segmentation을 하면서 PSPNet을 이용해서 해당 논문에 대해 리뷰하게 되었습니다.
Abstract
pyramid scene parsing network (PSPNet)인 pyramid pooling module을 통해 다양한 영역에서 나온 cotext 정보를 이용한다. PSPNet을 이용하면 픽셀 단위의 예측에서 좋은 성능을 낸다.
Introduction
- Scene parsing은 그 scene에 대해 complete understanding을 제공한다. label, location, 각 요소의 형태를 예측한다.
- scene parsing의 어려움은 scene과 label의 다양성과 관련있다. LMO dataset _ 33분류, 2688장 / PASCAL VOC semantic segmentation & PASCAL context dataset _ 의자-소파, 말-소 등과 같이 맥락이 유사한 라벨들이 포함 / ADE20K dataset _ 복잡한 이미지 (Fig 1)

- scene parsing 방식의 SOTA는 FCN을 이용하는 것인데 FCN은 global scene category 의 단서를 이용할 수 없기 때문에 유사한 객체들 사이에서 오류가 많이 발생한다. 보트와 차가 유사하게 생겼을 때, 강 주변에서 보트 창고라는 context를 di알면 보트라고 제대로 예측할 수 있을 것이다.
- pixel-level의 feature을 늘려 local, global clue를 함께 마지막 예측에 사용하고, deeply supervised loss를 이용하는 최적화 전략을 제안한다.
- Contributions
- FCN 기반 pixel 예측에 내장된 pyramid scene parsing network 제안(어려운 풍경 context features를 포함하기 위해)
- deeply supervised loss기반의 deep ResNet에 효과적인 최적화 방식 개발
- semantic segmentation 분야의SOTA를 달성했고 implementation에서 자세하게 설명하고있다.
Pyramid Scene Parsing Network
FCN 방법의 대표적 문제를 분석한 결과 전체 global contextg 정보를 제공하는 PSPNet을 제안하게 되었다. 이 방법은 open-vocabulary object and stuff (길, 하늘과 같이 하나로 구분하기 어려운 것) identification을 항상시킨다.
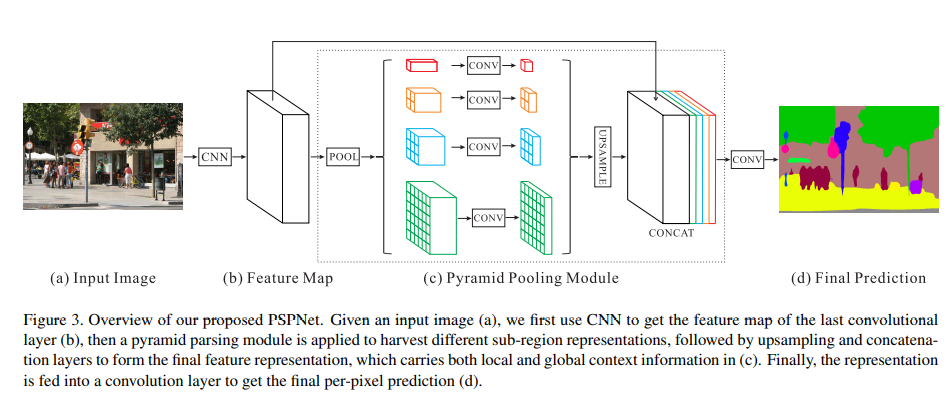
