이번에 다루게된 주제는 6DoF pose estimation으로 RGBD 이미지를 활용하여 물체의 자세를 추정하는 과제 입니다. 해당 논문에서는 제가 저번에 리뷰를 작성했던 pvnet과 3D keypoint를 뽑는 방식, voting하는 측면에서 원리가 비슷합니다. 따라서 이전 리뷰를 안읽고 오셨으면 읽고오시길 추천드립니다. 그러지 않아도 이해하는덴 지장이 없으리라 생각되긴합니다.
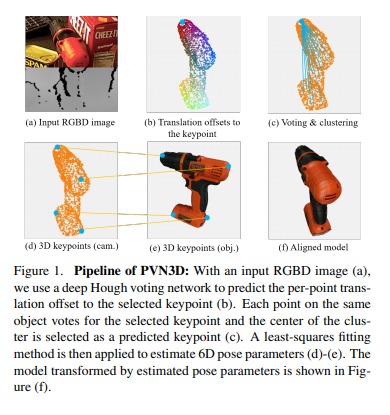
먼저 논문의 1페이지에 실려있는 그림을 보시면 RGBD이미지의 예시와 3D 키포인트를 추출하고 6D pose를 예측하는 대략적인 개략도가 있습니다. 아래에서 파이프라인과 함께 좀 더 자세히 다루겠습니다.
파이프라인
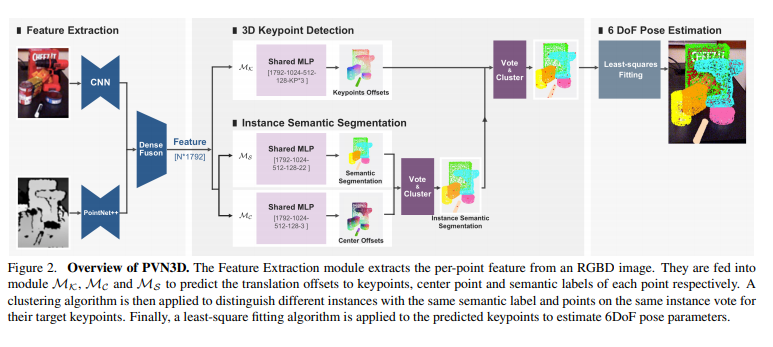
가장 중요하다고 여겨지는 파이프라인입니다. 먼저 인풋으로 RGB이미지와 각각의 픽셀에 corresponding하는 depth정보가 들어갑니다. 그림에서 보시면 위의 input이 RGB이미지이고, 아래는 depth정보 입니다. 각각의 인풋은 CNN과 PointNet을 거친 후 DensFusion 네트워크를 거쳐 concatenate 됩니다. 그리고 해당 concatenated된 feature를 기반으로 shared MLP를 통과시켜 keypoint regression, semantic segmentation, center offset을 동시에 수행합니다. 이때, Semantic Segmentation과 center 정보를 이용하여 clustering을 하여 semantic label정보가 같으나, 다른 인스턴스인 경우를 분리해줍니다. 이후, 아래 2개 모듈을 통해 나온 semantic label정보, 어떠한 instance에 속하는지인 centre정보, 위에 모듈을 통해 나온 keypoint offset정보를 바탕으로 target keypoint voting을 진행합니다. 그리고 해당 결과를 clustering하여 centre값을 prediction한 keypoint값으로 사용하고, 해당 keypoint들을 가지고 least-square fitting방식으로 6D pose를 예측합니다.
예시를 통해 이해하는데 도움을 드리겠습니다. 헷갈리시면 직접 파이프라인을 그려보며 인풋과 아웃풋을 적어보시는것을 추천드립니다.
