해당 논문은 Style Transfer에서 매우 자주 사용되는 Adaptive Instance Normalization 기법을 처음 제안한 논문으로, AdaIN에 대한 개념을 좀 정리해야할 듯 싶어 리뷰로 작성합니다.
Style Transfer

Style transfer란, 먼저 영상을 content와 style로 구분지을 수 있다는 가정에서부터 시작합니다. 영상에 content와 style을 구분지은 다음, 해당 content에 사용자가 원하는 style을 덮어씌워서 그림1과 같이 새로운 화풍의 그림을 만들자는 것이죠.
그림1에서 A가 원래의 영상이 되는 것이며, B~D는 각각의 다른 영상의 style을 A의 content에 적용시킨 것입니다.
이러한 style transfer는 크게 2가지의 방식이 존재하는데, 다음과 같습니다.
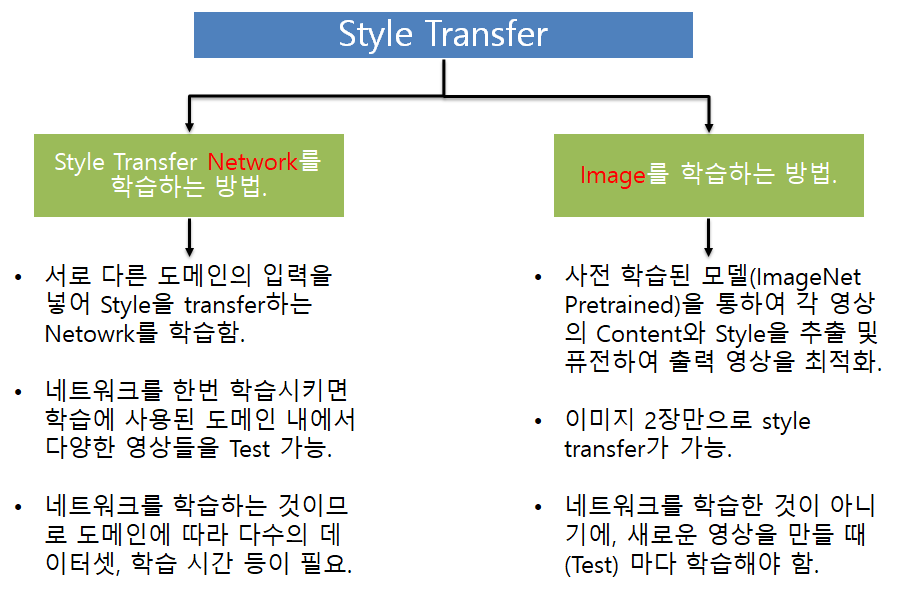
네트워크를 학습시키는 방법은, 저희가 가장 당연하게 생각하듯이 말그대로 스타일을 변경시켜주도록 네트워크를 학습시키는 것입니다. 하지만 네트워크를 학습시키는 것이므로 방대한 양의 학습 데이터가 필요하며, 학습에 사용한 특정 style만을 변환시킬 수 있다는 단점이 존재합니다.
그보다는 우측에 영상을 학습하는 방법이 개인적으로 매우 낯설었는데, 말그대로 사전 학습된 vgg 같은 백본에 content로 사용할 영상과 style로 사용할 영상을 각각 넣어서, output image를 직접 학습하는 것입니다.
이러한 방식은 content와 style 각각 1장씩 총 2장의 영상만으로 새로운 스타일의 영상을 만들 수 있다는 장점이 존재하지만, inference 시 모델에 입력을 넣어 모델을 타고 들어가 출력이 나오는 방식이 아니라, 매번 영상을 새로 학습하는 방법이기 때문에 단점이 될 수 있습니다.
Adaptive Instance Normalization 논문에서는 이러한 style transfer 각각의 방법론들이 모두 명확한 단점을 가지고 있음을 지적하며, 해당 논문에서는 Adaptive Instance Normalization(AdaIN)을 통하여 훨씬 빠르게 새로운 스타일의 영상을 학습시켰다고 합니다.