1. Important observations
FCN을 분석한 결과 찾은 issue
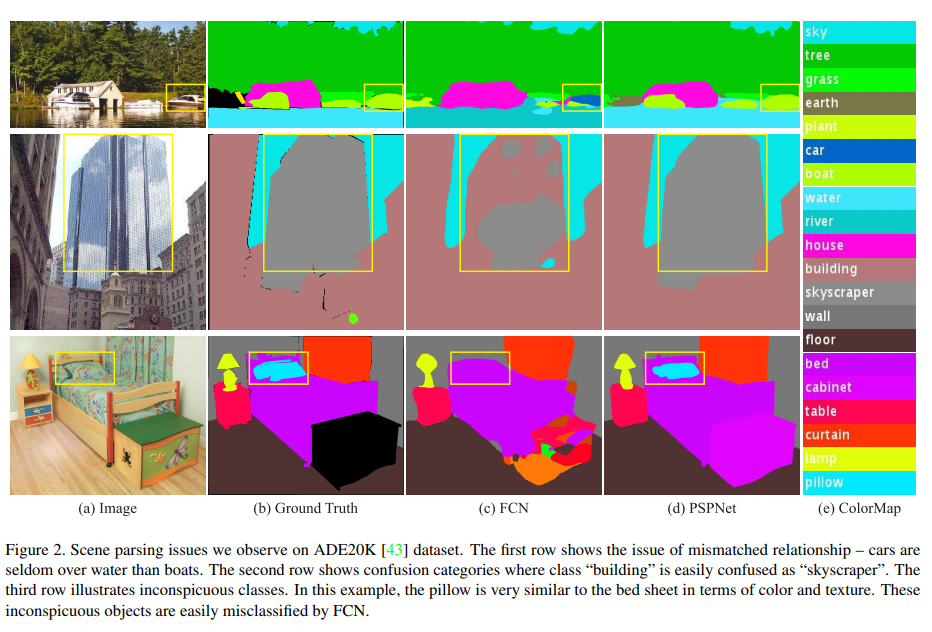
- Mismatched relationship : 장면을 이해하기 위해 context reslationship이 중요한데 첫번째 행의 보트를 차라 예측한 것은 일반적으로 강 위에는 차가 아닌 보트가 있는데 맥락에 대한 이해 부족으로 비슷한 외관인 차라 한 것
- Confusion Categories : field-earth, mountain-hill, wall-house-building-skyscraper 등 유사한 것들이 하나의 카테고리가 아닌 구분되어있음. 두번째 행의 결과를 제외하여 위의 결과처럼 skyscraper를 building과 skyscraper 둘 다로 구분하지 않도록 해야함. 이 문제는 category들의 관계를 이용하면 해결할 수 있다. (그냥 카테고리로 만든다는 건지, 아니면 이것도 맥락을 파악하겠다는 이야기인지 모르겠다. 사실 저 유사한 카테고리들은 관계를 본다고 해서 해결이 될지 모르겠다. 유사한 카테고리의 경우 주변 맥락도 비슷한 경우가 많을텐데..)
- Inconspicuous(이목을 끌지 못하는) classes : 너무 작거나 큰 object를 잘 예측하지 못할 수 있다. 이를 해결하기 위해 해당 객체가 포함된 sub-region에 attention해야한다.
2. Pyramid Pooling Module
실험적으로 확인한 결과 receptive field가 이론보다 작았다. Global average pooling을 이용하는데 바로 적용하여 하나의 vector로 만드는 것은 spatial relation을 잃어버리고 불명확함을 야기할 수 있다. 따라서 receptive field의 sub-region을 fuse하는 것이 더 좋다.
hierarchical globa prior_ 다른 크기와 다양한 다른 sub-regions 정보를 이용하는 hierarchical global prior을 제안한다. 이것을 Pyramid pooling module이라 한다. pyramid pooling layer를 통해 나온 각각의 결과에 convolution layer를 거쳐 1 x w x h의 결과를 얻고, bilinear interpolation을 통해 upsampling한 뒤 concat해준다. (이때 pyramid의 level과 크기 등은 pyramid에 들어오는 feature의 크기에 따라 다양할 수 있다.)
