 얻고자하는 정보는 camera coordinate상의 Tx, Ty, Tz에 대한 정보입니다. 해당 정보를 바로 regression하여도 되나, 그렇게하면 같은 class를 가지는 여러개의 instance에 대해 다룰 수 없게됩니다.
그래서 사용하는 방법이 먼저, 이미지평면에 투영된 점에서 cx, cy값을 구하고 해당 정보와 더불어 predict한 depth정보(Tz)를 바탕으로 Tx, Ty를 구합니다.
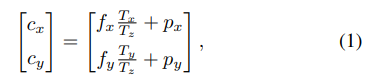
그와 관련된 수식은 위와같으며, 해당 수식에서 p는 principal point를, f는 focal length를 의미합니다. 해당 내용은 위에서 언급한 김지원 연구원님의 리뷰에 들어가시면 좀 더 자세히 나와있습니다.
자 그럼 이제 파이프라인을 살펴봅시다.
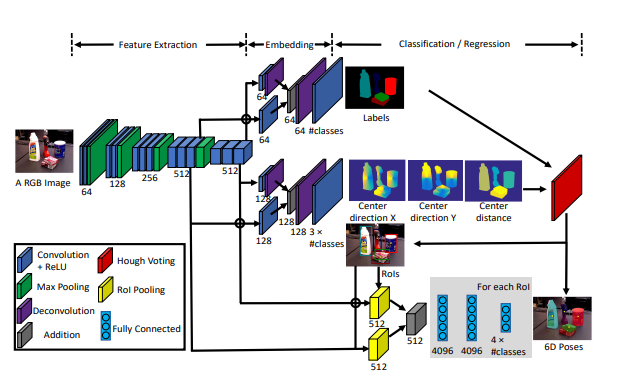
Feature Extraction
먼저 Feature Extraction 과정에서 RGB image가 들어갑니다. 13개의 conv laye와 4개의 max pooling을 거치며 각각의 다른 resolution에서 feature를 뽑아냅니다.
Semantic Segmentation
위에서 뽑아낸 feature 맵 중에서 input이미지의 resolution의 1/8인 곳과 1/16인 곳 2군데에서 branch를 따와서 사용합니다.
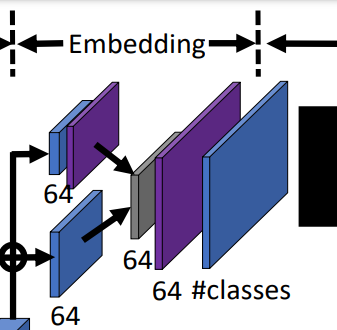
두개의 feature 맵은 각각 512 채널을 가지며, 위의 그림과 같이 서로다른 conv layer에 들어가 64채널로 줄여집니다. 해당 과정에서 1/16의 resolution을 가졌던 feature map은 다시 deconv 과정을 거쳐 원본이미지 resolution의 1/8로 바뀝니다.
그 결과 2개의 feature map은 각각 원본이미지 resoltuion의 1/8로 맞춰지고, 똑같이 64채널을 가지게 됩니다. resolution과 채널이 일치하므로 두개의 feature map은 원소별 연산을 할 수 있게 됩니다. 간단하게 더한 값을 뒤에 따라오는 3개의 conv layer에 input으로 넣어줍니다.
마지막으로 최종적으로 원본 image와 resolution이 같고, 총 label의 갯수만큼을 chanel의 숫자로 가지는 ouput을 내보냅니다. 이를 통해 각각의 pixel마다 어떠한 label에 속하는지에 대한 label정보가 chanel에 담기게 됩니다.