해당 논문은 Batch normalization, instance normalization, conditional instance normalization, adaptive instance normalization 순으로 설명을 진행하므로, 해당 리뷰에서도 이러한 흐름에 맞추어 글을 작성해보겠습니다. 또한 normalization 표현이 너무 길어서 짧게 norm으로 줄여서 말하겠습니다.
Batch normalization
Batch norm은 다 아시다시피, feature의 통계치를 정규화함으로써 feed-forward 형식의 네트워크가 더 빠르고 쉽게 학습되도록 하는 역할을 합니다.
이러한 BN layer은 기존에 분류나 검출 등 discriminative network가 학습하는 것에 초점을 두고 설계되었지만, 영상을 생성하는 네트워크에서도 효과적임을 보였다고 합니다.
주어진 입력 배치 x \in \mathbb{R}^{N \times C \times H \times W} 에 대하여 BN는 각각의 feature 채널의 평균과 표준편차를 아래와 같이 정규화합니다.
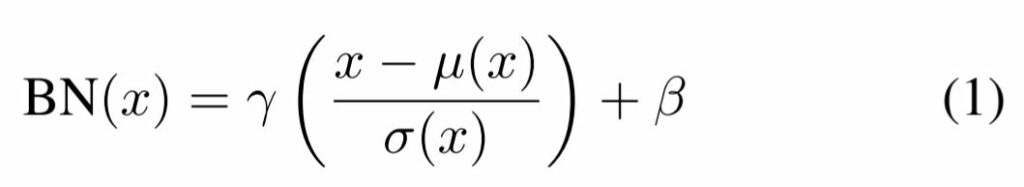
여기서 \gamma, \beta \in \mathbb{R}^{C} 는 데이터로부터 학습되는 affine parameter에 해당되며 [/latex] \mu(x), \sigma(x) \in \mathbb{R}^{C}[/latex]는 각각의 feature channel에 대하여 개별적으로 전체 batch에 대한 평균과 표준편차를 의미합니다.
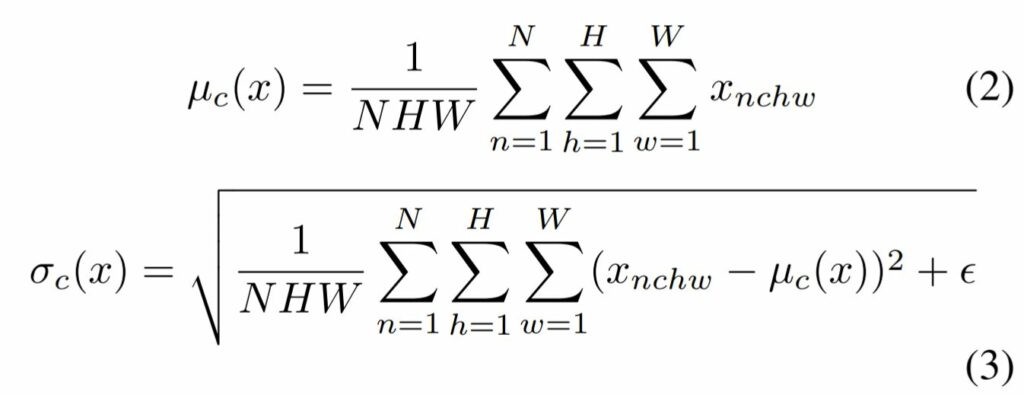
위에 수식과 같이 전체 배치 사이즈에 대한 feature의 평균과 분산을 채널별로 각각 계산했다는 것이죠.
Instance normalization
이전의 방법론들은 위에서 설명한 batch norm을 사용하여 네트워크를 학습시켰습니다. 하지만 Ulyanov 라는 사람이 BN layer를 IN layer로 바꾸었을 때 더 좋은 성능을 보였다고 합니다.