3. Network Architecture
사전학습 된 Resnet(dilated network strategy를 이용해 늘어난 )을 이용하여 feature map을 늘렸다. 4-level의 pyramid를 이용하여 이미지의 작은 부분부터 전체 까지 다 볼 수 있다. 4-level의 결과와 original feature를 concat한다.
original dilated FCN과비교했을 때 연산량은 크게 증가하지 않았다. (증가하기는 했다는 것) end-to-end로학습되고, global pyramid pooling module과 FCN feature는 동시에 최적화가 된다.(같이 학습이 된다는 것)
Deep Supervision for ResNet-Based FCN
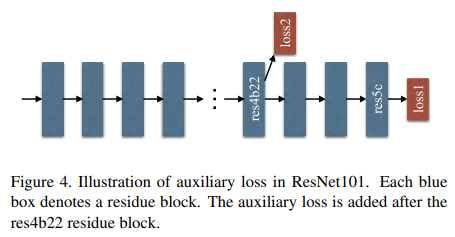
depth 증가할 수록 optimization difficulty가 늘어난다. 뒷부분에서 찌꺼기 정보를 학습하기 때문에. 따라서 순서를 바꿔서 뒷단에서 먼저 loss를 구하고(main) 중간의 res4b22에서 loss2(help)를 구해 학습한다. 이 auxiliary loss는 test에서는 사용하지 않는다.
Experiments
3가지 dataset을 이용할 것이다. 실험에 관한 자세한 설명이 5.1에 설명되어있다. 어떤 학습 방법을 이용하고 무엇을 쓸지 등. (원복하기 아주 친절한 논문이다)
적당히 큰 “cropsize”는 좋은 성능을 산출하고, batch normalization의 “batchsize”가 굉장히 중요하다는 것을 실험하면서 알았다.
1. ImageNet Scene Parsing Challenge 2016
ADE20K dataset이용.150개의 클래스와 많은 1038개의 라벨이 붙은 이미지를 포함해 다양한 장면을 가지고 있다. (=복잡하다!) 20K개의 학습, 2K개의 검증,3K개의 테스트 데이터로 나눠져있다. 또한 object와 stuff에 대해 각각 라벨이 되어있다. 평가는 pixel-wise accuracy(Pixel Acc.), mean of class-wise intersection over union(Mean IoU)를 사용했다.
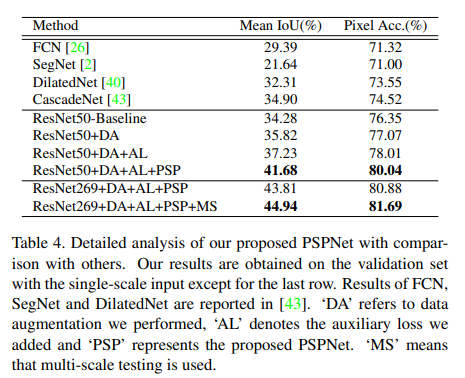
- PSPNet을 제외하고 기존 ResNet에 위의 표처럼 여러 조합을 실험했고, 최고 성능인 경우를 찾아 baseline으로 정했다.
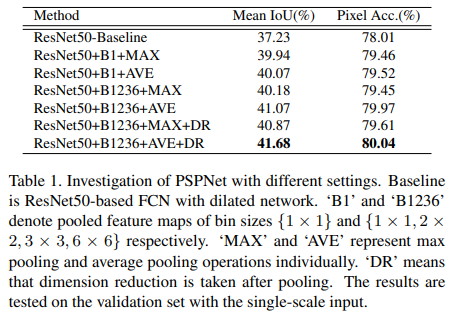
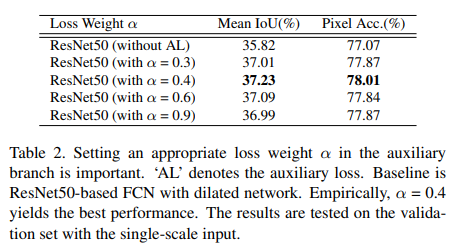
- 제안했던 loss를 추가하고 weight을 0.4로 주었을 때 가장 성능이 향상되었다. 더 깊은 신경망에서 성능이 더 오를 것으로 예상한다.
