지난번 리뷰에 이어집니다. (1편 보러가기)
본 논문은 Series of monocular images를 통해 3D Detection과 Tracking을 수행한 논문 입니다. 아래 티저 영상에 나타나듯 단일 이미지로 3D Detection을 수행하고, 시퀀스 이미지의 정보를 통해 강인한 Tracking까지 수행하는게 해당 논문의 핵심입니다.

지난 리뷰에서는 3D Object Detection까지 다뤘다면, 이번 리뷰에서는 ‘Data Association and Tracking’에 대해서 다루겠습니다.
Data Association and Tracking
앞선 리뷰에서 설명했듯 현재 모델은 각 이미지마다 candidate detection 찾은 상황입니다. 또한 각 프레임마다의 set of track도 주어졌다고 합니다. 해당 세션에서는 이러한 candidate detection, set of track 데이터의 association problem을 해결하는 방법을 다루고 있습니다. 저자는 이러한 association problem을 해결하기 위해서 weighted bipartite matching algorithm을 사용하였다고 합니다. track과 detection사이의 Affinites(연관성,밀접성)은 3가지를 기준으로 계산되며 이 3가지는 다음과 같습니다.
- 현재까지 누적된 track에서 구한 Feature인 F_τ와 object detection에서 구한 Feature인 F_s로 deep representation similarity인 A_deep을 구합니다.
- 현재궤적(current trajectories)을 기준으로 B시간 앞의 3D bbox의 projection와 candidate bbox와의 iou를 구합니다.
- 현재궤적에서 축적된 모션 벡터 V_ τ 와 앞서 구한 pseudo object 모션 벡터 V_s의 유사도를 구합니다.
여기서 궤적(trajectory)는 추정된 물체의 속도와 카메라의 ego-motion을 이용해 다음 시간으로 투영된다고 합니다. 그리고 여기서 ego motion은 데이터셋에서 제공된 GPS,accelerometer, gyro, IMU로 추정했다고 합니다. 위에 내용에 대해서 수식적으로 나타내면 다음과 같습니다.
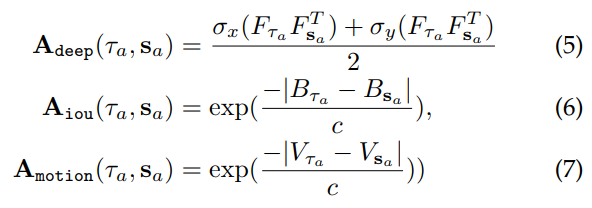
이러한 3가지 기준을 통해서 최종적으로 Affinity(연관성) matrix인 A를 구할 수 있으며 이는 다음과 같습니다.
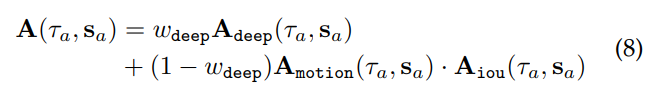
이 Affinity matrix는 semantic, spatial and temporal similarites를 모두 집합된 ‘찐’ 유사도 matrix라고 할 수 있습니다. 위의 수식에서 w_deep은 appearance similarity, hybird of motion, and 3D location overlap의 밸런스를 잡아주는데 그냥 저희가 Loss 설계할 때 추가하는 lamda와 같다고 생각하시면 됩니다.
Data Association Scheme
이전연구들과 같이 본 논문에서도 tracker의 lifespan을 4가지 subspace로 나타냈으며, 이는 birth, tracked, lost, death 로 구분한다고 합니다.
tracked는 affinity score가 높게 매칭되는 페어가 있는 경우의 상태를 이야기하며(즉, trackin중이다.) birth는 매칭되지 않는 새로운 detection이 만든 tracklet의 상태를, death는 동일하게 매칭이 없지 않지만 기존에 있던 tracklet의 상태를, 마지막으로 occluded region에 의해서 사라지는 tracklet의 상태는 lost로 나눈다고 합니다.