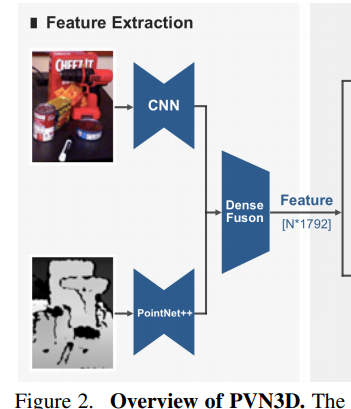
먼저 파이프라인의 앞부분을 살펴봅시다. RGB 이미지가 CNN을 거치는데 이때의 CNN은 이미지넷으로 사전학습한 ResNet-34를 사용하였습니다. 인코더와 디코더를 거치며 아웃풋이 128 채널인 피쳐로 나오게 됩니다. 그리고 depth정보는 PointNet++에 들어가고, 마찬가지로 128 채널의 아웃풋으로 나옵니다. 이후 , 해당 128 채널의 아웃풋과 shared된 MLP를 바탕으로 256으로 늘어난 피쳐를 추가적으로 생성합니다. 또한, 128개의 피쳐맵 2개를 concatenate하여 DenseFusion 네트워크를 통과시킨 후 1024개의 피쳐를 만듭니다. 그렇게 각각 128, 128, 256, 256, 1024 의 채널을 가진 피쳐맵을 뽑아내었습니다. 이제 이를 모두 concatenate해주면 총 1792의 채널을 가진 피쳐맵이 뽑힙니다. 같은 과정을 인풋이미지의 숫자인 N번 반복해주면 뽑힌 피쳐는 위의 그림에서와 같이 N*1792의 채널을 가질 것 입니다.
이렇게 뽑힌 1792의 채널을 갖는 N개의 피쳐를 각각의 3개의 모듈에 feeding하는 방식으로 아래와같은 3가지 task를 동시에 진행합니다.
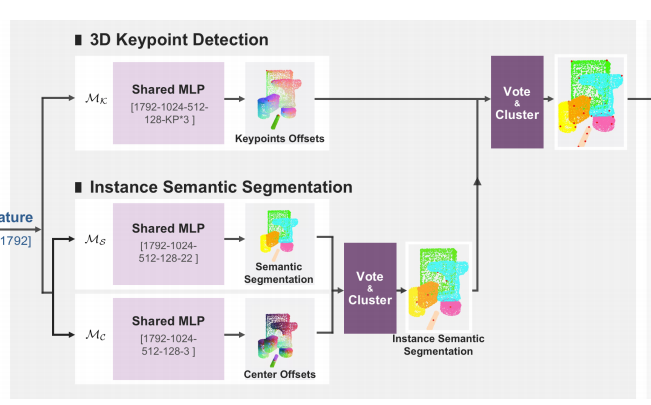
- keypoint offset voting module
해당 모듈에서는 위에서 뽑힌 피쳐를 기준으로 유클리디안 거리를 구합니다. 즉, (1792->1024->512->128->키포인트수*3)의 형태로 채널을 줄이며 최종적으로 키포인트수*3의 채널을 아웃풋으로 내보내는 MLP모듈을 거치게 됩니다. 이때 키포인트수는 하이퍼파라미터로 보통 8을 사용합니다.(2D PixelNet 논문에서 실험적으로 입증). 해당 voting하는 방식은 제가 리뷰했던 PixelNet과 흡사하며 이를 3D차원으로 확장한 것 입니다. 즉, 각각의 픽셀포인트마다 keypoint를 향하는 방향벡터를 구하고, 해당 방향벡터들로 이루어진 벡터장을 3D차원에서 만드는 것 입니다. 해당 내용이 이해가 안가시는 분들은 제가 저번에 작성했던 리뷰에서 자세하게 다루니 참고해보시기 바랍니다.
2. Semantic segmentation module
비슷한 원리로 해당 모듈에서는 (1792->1024->512->128->22)의 형태로 채널을 줄이며 해당 포인트가 어떠한 class label을 가지는지 예측하는 segmentation을 수행합니다. 이때, 22개의 채널을 아웃풋으로 가지는 이유는 총 21개의 class와 BG 인지 여부로 총 22개의 케이스가 있기 때문입니다.
3. Centre offsets
마찬가지로 해당 모듈에서는 (1792->1024->512->128->3)로 채널을 줄이며, 각각의 인스턴스가 가지는 centre point를 regression 문제로 풉니다.