- pre-trained PreNet의 깊이가 {50, 101, 152, 269}인 4가지 경우를 실험해보았고 depth가 증가할 수록 성능이 오르는 것을 확인했다.
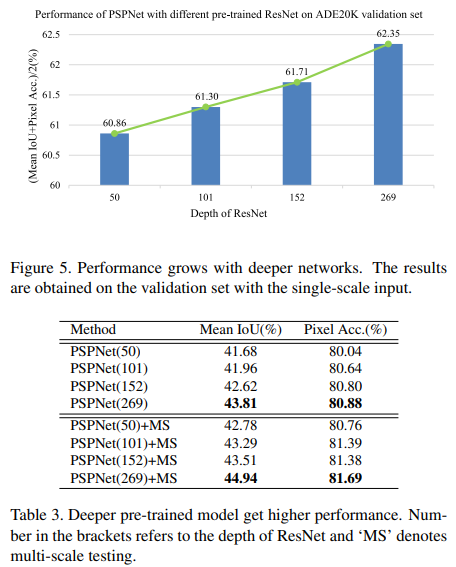
- PSPNet을 이용한 결과 baseline보다 성능이 향상되었다. 그리고 거기에 multi-scale testing을 적용했더니 성능이 더 올랐다.
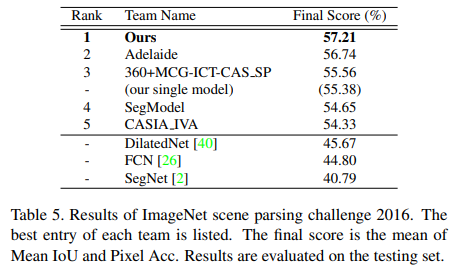
- ImageNet scene parsing challenge 2016에서 1등함.
2. PASCAL VOC 2012
배경 포함 20개의 label을 가진 PASCAL VOC 2012 segmentation dataset을 이용했다. augmentated data를 이용해 10582개의 학습, 1449개의 검증, 1456개의 테스트 데이터를 이용했다.
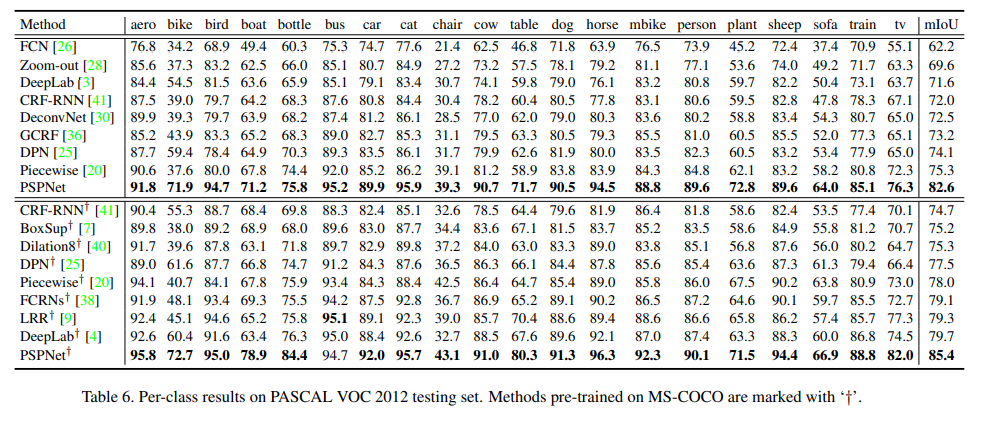
MC-COCO dataset에서 pre-training을 사용했을 때와 사용하지 않았을 때 모두 좋은 성능을 얻었다.