이때 lost 상황에 대해서 잘 처리하면 좋은 성능을 낼 수 있는데, 저자는 논문에서 lost tracklet은 occlusion에 의해서 발생하므로 affinity score를 구할때 사용되는 feature representation을 다시 나타날때까지 업데이트 하지 않는다고 합니다. 반면에 3D location은 계속 예측하는 거죠. 이러한 예측은 저자가 정의한 tracking range(0.15~100m)를 벗어나거나, 10 time-steps으로 설정한 lifespan을 벗어날때까지 수행한다고 합니다. 이러한 방법은 disppeared object track을 object occlusion이 해결될때까지 유지시킬 수 있다고 합니다. (아마 메모리의 효율성과 관련된 이야기를 하는것 같네요)
Depth-Ordering Matching
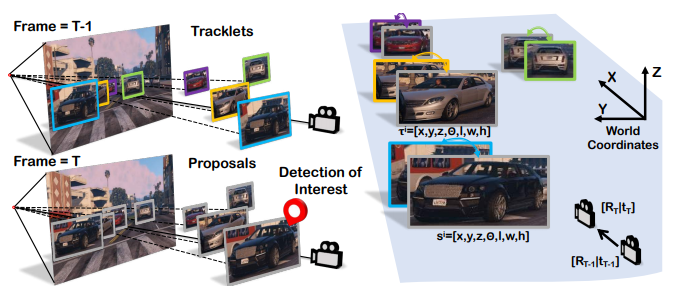
추가적으로 저자는 Depth Ordering Matching 방법을 제안합니다. 이는 detection 결과를 가까운 tracklets과 매칭하는 방법을 이야기합니다. 정리하면 moving object의 data association problem을 해결하기 위해 위의 그림과 같이 world coordinated에서의 3D targectories를 이용했다고 합니다. 이럴 수 있는 이유는 neighbor tracklets은 멀리있는 것보다는 higer probabilites of linking similar를 제공하기 때문이라고 합니다.
Motion-aware Data Association
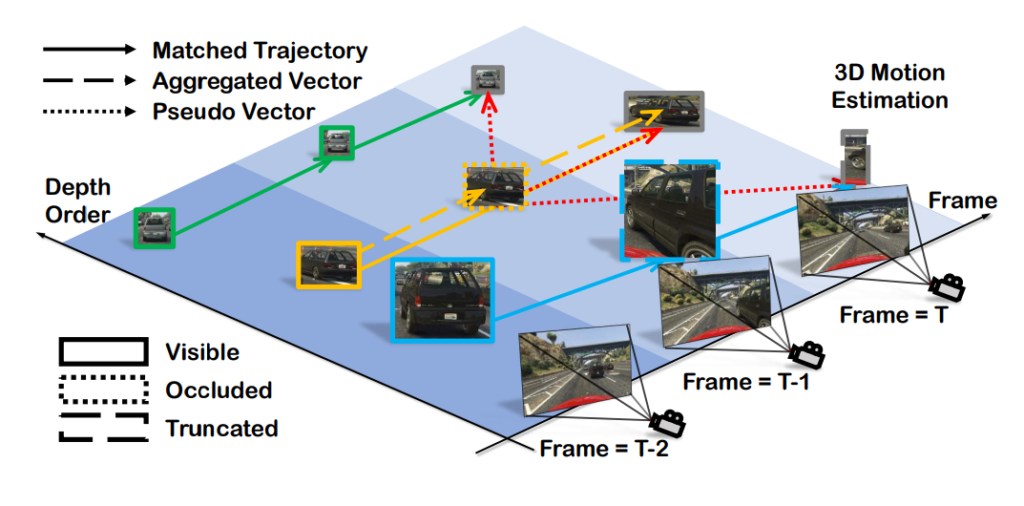
다음으로는 data association을 구하기 위해서 motion도 사용한다는 내용입니다. 단일 이미지의 depth estimation을 통해서 얻은 pseudo motion vector와 축적된 motion vector를 이용해 association을 구한다고 합니다. 이때 모션만 가지고 Association을 구할 수 없기 때문에 centroid location of the object를 추가했다고 합니다.

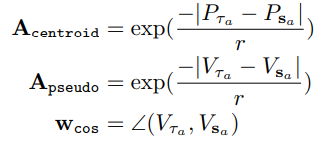
여기서 w는 두 모션 벡터간의 normalized cosine similarity를 의미합니다.
Motion Model Refinement
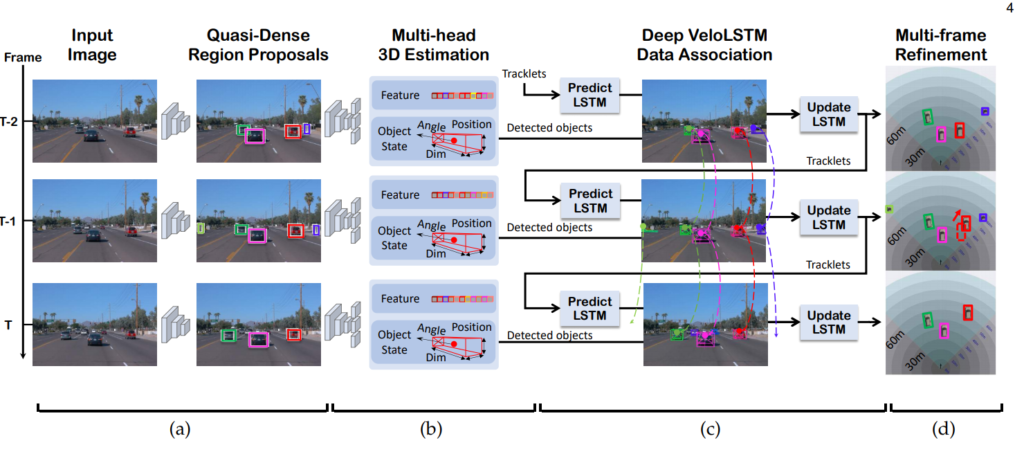
저자는 object state prediction과 updating을 위한 2가지 LSTM 모델을 추가합니다. 그리고 해당 과정은 위의 그림에서 (c)에 나타납니다.