이후, 2번과 3번의 모듈을 통과하여 나온 정보를 이용하여 clustering을 진행하는데 이는 같은 semantic label을 가져도 다른 instance에 속하는 경우를 고려하기 위함입니다. 즉, 2, 3 번을 거치고나서 각각의 픽셀마다 어떠한 class에 속하는지, 어떠한 instance에 속하는지, 그 해당하는 instance의 중심점의 좌표가 무엇인지를 구했습니다. 이 정보와 1번 모듈을 통해 구한 keypoint offset정보를 이용하여 또 다시 3D keypoint voting과 해당 예측한 3D keypoint로 clustering을 진행하게됩니다. 이를 통해 예측한 keypoint들 중 중심점을 최종 3D keypoint prediction 값으로 사용합니다.

이 후 해당 3D keypoint정보들을 기반으로 Least-square Fitting을 진행하는데요. 이를 통해 6D Pose의 정보를 최종적으로 알 수 있게됩니다.
LOSS
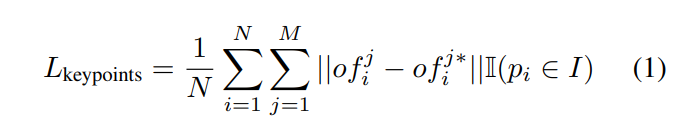
먼저, keypoint를 구하는 방식부터 생각해봅시다. 복잡한 수식처럼 보이지만 사실 상당히 간단한 L1 loss입니다. M은 keypoint의 개수를 의미하고, N은 input의 개수를 의미합니다. 또한, 절대값 안에 있는 연산은 GT keypoint의 3D 좌표값과 estimated된 좌표를 단순 빼준 것 입니다. 이 식이 의미하는 바는 모든 input이미지에서 나온 M개의 키포인트에 대해서 L1 distance를 더한 값들의 평균입니다.
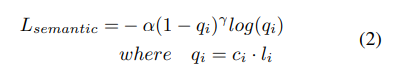
이번에는 semantic segmentation을 위한 loss를 살펴보겠습니다. 해당 식은 focal-loss로 metric learning 기반의 loss입니다. 일단 자주 등장하는 개념이라 익숙한데 좀 더 디테일하게 공부해봐야할 필요성이 있는거같습니다.
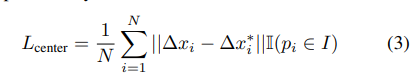
마지막으로 center 포인트에 대한 regression loss입니다. 위의 keypoint와 매우 유사한 L1 loss이며, 위에서 설명을 했기 때문에 아마 바로 이해가실거라고 생각합니다.
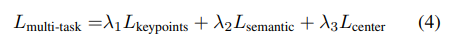
그렇게 총 3개의 loss를 설계하고 각각의 loss마다 람다인 가중치를 곱한 후 더해서 total loss를 설계했습니다. 매우 흔한 테크닉이므로 아마 친숙하실거라 생각합니다.
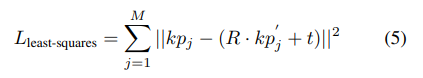
이후 예측된 keypoint가 camera 좌표계에서의 값이기 때문에 least-square fitting 방식과 카메라파라미터인 R, t를 사용하여 위와같은 square loss를 최소화 하는 방식을 사용합니다. 위의 식에서 M은 keypoint의 개수를 의미하며, 절대값 안은 detected된 keypoint와 object 좌표계에서의 keypoint를 변환한 값의 차이를 의미합니다.
평가
평가는 데이터셋 2 종류에서 진행하였으며 아래와 같습니다.
데이터셋
- YCB-video Dataset
92개의 비디오로 구성되어있으며, 6D 포즈정보와 segmentation 마스크정보가 GT로 제공됩니다. 또한 해당데이터셋에는 어두운 이미지, 노이즈가 낀 이미지, 가려진 이미지 등이 포함되어 있습니다. 논문에서는 80/12로 학습과 테스트를 나누어서 사용하였고 테스트셋에는 2,949개의 keyframe이 포함됩니다.
