이번에 리뷰할 논문은 CVPR 2020에 공개된 PaDiM이라는 논문입니다. 관련주제는 Anomaly Detection입니다.
Anomaly Detection?
Anomaly Detection이란 특이점을 찾는 것을 의미하며 novelty detection이라고도 불립니다. 일반적인 object detection과는 상당히 다른점들이 많은데 그 이유에 대해서 먼저 말해보겠습니다.
일반적인 supervised 기반의 object detection을 생각해보면 어떠한 모델을 설계하고 해당 모델을 GT label과 bbox 정보를 통해 학습을 시킵니다. 즉, 학습을 통해 모델에 들어가는 파라미터들인 weight와 bias들을 최적화 시키고 해당 학습된 모델을 이용하여 label에 대한 classification과 bbox regression을 동시에 수행합니다.
그러나 anomaly detection에서는 위와같이 supervised 기반으로 문제를 해결하기에 적합하지 않은 경우가 많습니다. 그 이유로 가장 큰 원인은 class imbalance 문제 때문입니다. 먼저 anomaly detection에서 라벨을 정의한다고 생각해봅시다. anomaly인 경우와 아닌경우… 즉 binary classification 문제로 귀결 시킬 수 있습니다. 이때, 정상적인 normal case가 대다수를 차지하고 anomaly인 경우가 극소수를 차지하면 모델은 정상적인 normal case에 편향되어 학습이 됩니다. 그렇기 때문에 학습이 제대로 되지 않습니다.
물론 supervised로 풀 수 있는 경우도 있습니다. 예를들어 2021년 CVPR에 공개된 논문중 한개인 Sewer-ML: A Multi-Label Sewer Defect Classification Dataset and Benchmark 의 경우 하수처리 시설에서의 anomaly인 경우를 각각 정의하고 이를 multi-class classification문제로 해결 할 수 있도록 GT label을 제공합니다. 그러나, 이 경우에는 defect가 있을 경우와 없는경우의 비율이 약 50:50 으로 균형을 이루고 있습니다. 즉, 하수처리장에서의 defect 특성상 실제 defect가 있는 비율이 많은 경우에는 각각의 defect에 대해서 라벨을 정의하고 supervision으로 푸는 것이 가능합니다. 그러나 위에서 언급했듯이 class imbalance가 심한 경우에는 그렇지 못하게됩니다.
예를 들어서 전기시설물에서 anomaly인 경우를 감지한다고 생각해봅시다. 시퀀스한 비디오데이터로부터 anomaly를 감지해야하는데 anomaly가 100만장의 사진에서 한장이 나올까 말까라고 가정 해봅시다.(실제로 이런 극단적인 class imbalance 문제가 있는 경우가 흔합니다.) 이런 경우에는 supervised가 아닌 un-supervised로 푸는 것이 좀 더 현명해보입니다. 즉, distribution이 정상과 많이 다른 것을 anomaly로 구분해내는 식으로 접근하는 것 입니다.
MVTec-AD 데이터 셋
논문을 소개하기에 앞서서 데이터셋에 대해서 언급하겠습니다. 2019년 CVPR에 공개된 MVTec-AD 데이터셋은 아직까지도 anomaly detection task에 많이 사용되고 있습니다.

위의 사진은 MVTec-AD 데이터셋의 모습이며, anomaly인 경우와 정상인 경우를 담고 있습니다. 주목 해야할 점들은 방대한 양, 각각의 instance를 확대하여 찍은 사진들, align이 맞는 사진들 이라는 점 입니다. 또한, anomaly인 경우에 anomalous한 부분을 mask를 씌운 형태로 GT 라벨로 제공합니다. 즉, anomaly detection을 한 후 나온 anomaly map과 GT anomaly mask를 비교해서 성능을 평가 할 수 있습니다.
PaDiM
먼저 해당 논문에서 제안하는 방법으로 MVTec-AD 데이터셋에서 anomaly map을 뽑은 것을 먼저 보겠습니다.