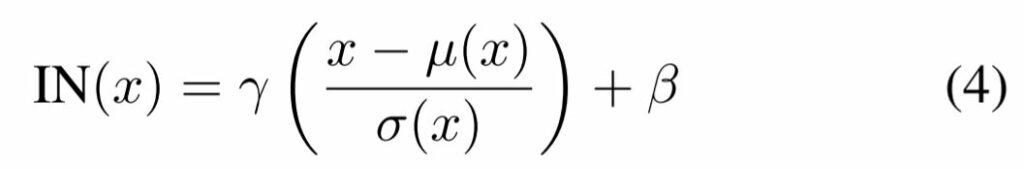
Instance norm이란 말그대로 하나의 입력 데이터에 대한 각 채널의 평균과 표준편차로 정규화를 하는 것입니다.
그래서 평균과 표준편차를 계산할 때도 수식 (2), (3)과 달리 N에 대한 식이 없는 것을 확인할 수 있죠.
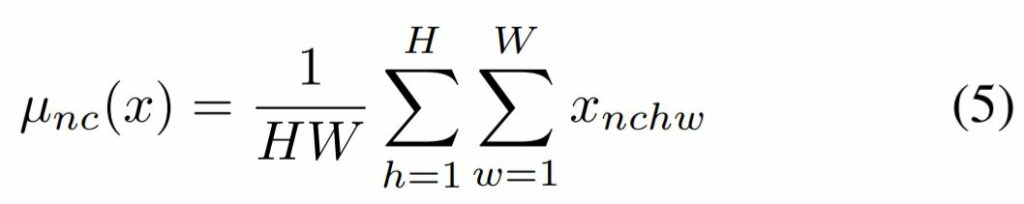
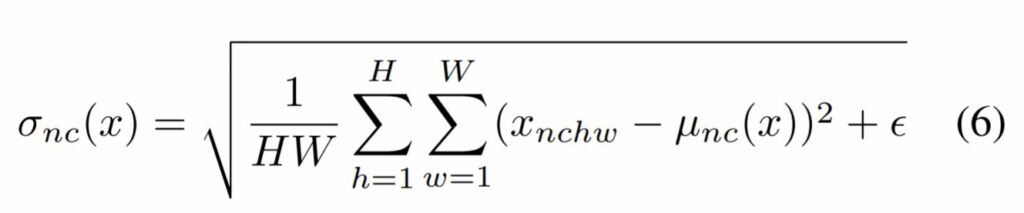
또한 IN layer는 BN layer와 다르게, train과 test에 별 차이 없이 진행하면 되지만, BN layer는 inference 동안에 batch의 평균과 분산을 계산할 수 없으므로, 학습 때 사용했던 이동 평균들과 분산들의 평균과 분산을 고정하여 사용한다는 차이가 존재합니다.
Conditional Instnace normalization
Dumoulin이라는 사람은 Instance norm에서 사용하던 학습 파라미터 \gamma, \beta 대신에, 각각의 스타일 s에 대한 \gamma ^{s}, \beta ^{s} 파라미터들의 집합들을 학습하는 레이어를 제안했습니다.
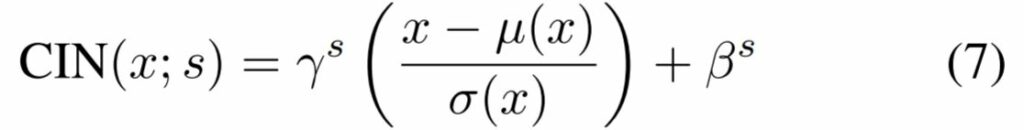
conditional instance norm은 학습하는 동안에, 전체 스타일 이미지들 중 고정된 부분 집합으로부터 랜덤하게 스타일 영상 하나를 골라서 같이 학습하는 것을 의미합니다.(해당 논문에서는 1~32개의 스타일 원소가 들어있는 부분 집합을 사용했다고 합니다.
컨텐츠 영상은 style transfer network를 통과하는데 이 때, CIN layer를 통과하면서 새로운 style의 \gamma ^{s}, \beta ^{s}가 적용되어 정규화 되는 것입니다.
놀랍게도 네트워크가 동일한 컨볼루션 파라미터를 사용하지만 IN layer 안에 존재하는 afiine parameter를 다르게 적용한 것만으로 완전히 다른 스타일의 영상을 네트워크가 만들 수 있게끔 해주었습니다.