2. LINEMOD
해당 데이터셋은 6DoF에서 가장 유명한 데이터셋인데요. 13개의 물체와 13개의 비디오로 구성되어있습니다.
3. 평가지표
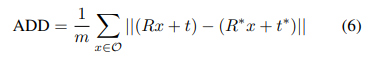
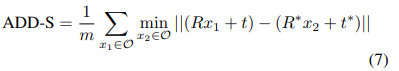
이때의 평가지표를 살펴보면 위와 같습니다. 별표는 GT를 뜻하고요, 별표가 없는건 prediction 값 입니다. 또한, ADD-S에서 S는 대칭인 물체들을 뜻하며, 물체의 대칭여부에 따라 다르게 평가를 하였습니다.
평가 결과
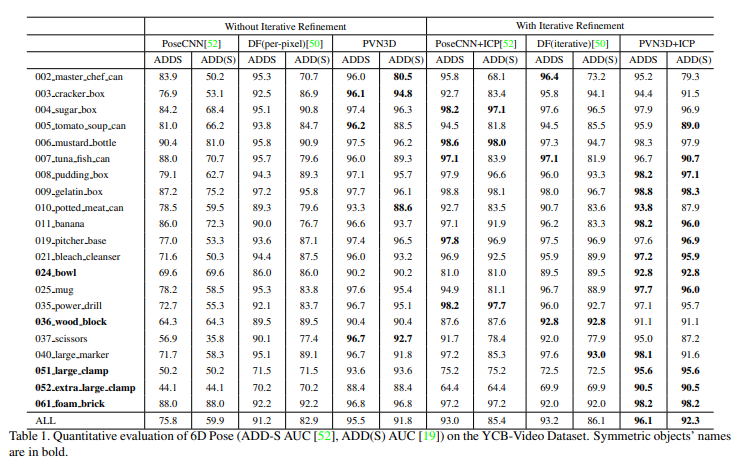
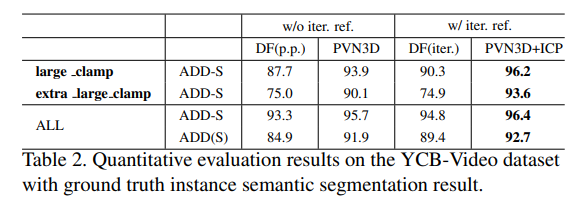
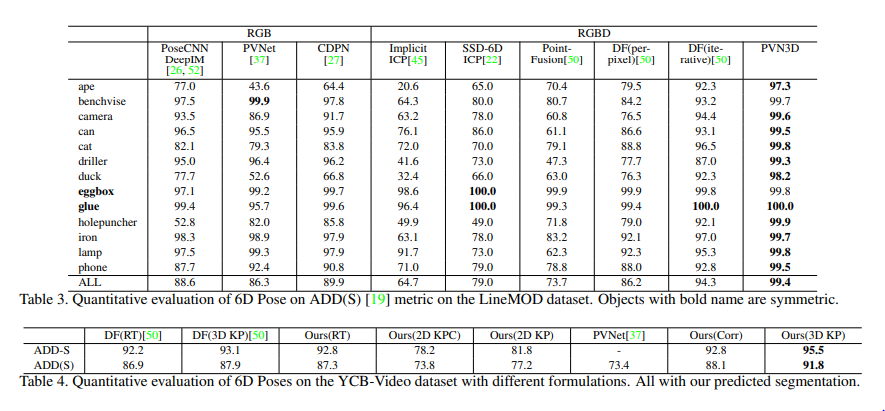

해당 데이터셋에서 All에 대해서는 두개의 데이터셋 모두에서 SOTA를 찍었습니다.

정성적으로도 잘 나온것을 알 수 있습니다.