Center Regression
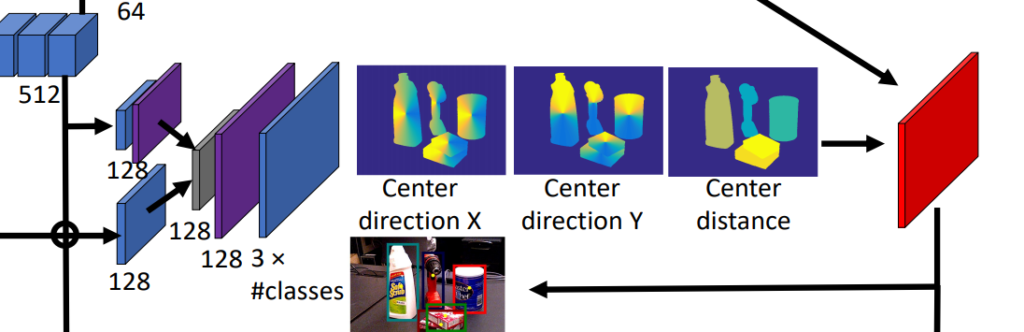
center는 위와같이 regression합니다. 위에서 설명했든 이미지 평면상에서의 instance center의 x,y좌표와 predicted depth를 regression합니다.
위의 sementation에서 설명한것과 매우 유사한 방법으로 서로 다른 resolution이나 같은 chanel을 가지는 두개의 feature map을 뽑아옵니다. 그리고 deconv 과정을 거쳐 두개의 resolution을 맞추어 줍니다. 채널과 resolution이 일치한 두개의 feature map은 더해지고, 3개의 conv layer를 추가적으로 거치며 3*class갯수의 output을 뱉습니다.
즉, 해당 결과가 의미하는 것은, 픽셀마다 어떠한 class에 속하고, 그 해당하는 class에서의 center값으로의 방향벡터와 depth정보 입니다.
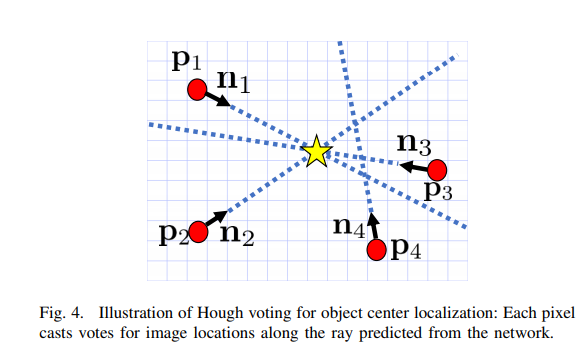
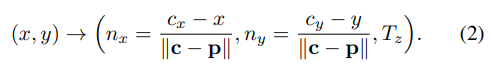
위의 식과 그림은 image평면에서 어떠한 instance가 있으면, 해당 instance의 center값으로의 방향 벡터와 depth 정보를 의미합니다. 즉, 픽셀마다 해당 픽셀이 속한 instance에서의 center값으로의 방향벡터의 x, y 성분을 구하고 해당 값을 크기로 나눠줌으로써 유닛벡터로 만들어준 후, 여기에 추가적으로 depth정보를 구하는 것 입니다. (해당 과정에서 유닛벡터를 사용하는 것은 training과정이 좀 더 수월하게 하기 위함이고, 이는 저자들이 실험적으로 증명하였습니다.)
즉, 픽셀마다 해당 픽셀이 속한 instance센터로의 방향유닛벡터를 구하고, 벡터장을 형성한 후 해당 벡터장을 이용하여 center값을 최종적으로 구하게 됩니다. 그리고 이 때, Hough voting하는 방식을 사용합니다.
해당 과정에서의 Hough voting이란 각각의 유닛방향벡터들을 이용하여 voting을 하는 것 입니다. 무슨소리냐면, 유닛 방향벡터들중 2개를 선택하여 교차하는 지점을 center라고 가정하면, 다양항 유닛방향벡터의 조합을 사용하면 여러개의 center 추정값들이 나올 것 입니다. 이를 통해서 가장 center이 가능성이 높은(voting score가 가장 높은) 곳을 center 값으로 최종적으로 사용하는 것 입니다.
그런데 여기서 같은 class label을 가지는 instance가 여러개 존재하는 경우에는 문제가 발생할 수 있습니다. 아무래도 instance가 여러갠데 같은 class label을 가지면 center값이 혼동이 될 수 있기 때문입니다.