하지만 CIN layer를 사용하는 네트워크는 CIN layer를 사용하지 않는 네트워크와 비교하였을 때 2FS 개의 추가적인 학습 파라미터가 필요로 합니다.
여기서 F는 네트워크의 전체 feature map 개수를 의미하며, S는 부분집합의 최대 스타일 개수(위에서 말한 32개)를 의미합니다.
즉 변화시키고자 하는 스타일의 수가 늘어날 때마다 추가적으로 학습시켜야할 파라미터의 수도 선형적으로 증가하기 때문에, 방대한 양의 스타일을 학습시키기에는 어려움이 존재하며, \gamma ^{s}, \beta ^{s} 가 학습을 시켜야 하는 파라미터이기 때문에, 새로운 스타일에 대해서는 네트워크를 재학습시켜야 한다는 단점이 존재합니다.
Interpreting Instance normalization
그렇다면, 이 Instance norm은 왜 style transfer 네트워크에서 좋은 효과를 보이는 것일까요? Instance norm을 어떻게 해석하면 좋을지에 대해 CIN lyaer를 제안한 ULyanov는 IN이 컨텐츠 이미지의 contrast에 불변성을 가지고 있다고 얘기합니다.
하지만 AdaIN 논문의 저자는, IN layer가 feature space에서 연산을 수행하기 때문에, 단순히 픽셀 공간에서의 contrast normalization으로 보는 것 보다 더 심오한 영향력이 있을 것이라고 판단하였습니다.
즉 논문의 저자는, instnace normalization이 feature의 통계치(평균과 분산)을 정규화함으로써, style normalization을 수행한다고 주장합니다.
이러한 주장을 증명하기 위해, 논문에서는 한가지 실험을 진행합니다. 바로 texture network에 IN layer와 BN layer로 각각 적용하여 단일 스타일 변환 작업을 수행한 것이죠.
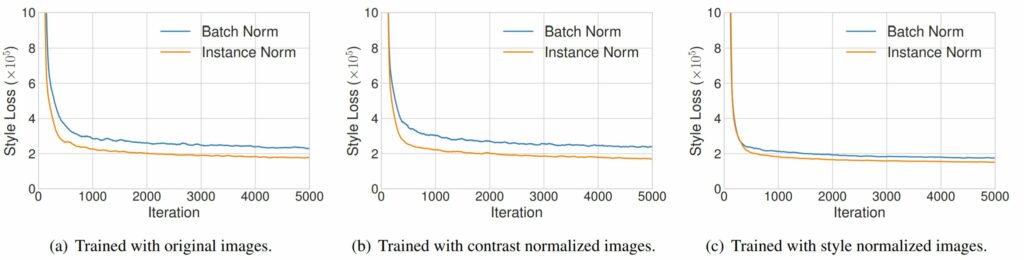
해당 실험 내에서도 크게 3가지로 나눌 수 있는데, 첫번째는 원본 영상 그대로를 입력으로 하여 학습시킨 경우, 두번째는 모든 학습 영상들에 대하여 luminance 채널에 histogram equalization을 수행함으로써 contrast normalization을 한 경우, 마지막으로 사전 학습된 style transfer network를 사용하여 모든 학습 영상들을 동일한 style로 변환시킨 다음, style transfer를 학습시켰습니다.
이 실험들에 대한 결과가 그림2에 (a),(b),(c)로 각각 나타나있습니다. 먼저 원본 영상으로 학습할 때와, histogram equalization으로 content를 정규화한 영상으로 학습시켰을 때 모두 IN lyaer가 BN layer보다 더 빠르게 수렴되는 모습을 보입니다.
만약 ULyanov의 말대로, IN이 content image의 contrast에 강인한 특성을 보여서 학습에 더 좋은 영향을 끼친 것이라면, content image의 contrast를 정규화하여 학습시킨 (b) 실험에서는 BN과 IN의 수렴속도 차이가 크지 않아야 할 것입니다.