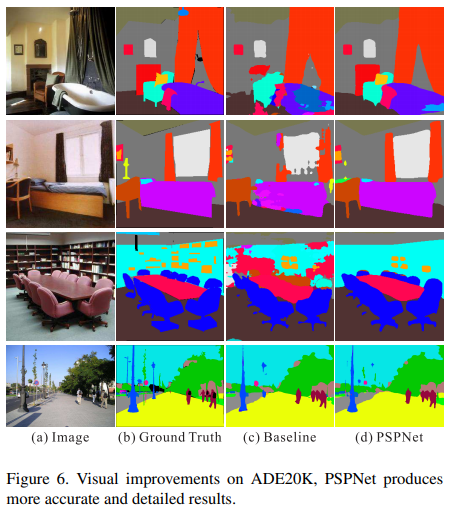
figure 7 설명 _baseline은 소를 말과 개로도 구분했음. 비행기와 테이블을 baseline과 다르게 잘 찾았음.(baseline은 특정 놓친 부분을) 작은 크기의 사람, 병, 식물에 대해서도 baseline과 비교했을 때 잘 찾았음. 추가적 모델과의 비교는 다음 그림을 참고

3. Cityscapes
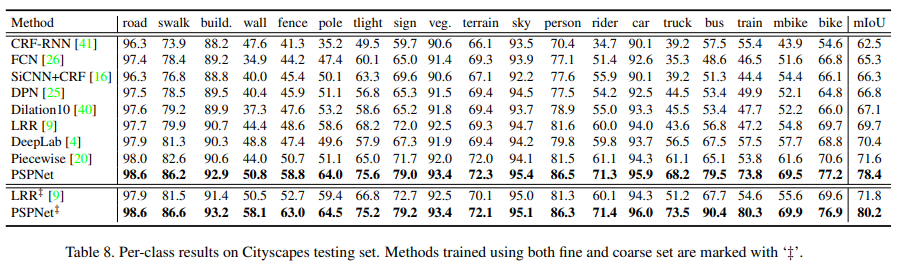
50개의 도시에서 다른 계절에 찍은 이미지로 2975개의 학습, 500개의 검증, 1525개의 테스트 데이터가 있다. stuff와 object로 이뤄진 19개의 라벨이 있다. 또한 20,000개의 coarse data를 제공해 fine data와 함께 이용할지 fine 데이터만 이용할 지 고를 수 있다. fine과 coarse data를 같이 이용한 경우 ‘‡’표시.
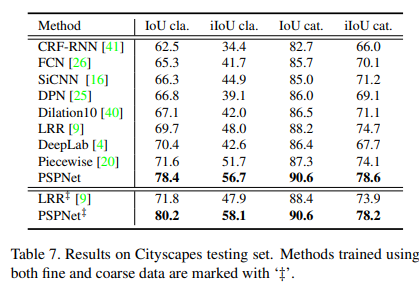
fine과 coarse data를 같이 이용하면 더 좋은 성능을 얻을 수 있다.

Concluding Remarks
global pyramid pooling feature은 contextual 정보를 추가로 제공하므로 해당 scene에 대해 더 잘 이해할 수 있다. 또한 deeply supervised optimization방식을 제공한다.
- 해당 논문을 PSPNet을 제안하고 loss를 추가하여 학습을 도울 것을 제안한다.
- 관련 근거를 뒷받침하기 위해 여러 조건에 대해 실험하고 성능을 리포팅했다. 또한 실험에 사용한 구체적인 파라미터를 알려주고 있어 원복하기 좋은 친절한 논문인 것 같다.
- auxiliary loss를 잘 이해하지 못해 그렇게 느끼는 것일 수도 있지만 설명이 부족한 것 같다….
- 그리고 이 논문에서 FCN의 issue에 대해 분석할 때 Confusion Categories 에 대해 이야기 했는데, 도로에 차와 버스, 길가의 벽과 건물 등과 같이 confusion category에 대해서는 주변의 맥락을 파악한다고 해서 구분을 잘 할 수 있는 것이 아니지 않을까?라는 생각이 들었다.
깃허브 링크: hszhao/PSPNet: Pyramid Scene Parsing Network, CVPR2017. (github.com)