그래서 non-maximum suppression 과정을 voting score에 적용하여 일정 threshold 보다 높은 값을 가지는 inlier를 선정합니다. 즉, instance의 center값에 올바르게 투표를하고있는 pixel들 만을 inlier로 사용한다는 의미입니다.
이 inlier들의 평균 depth값을 최종적인 predicted depth값으로 사용합니다. 위에서 center의 depth정보를 pixel마다 구한 이유도 여기에 있습니다.
그리고 해당 inlier들을 모두 포함 할 수 있는 영역으로 bounding box를 칩니다.
결과적으로 정리해보면, pixel마다 어떠한 class에 속하는지, center점으로의 방향벡터, depth정보를 구했고, 이 정보와 카메라 파라미터를 이용하면 3차원 상에서의 물체의 3d 좌표를 계산 할 수 있습니다.
3D Rotation Regression
위에서의 과정을 거치며 segmentation 정보와 3차원 상에서의 center정보, bounding box 정보를 구했습니다. 이제 rotation 정보만 더해지면 최종적으로 6 DoF pose를 구할 수 있게됩니다. 아무래도 rotation 정보가 제일 구하기 어려운 정보이다보니 위에서 구했던 정보들을 활용합니다.
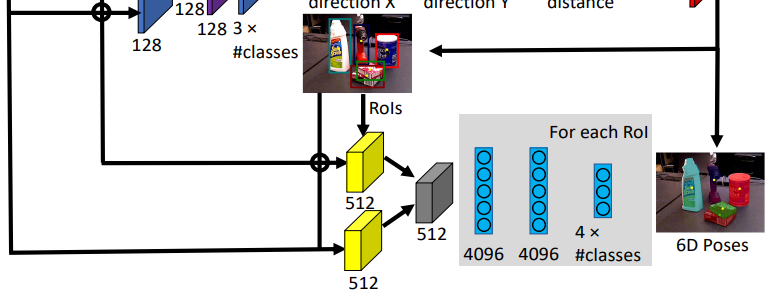
아키텍쳐를 살펴보면, 우리는 이미 3D translation과 bounding box를 구했습니다. 이번 단계에서는 해당 정보들을 이용하여 3D rotation을 구하는 과정에 대해서 다루겠습니다. 먼저 bbox 정보를 이용하여 2개의 RoI pooling layer를 최적화 시킵니다. 그리고 RoI영역만을 crop하고 pool하여 feature를 뽑고 해당 feature를 CNN, FC layer를 통과시켜 최종적인 4*class의갯수 형태의 quaternion representation을 얻게 됩니다. Rotation을 나타내는 방법중 quaternion을 쓴 이유는 짐벌락 현상을 방지하기 위함이며, 김지원 연구원이 쓴 리뷰에서의 동영상을 참고하시기 바랍니다.
아무튼 해당 정보와 위에서 구한 3D translation과 합쳐주면 최종적으로 6DoF pose를 구할 수 있게 됩니다.
이 과정에서 quaternion을 regress하기 위해 직접 설계한 PoseLoss를 사용합니다.
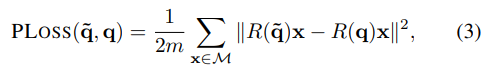
식을 설명하자면, 3D 좌표상에서 point x들을 quaternion을 통해 구한 rotation matrices에 넣었을 때, GT와 predict한 값의 차이의 제곱을 총 point의 개수로 나눈 값 입니다. 즉, 직관적으로 얼마나 pose가 GT와 일치하느냐 라는 의미인데… 이를 이용하면 문제점이 symmetric한 물체에서 불필요하게 패널티를 부여하기 때문에 발생합니다.
예를들어 서로 대칭인 두개의 pose중 한개의 pose로만 예측을 하면 어차피 결과론적으로 답을 맞춘셈인데. 해당 loss대로 최적화를 시키면 2개중에 한개는 틀린값으로 인식을 한다는 것 입니다.