하지만 IN이 더 빠르게 수렴하는 것을 보아, content image의 contrast에 대한 강인함을 보이는 것은 아닌 것으로 판단됩니다.
그렇다면 논문의 저자가 주장한대로 IN이 style normalization을 수행하는 것일까요? 그림2의 (c)를 살펴보시면, IN과 BN의 수렴 속도 차이가 그리 크지 않는 것을 확인할 수 있습니다.
즉 BN과 달리 IN은 style normalization 역할을 수행하기 때문에, 학습에 사용될 영상들이 모두 style normalization된 상태라면 학습의 수렴 속도가 별 차이가 없는 것이지요.
BN layer는 그럼 왜 IN보다 수렴 속도가 더 느리고 좋지 못할까요? BN의 경우 single style을 중심으로 배치들의 feature들을 정규화합니다. 하지만 배치 내 각각의 영상들은 모두 다른 스타일을 가지고 있으며, 우리는 모든 영상이 하나의 동일한 style로 변환되기를 원하는 것이 아니기 때문에, feed-forward style transfer 방법론에서 BN은 효과적이지 못한 것입니다.
하지만 IN은 목표 스타일에 맞게 개개인의 샘플 스타일을 정규화시킬 수 있으며, 이덕분에 학습하는 동안에 원본 스타일의 정보는 버리고 컨텐츠 합성에 초점을 맞출 수 있다고 합니다.
Adaptive Instance Normalization
IN layer가 어파인 파라미터들을 통해 특정한 단일 스타일로 입력을 잘 정규화 시킨다면, adaptive한 어파인 변환을 적용함으로써 처음 본 스타일에 대해서도 style transfer가 가능하지 않을까? 라는 물음에서 AdaIN이 시작합니다.
AdaIN은 content input x와 style input y를 입력으로 하며, x의 채널별 평균과 분산을 y에 알맞게 매칭한다고 합니다. BN, IN, CIN과 달리, AdaIN은 학습에 필요한 affine parameter가 전혀 존재하지 않습니다.
대신, 스타일 입력에 따라 affine 파라미터가 새롭게 적응되어 계산됩니다.
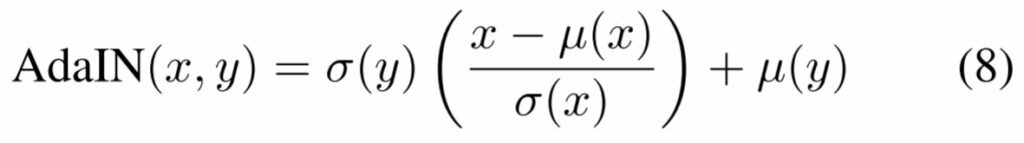
위에 수식을 확인해보시면, 기존에 Instance Normalization에서 사용한 affine parameter들이 각각 스타일 영상의 표준편차와 평균으로 적용된 모습입니다.
즉 이러한 통계치(평균과 표준편차)가 영상의 스타일을 충분히 표현할 수 있다는 것을 확인하여 AdaIN을 설계한 것이죠. 학습 때 전혀 보지 못한 style이라고 하더라도, 해당 스타일 입력이 인코더를 타고 나온 feature에 대하여 평균과 표준편차만을 적용시켜주면, 새로운 스타일을 입힐 수 있는 것입니다.
Architecture

해당 논문의 구조는 영상을 학습하는 기존 style transfer 방법론들과 매우 유사합니다. Content image와 style image를 각각 pre-trained vgg 인코더에 입력으로 넣은 후, 디코더를 통해 출력으로 나온 영상을 다시 인코더에 넣어 처음 입력 영상과 만들어진 영상의 style feature와 content feature 각각의 loss를 계산하는 방식이죠.
하지만 한가지 다른 점은, 이 논문에서는 출력 영상을 학습하는 것이 아니라, 디코더를 학습하는 네트워크 훈련 방식입니다. 이 방법론은 네트워크 기반 방법론의 장점과 이미지 기반 방법론의 장점을 모두 취득한 방법론인데 보다 자세한 설명은 아래 실험 섹션에서 설명하고자 합니다.