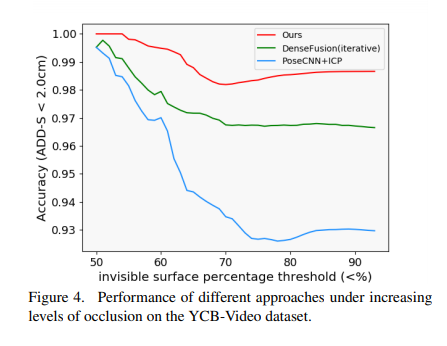
YCB-video dataset에서 occlusion의 정도를 인위적으로 바꾸며 실험을 했을때, ADD(S) 평가 매트릭 기준 가장 성능 드랍이 적은 것을 볼 수 있습니다.
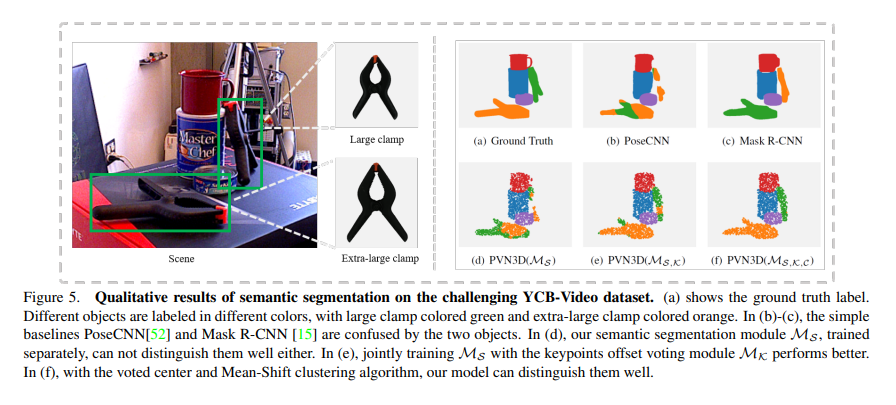
shared-MLP를 각각 사용할때, 정성적으로도 결과가 달라짐을 보여줍니다.
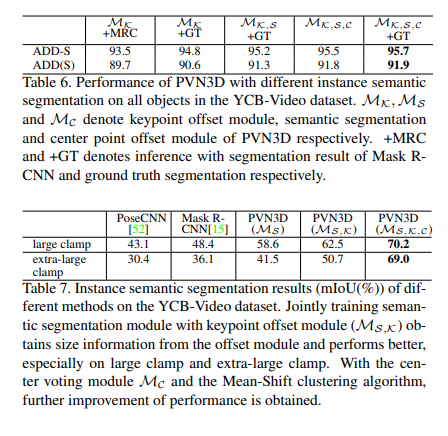
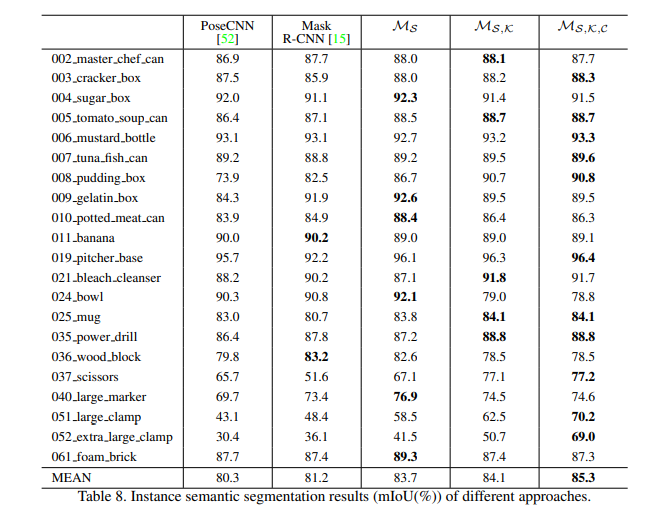
각각의 모듈의 적용 유무에따른 성능을 분석한 ablation study결과이며, 6D pose와 semantic segmentation 모두에서 해당 3개 모둘 모두를 사용했을때 성능이 가장 좋았습니다.