먼저 object state를 예측하기 위한 P-LSTM은 dynamic object state를 예측합니다.
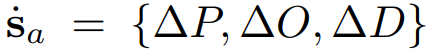
그리고 이를 이전에 예측된 state에 더해서 현재 state를 계산합니다.
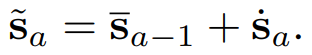
여기서 P,O,D는 1편에도 설명했지만, P는 position과 관련된 x,y,z 를 의미하며, O는 orientation과 관련된 θ , 그리고 D는 dimension을 의미하며 l,w,h를 이야기 합니다.
그리고 U-LSTM이 있으며, 이 U-LSTM은 3D estimation module로 추정된 object state와 previously predicted state를 관찰(observe)하고, 현재의 depth estimation의 3D confidence(1편참고)를 고려해 업데이트를 수행한다고 합니다.
(해당 부분에 대해서 이해가 잘 안되는데 시간이 지나고 다시 확인해보겠습니다.)
앞선 내용을 전부 정리하면, 저자가 제안하는 파이프라인은 object-level의 pose inference를 위한 single-frame monocular 3D object detection과 inter-frame object association and matching을 위한 RNN으로 구성됩니다. 각각의 object instance마다 multihead module을 적용해 3D estimation을 포함하는 region processing로 확장시키고, inter object occlusion problem을 해결하기 위한 motion aware association도 설명했습니다. 그리고 trackelt 매칭을 위해서 depth ordering을 통해 target으로 부터 멀리 떨어진 candidate를 필터링하여 mismatch rate를 낮출 수 있었다고 합니다. 또한 LSTM motion estimator를 이용해 velocity와 카메라 이동 또는 다른 object와의 interaction에 상관없이 object의 state를 업데이트했습니다. 이러한 파이프라인은 정확하고 smooth한 object rajectories를 3D world coordinate로 생성이 가능하게 했다고 저자는 이야기합니다.
3D VEHICLE TRACKING SIMULATION DATASET

3D에서 트래킹하는 것을 학습하고 확인하기 위해서 3D box를 만드는데 너무 많은 돈과 노동력이 필요해서 GTA5를 기반으로 시뮬레이션 데이터를 만들었다고 합니다. GTA5를 쓰면 게임상에서의 3D Annotation 정보를 직접적으로 얻을 수 있다고 합니다.
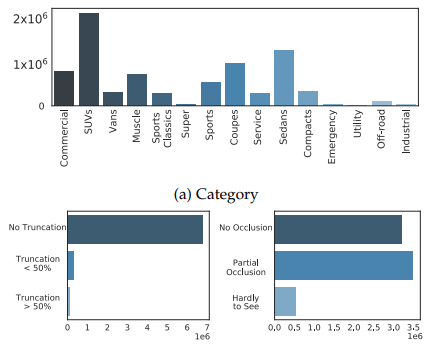
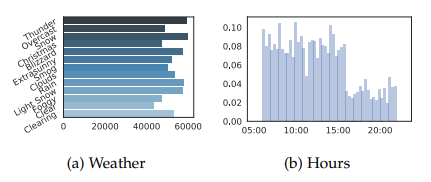
데이터의 구성은 다음과 같다고 합니다.
EXPERIMENTS
해당 논문에서 새롭게 알게된 평가지표를 제외하고 나머지는 모두가 아시는 부분이라 생략하겠습니다. 본인들의 데이터셋 뿐만 아니라, KITTI, nuScenes, Waymo 데이터셋으로도 평가를 수행했다고 합니다. 새롭게 설명할 평가 지표는 MultipleObject Tracking Evaluation 입니다. 해당 분야에서는 각각의 평가 방법이 존재한다고 합니다.
- Multiple Object Tracking Accuracy (MOTA)
- Nultiple Object Tracking Precision (MOTP)
- Miss-Match (MM)
- Mostly-Tracked (MT)
- Partly Tracked (PT)
- Mostly-Lost (ML) 등등.
여기서 MOTA는 다음과 같이 계산한다고 합니다. 조금 어려워서 다른 논문에서 해당 내용을 가져오면 다음과 같습니다.