아무튼 다시 그림3으로 돌아와서, 각각의 컨텐츠 입력과 스타일 입력을 인코더에 태운 후, AdaIN을 적용하여 스타일과 컨텐츠를 퓨전시킵니다. 그렇게 해서 디코더를 태우면 새로운 스타일이 입힌 영상이 탄생하는 것이죠.
Loss 함수도 매우 간단한데, content loss와 style loss 단 두개만 존재합니다. 먼저 content loss는 다음과 같은 수식으로 나타납니다.

여기서 g, f, t가 무엇이냐 하면, 각각 디코더, 인코더, AdaIN의 결과값 을 의미합니다. 그러므로 식(12)[논문에 있는 수식을 바로 가져오다보니 9~11은 생략됐습니다.]가 의미하는 바는 AdaIN(f(content), f(style))의 결과값인 t와, 이 t를 디코더를 태워서 새로운 아웃풋으로 만들고, 이 아웃풋을 다시 인코더를 태워서 새로운 컨텐츠 feature로 만든 값에 L2 loss를 계산하겠다는 의미입니다. 즉 만들어진 영상의 컨텐츠와 AdaIN으로 융합된 피처의 컨텐츠는 같다라는 의미죠?
그렇다면 왜 AdaIN을 적용하기 전인 f(c)와 비교 안하고, AdaIN이 적용된 t와 비교를 하는 것일까요? 그 이유는 일단 이렇게 하면 조금 더 빠르게 학습이 수렴되었다고 하는데, 이는 결국 새로운 스타일이 적용된 인코딩 feature의 컨텐츠 성분이 디코딩을 거친 후에도 컨텐츠가 잘 유지되길 바라는 목적과 부합했기 때문이라고 합니다.

다음은 style loss입니다. style loss는 조금 더 복잡해보이지만 사실은 매우 간단합니다. 위에서 style image가 인코더를 지나면서 나오는 피쳐맵들의 통계치들(평균과 표준편차)들이 스타일의 특성을 잘 나타낸다고 했었죠? 즉 원래 스타일 이미지와 생성된 이미지를 각각 인코더를 태워서 구한 feature map을 각각 평균과 표준편차를 구해서 그 둘을 L2 loss로 비교했을 뿐입니다.

그래서 전체 loss는 스타일과 컨텐츠 loss를 각각 더해주면 되는 것으로 끝이 납니다.
Experiments
아무래도 style transfer논문은 새로운 style을 입히는 것이 목적이다 보니, GT 이미지가 거의 없습니다. 그래서 해당 논문에서는 정성적인 결과로 스타일이 잘 변환되었는지를 보였으며, 정량적으로는 모델의 속도와 표현할 수 있는 스타일의 수를 중심으로 결과를 보여줍니다.


위에는 정성적 결과를 나타낸 것입니다. 이 논문에서 가장 강조하는 것은 자신들이 네트워크를 학습하는 네트워크 기반 방법론이지만, 학습 때 한번도 보지 못한 스타일에 대해서도 잘 변환을 시킨다는 점인데요, 위에 정성적 결과 역시 학습 때 한번도 보지 못한 스타일도 잘 적용시키는 모습을 볼 수 있습니다.
그 외에 4번째 컬럼과 6번째 컬럼은 이미지 학습 기반 방법론이며, 5번째 방법론은 네트워크 학습 기반 방법론입니다.
Speed

위에 표는, 해당 방법론에서 가장 자랑하는? 표로 자신들의 방법론과 다른 방법론들이 스타일 변환을 수행할 때 필요한 인퍼런스 시간과 스타일의 가짓수를 나타낸 것입니다.
보시면 Gatys et al과 Chen and Schmidt는 이미지 학습 기반 방법론이며, Ulyanov et al, Dumoulin et al은 네트워크 학습 기반 방법론들 입니다.
이 표를 보시면 이미지 학습 기반과 네트워크 학습 기반 방법론의 차이를 한눈에 확인하실 수 있는데, 확실히 영상을 학습하는 방법론들은 학습이 곧 inference이므로, 네트워크 기반 방법론들에 비해 시간이 오래 걸리는 것을 확인할 수 있습니다.