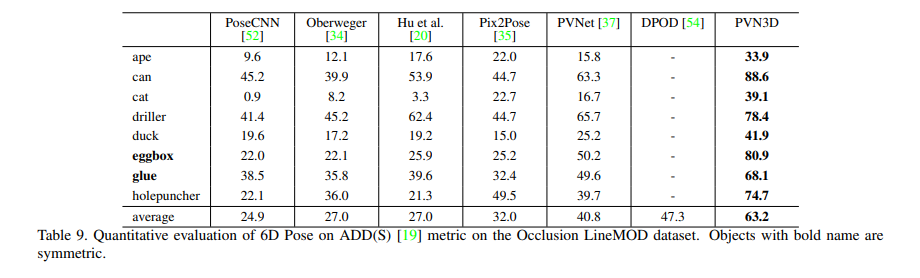

GT keypoints와 predict된 keypoint를 정성적으로 보여줍니다.
논문후기
2개에 데이터셋에서 실험이 엄청 다양하고, 그 실험들이 해당 논문의 컨트리뷰션을 뒷받침하기에 적절하게 매핑되었다고 느꼈습니다. 설명도 워낙 자세해서 이해하기 쉬웠고 잘 쓰여진 논문이 이런거구나 라고 느끼게 해준 논문이었습니다.
다만 아쉬운점은 같은 semantic label을 가지나 다른 instance에 속한 경우가 많은 케이스에 대해서 잘 결과가 나오는지에 대한 실험이 없습니다.
또한, LINEMODE dataset에서는 한개의 이미지에 다양한 label을 가진 object들이 존재하더라도 한개의 object에 대해서만 GT가 존재합니다. 따라서 해당 문제때문에 각각의 label마다 binary하게 segmentation label을 정의하고 독립적으로 학습했습니다. 즉, 모델을 object의 갯수만큼 나누어서 학습을 하였으며, 해당 문제는 PVNet에서도 존재하던 문제로 PVNet에서 사용하는 방법을 그대로 사용한 것입니다.
이러한 문제점에도 불구하고, 모든 실험에서 확실한 결과와 컨트리뷰션을 확실하게 뒷받침해줄 결과, 엄청나게 친절한 설명과 코드공개로 인해 상당히 좋은 논문이라고 생각합니다.
(성능차이를 볼때) 결국 6DOF 논문들에서는 아직 ICP라는 과정이 필수적으로 사용되는거 같은데, 해당 과정에 대해서 설명해주실 수 있으신가요?
해당 부분은 논문에 나와있지 않아서 이해하지 못했습니다. related work의 reference를 참고해보세요.
평가지표로 ADD와 ADD-s가 사용되었는데 수식으로 보았을 때 이는 실제 gt rotation과 translation을 적용했을 때 위치와 예측 rotation과 translation을 적용했을 때 위치의 차이인 듯하며 그럼 결국 이에 대한 값이 작아야 좋은 성능을 보이는 것으로 판단 가능할 듯한데 Table 4에서 ours 방법론들 이외의 방법론의 값이 더 작음에도 불구하고 SOTA라고 불리우는 것이 헷갈려 질문드립니다.
ADD와 ADD-s 는 값이 작을수록 좋은 성능을 보이는 것이 맞나요?
거리만 보면 그러하나, 해당 평균 거리를 기준으로 일정 threshold보다 작은 얘들을 맞은 pose라고 가정하기 때문에 높을수록 성능이 높습니다.
안녕하세요 연구원님,
좋은 리뷰 감사합니다.
PVN3D 논문의 전반적인 방법을 이해하는 데 많은 도움이 되었습니다.
질문이 하나 있는데요 depth 이미지를 가지고 feature를 추출할 때 RGB 이미지에서 처럼 2D 이미지로 입력이 되는지 포인트 클라우드로 입력되는지 궁금합니다.
그리고 keypoint detection module에서 3차원 상의 포인트 클라우드에서 유닛 벡터가 결정되기 때문에 최종 출력 채널 수가 (키포인트 개수)*3 인 거라고 이해했는데 맞게 이해했을 까요?