첫 번째 컬럼은 정상, 두 번째는 anomaly, 세 번째는 anomaly map을 뽑은 상태입니다. 마치 attention map과 비슷하게 보이는데, 노란색으로 표시된 영역이 검출된 anomalies를 의미합니다. 그리고 파란색은 normal한 부분이고요. 이처럼 distribution을 통해서 anomaly를 검출하는데 좀 더 자세히 다루기 전에 먼저 anomaly detection에 사용되는 방법론들이 크게 어떻게 나뉘는지 좀 다루고 넘어갈까 합니다.
Reconstruction-based methods
Anomaly detection에서 많이 쓰이는 것중 하나가 Reconstruction-based 방법론들 입니다. Auto-encoder기반 방법론들과, GAN기반 방법론 등 방법은 다양하지만, 원리는 비슷하므로 해당 리뷰에서는 원리에 대해서만 다루고 넘어가겠습니다.
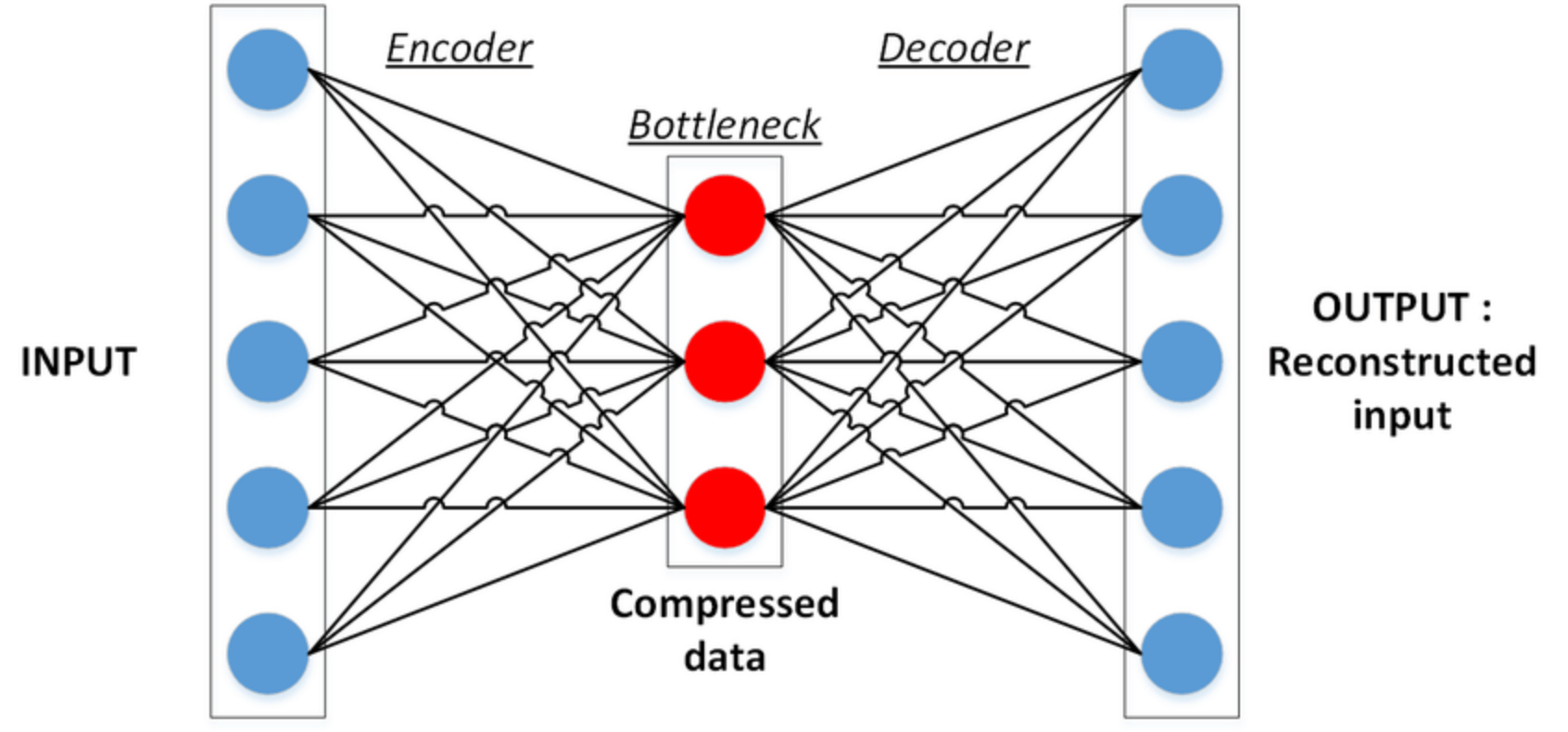
이해를 돕기위해 auto-encoder의 사진을 예시로 가지고 왔습니다. input 이미지가 들어갔다가 차원이 축소되며 bottleneck까지 갔다가 다시 decoder를 거치고 reconstructed input이 나오게 됩니다. 이를 통해 input 이미지를 다시 reconstruction하게 됩니다. reconstruction loss를 설계하고 normal 이미지만을 이용하여 모델을 먼저 학습한다고 생각해봅시다. 학습된 모델은 normal 이미지에 대해서만 복원을 잘 하는 모델이 될 것이고, anomaly인 경우가 있으면 복원이 잘 되지 않을 것 입니다. 모델을 테스트 할 때, 정상적이지 않은 anomaly image를 input으로 넣고 reconstructed된 이미지에서의 reconstruction loss가 바로 anomaly score로 사용됩니다.