하지만 style을 표현할 수 있는 가짓수는 입력으로 주어지는 영상의 스타일만 다양하면 그에 맞게 무한대로 표현할 수 있지만, 네트워크 기반 방법론들은 학습 때 한번도 보지 못한 스타일들을 표현할 수 없다는 단점이 존재하죠.
하지만 논문에서 제안하는 AdaIN은 학습 때 한번도 보지 못한 style에 대해서도 해당 style의 통계치를 이용하여 스타일을 변환시키기 때문에, 무한대의 스타일을 표현할 수 있으며, 네트워크 기반 방법론이기에 inference 시간 역시도 여타 다른 네트워크 기반 방법론들과 유사하다는 것을 확인할 수 있습니다.
Additional experiments
추가 연구에서는 디코더에 normaliation(BN, IN)을 적용하면 성능에 어떤 영향을 미치는가 에 대해서 추가로 실험한 내용입니다.


위에 실험은 총 4가지의 가정으로 진행되었습니다.
- Enc-AdaIN-Dec : 논문에서 최종적으로 제안하는 방법으로, AdaIN을 적용하고 그 외에는 어떠한 normalization을 사용하지 않는 방법.
- Enc-Concat-Dec : AdaIN 대신에 content feature와 style feature를 단순히 concat한 방법.
- Enc-AdaIN-BNDec : Decoder 네트워크에 Batch Normalization layer가 추가된 방법.
- Enc-AdaIN-INDec : Decoder 네트워크에 Instance Normalization layer가 추가된 방법.
일단 그림5 (d)를 살펴보시면, 무언가 한 가운데 오리가 보이는 것을 확인할 수 있습니다. 이는 스타일 영상인 (a)의 컨텐츠 요소인 오리가 사라지지 않고 남아있는 것을 의미합니다. 즉 단순히 content와 style feature를 concat하게 되면, style image에서 content와 style을 잘 분리하지 못함을 의미합니다.
이는 그림6의 그래프를 통해서도 알 수 있는데, Concat방식의 컨텐츠 loss를 나타내는 주황색 점선 라인이 다른 방법론들에 비해 더 큰 값을 가진 상태로 수렴된 것을 확인할 수 있습니다. 즉 컨텐츠가 잘 학습이 안되더라~ 라는 것이죠.
또한 디코더에 BN/IN 을 추가하였을 때 모두 성능이 좋지 못한 것을 정성적으로 확인할 수 있는데, 특히 IN을 적용한 결과가 많이 좋지 못한 것을 확인할 수 있습니다. 그림6에서 IN layer가 추가된 방법론의 스타일 loss를 나타내는 붉은색 라인도 매우 높은 지점에서 더이상 수렴을 안하는 것을 보니 스타일 학습이 잘 안되는 것으로 보입니다.
이는 Instance normalization layer가 출력값을 한가지 스타일로만 정규화하려는 경향성이 있기에, 수많은 스타일을 변환시키려고 하는 style transfer 입장과는 매우 반대된다는 것을 의미합니다.
요약하자면 해당 논문은 Normalization 방법론들이 영상 생성을 하는 관점에서 어떻게 작동하는지를 실험하였습니다. 이를 통해 영상의 style을 나타내는 요소를 해당 영상의 평균과 표준편차와 같은 통계치임을 보였으며, 이를 활용하여 학습 때 한번도 보지 못한 스타일에 대해서도 네트워크가 강인하게 스타일 변환을 시키는 방법론을 제안한 것이죠.
모델을 학습시키는데만 익숙하다보니 이미지를 학습한다…라는 개념이 신박하네요. 그리고 디코더를 학습하는 네트워크 훈련 방식이란 것도 그렇구요. 반대로 실제로찍은 이미지를 style로 넣고 content 이미지에는 사람이 그린 그림을 넣으면 사람이 그린 그림도 실제 이미지와 같은 style을 가질까요? 갑자기 궁금해지네요.