MOTA는 주어진 지상 실측 정보와 다중 객체 추적 시스템의 추적 정보 결과를 비교하여 추적 정보를 놓치는 경우 (Missed Detects), 가긍정적 판단(False Positives)인 경우, 추적 정보가 다른 객체와 바뀌는 경우의 수를 계산한다. 이렇게 계산된 결과를 식 (6)에 적용하여 MOTA를 구한다. MOTA를 통해 다중객체추적의 정확도를 평가할 수 있다.
-시계열 특징을 이용한 의사결정트리 기반 블랍 겹침 해결 방법 연구-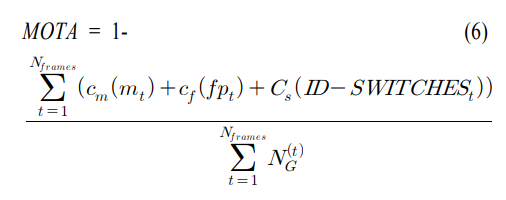
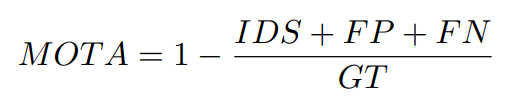
동일한 방법이라 생각될때를 생각해서 비교하면 될 것 같습니다. 놓치는 경우가 FN, 잘못찾으면 FP, 추적 정보가 다른 객체와 바뀌는 경우는 IDS이고 GT는 positive의 합을 의미하는것 같습니다. 추가로 nuScenes 데이터셋에서는 Average Multi-Object Tracking Accuracy (AMOTA)를 사용한다고하며 이에 대한 수식은 조금 바껴서 다음과 같습니다.
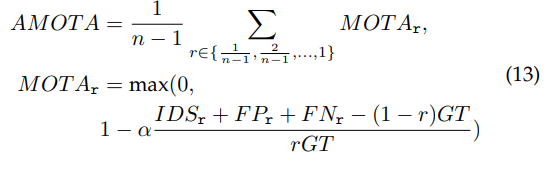
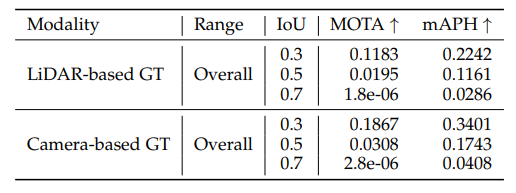
따라서 이를 기준으로 성능을 보면 다음과 같습니다.
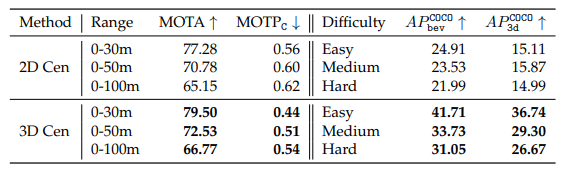
KITTI
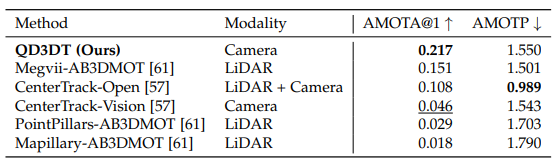
nuScenes
waymo
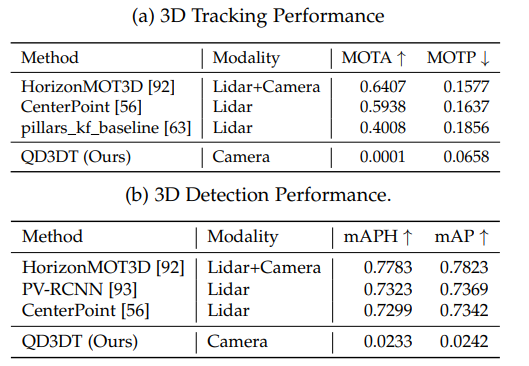
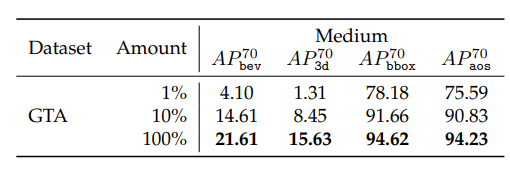
GTA
Conclusion
(저자 주장에 의하면) 결국 카메라 기반으로 3D Detection 및 tracking을 수행하여서 nuScenes 데이터에서 기존의 카메라 기반 방법들보다 500%이상의 성능을 높이고, LIDAR 방법들과의 GAP을 줄일 수 있었다고 합니다.
(여담) 좋은 논문일텐데 저에게는 아직 어려운것 같습니다. 논문작업이 끝나면 좀 더 보충해서 정리하겠습니다.