Embedding similarity-based methods
Embedding similarity-based methods도 말은 어려워보이지만 원리는 간단합니다. 원리를 설명하기 보다는 간단한 예시를 들어 이해하는게 쉬울거 같아서 간단한 예시를 들어 보겠습니다.
CNN모델이 있다고 쳐봅시다. 이미지가 해당 CNN 모델을 통과하고 1개의 벡터를 아웃풋으로 뱉는다고 했을때, 해당 아웃풋을 embedding vector이라고 할 수 있는데요. 즉, 이미지들 마다 각각 고유의 representing vector(embedding vector)를 가질 수 있습니다. 만약에 이미지들중에 anomaly인 경우가 섞여있을 경우에, 이 vector들을 embedding space상에 뿌려둔다고 해봅시다. 그럼 아래 그림과 같을 것 입니다.

해당 그림의 오른쪽에서의 원안에 들어가는 embedding vector는 normal한 distribution을 가지는 경우이고 원 밖에 있는 벡터들은 anomaly인 경우에 해당 합니다. SVM에서 결정경계에 해당하는게 바로 이 원(hypersphere) 입니다. 그리고 해당 원의 최소 반지름을 찾는 알고리즘이 바로 대표적인 embedding similarity-based 방법론인 SVDD입니다. SVM과 비슷한 원리로 anomaly detection에서 기계학습적인 SVDD를 사용할 수 있으며 최근에는 deep SVDD, patch deep SVDD등 deep learning을 결합시킨 SVDD로 발전을 이루어 왔습니다.