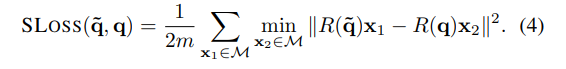
그래서 위와같이 Shape match Loss를 따로 설계하여 예측한 quaternion을 통해 만든 rotation matric와 x1으로 구한 predicted orientation 정보와 GT orientation을 통해 구한 L2거리중에서 가장 작은 값들의 평균을 loss로 사용합니다.
이렇게하면 대칭인 물체더라도 불필요하게 penalize하는 경우를 예방 할 수 있습니다.
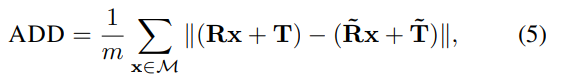
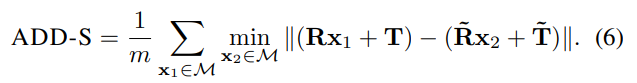
비슷한 원리로 평가매트릭도 symmetric한 물체의 경우 저렇게 나누어서 측정하였습니다. 해당 Notation은 자주쓰이는 notation이고 원리또한 위에서 설계한 SLoss와 비슷하기 때문에 설명은 생략하겠습니다. SLoss를 제대로 이해하셨으면 해당부분도 자연스럽게 이해하셨으리라 생각합니다.
Iterative Closest Point (ICP)
추가적으로, 2d 이미지만이 아닌 depth정보가 주어지면 ICP과정을 통해 성능을 개선할 수 있습니다. 위에서 설명한 방법론에서는 depth까지 모델이 추정을 해야했는데 해당 부분에대한 GT가 주어지면 직관적으로 당연히 성능 개선이 이루어질 것 입니다.
ICP과정에서는 GT depth와 픽셀정보들을 이용해서 3D상에 rendering한 후 해당 픽셀과 depth를 predict한 depth와 픽셀과 비교합니다. 그리고 이를 최적화 시키는 방향으로 refinement를 진행합니다.
좀 더 구체적, 우선 3D상에 rendering한 GT depth정보를 모델을 통해 얻은 semantic label정보를 이용하여 crop합니다. 그리고 해당 부분만을 predict한 결과와 비교를 하는데요. 이 과정을 iterative하게 반복하여 일정 threshold를 넘는 point들을 제거하며 gradient descent방법으로 refinement를 합니다.
이를 통해 좀 더 좋은 성능을 달성 할 수 있습니다.
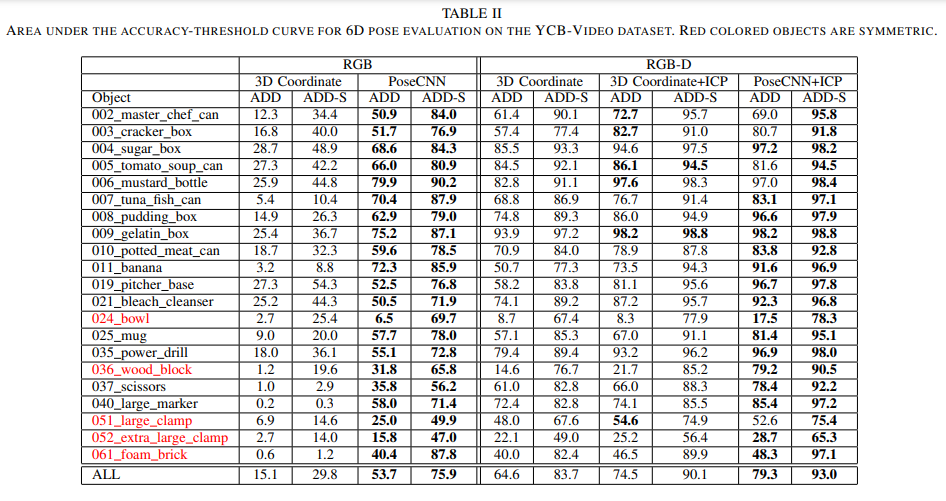
그렇게 자기들이 직접만든 YCB-Video 셋에서 실험을 하여 RGB, RGB-D, ICP 과정등이 추가되며 성능이 개선됨을 보였습니다.
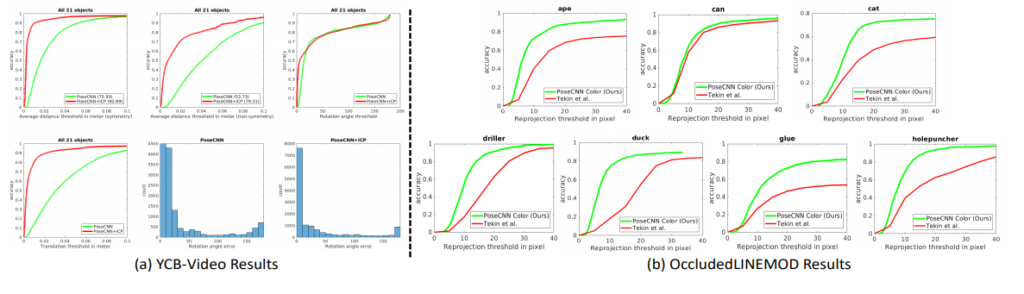
ACC와 threshold간의 그래프를 통해 threshold에 영향을 덜 받고, 최종적인 결과도 더 좋음을 2개의 데이터셋 모두에서 보였네요.
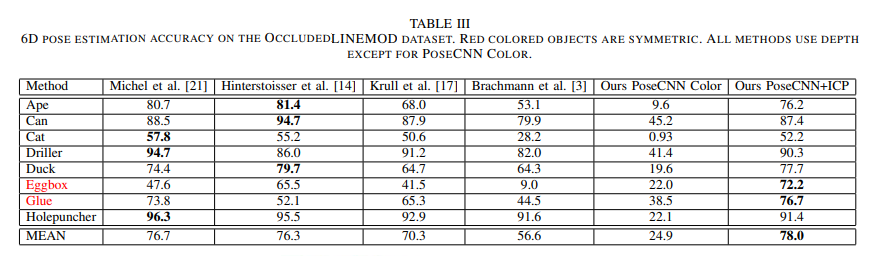
개인적으로 가장 큰 contribution이라 생각하는 Occluded-LINEMOD에서 SOTA를 찍었습니다.

정성적인 결과이구요.
후기
전체적으로 친절하게 잘 쓰여진 논문이지만, 특정부분들에서 설명이 불친절하여 이해하는데 난황을 겪었습니다. 예를들어 SLoss 설명할 때, x1, x2에 대한 notation이 빠져있었고, ICP를 설명할 때 생략된 부분이 너무 많았습니다. 또한, 오타, 용어선정 오류? 가 있는거 같아 이해를 하는 과정에서 혼동이 좀 있었습니다. 그래도 자세한 설명덕분에 앞뒤 문맥을 통해 이해하는데 큰 지장은 없었던거 같습니다. 여전히 ICP과정은 좀 헷갈리긴 합니다.
이와는 별개로 symmetric한 object에 대한 해결책으로 min값을 사용하였는데 해당 부분이 과연 reasonable한가에 대한 의문이 좀 들었습니다. 일단 다른방법이 생각이 나진 않지만… 좀 더 나은 방법이 있지 않을까하는 생각을 해봅니다.(생각이 나면 논문거리 이겠지요? 하하)
Hough voting에 대한 설명중에서 어떠한 식으로 score을 매겼는지에 대한 설명이 빠졌습니다. PixelNet과 같은 방식일련가요… 사실 그 부분이 궁금해서 읽은 느낌도 있었는데 논문엔 없는거 같네요.
결론적으로 해당 논문에서의 핵심은 Hough voting방식이라고 생각합니다. Instance내에서 center를 향하는 unit vetor로 이루어진 벡터장을 만들고 해당 벡터장에서의 center를 voting하는 식으로 접근한게 2017년 당시에는 괜찮은 시도였고, 이를 활용한 후속연구들이 후에도 많이 나왔습니다.
저는 후에 나온 연구들을 먼저 읽었지만, 해당 연구에서 voting하는 방식을 통해 occlusion에 강인한 모델을 설계한 아이디어가 그 때 당시에는 참신했을거 같습니다.
그럼 이상 리뷰 마치겠습니다.