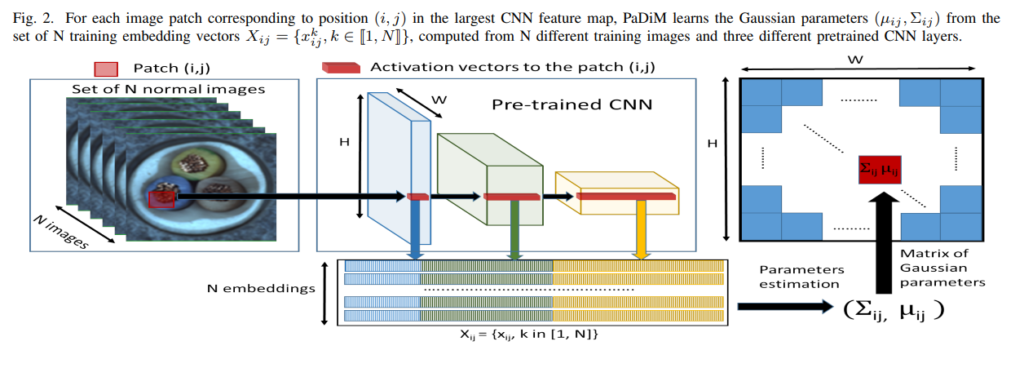
위의 그림은 해당 논문에서 제안하는 아키텍쳐입니다. 총 N개의 normal 이미지를 인풋으로 받고 3개의 Pre-trained된 CNN레이어를 통과하며 N개의 embedding 벡터를 만들고 해당 벡터들을 이용하여 뮤와 covariance 값을 계산합니다. 이 때, 뮤와 covariance 시그마는 multivariate gaussian distribution을 구성하는 파라미터들 인데요. 일반적으로 가우시안 분포가 대칭인 종의 형태였다면 원의형태로 만들어준 것이 multivariate gasussian distribution입니다. 이 때, 원의 형태의 분포가 있을때 원의형태를 결정짓는 시그마와 원의 위치를 결정짓은 뮤에 의해서 원이 어떠한 위치에 어떠한 형태로 위치할것인지가 정해집니다. 좀 더 디테일한 설명은 해당 링크 참고를 추천드립니다.
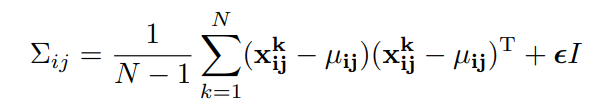
뮤 값은 각각의 패치에서의 평균값이되고, covariance matrix인 시그마는 위와같이 계산됩니다. 이때 뒤에 입실론*I는 regularization term입니다.
즉, 이미지가 있으면 각각의 패치마다 embedding 벡터가 있으며 CNN 레이어 총 3개를 거치며 각각의 피쳐단에서 나온 피쳐맵을 concat합니다. 이 때, 인풋이미지의 사이즈가 H * W 이나 CNN 레이어를 통과하며 사이즈가 변하게 되는데, 이에 따라 몇몇의 Patch에는 똑같은 피쳐가 concat될 수도 있습니다. 이러한 문제때문에 저자는 redundant한 정보를 줄이기위해 차원을 감소시킵니다. 실험적으로 PCA를 통해 차원을 감소시키는 것보다 랜덤하게 감소시키는게 더 성능이 높았다고 하네요. 이를 통해 complexity를 감소시키고 성능을 올렸습니다.
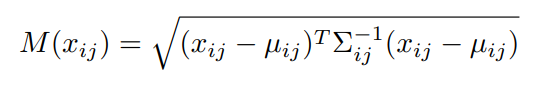
anomaly score는 테스트를 할때, 테스트 이미지를 인풋으로 주어 CNN layer를 통과하고 나온 embedding vector들을 N개의 normal image를 이용하여 얻은 multivariate gaussian distribution의 중심과 위의 공식과 같은 마할라노비스 거리를 측정하였고, 해당 거리를 anomaly score로 사용했다고 합니다.
Metrics
- AUROC ( Under the Receiver Operating Characteristic )
먼저 사용한건 AUROC 매트릭으로 픽셀레벨에서 일정 threshold를 주고, 올바르게 classified된 anomaly의 비율을 이용한 것 입니다. 그러나 이는 anomaly가 많을때는 bias될 수 있으므로 아래와 같은 매트릭을 추가하였습니다.
2. PRO-score ( per-region-overlap score )
It consists in plotting, for each connected component, a curve of the mean values of the correctly classified pixel rates as a function of the false positive rate between 0 and 0.3.
위에서 curve에 대해서 설명했고 normalize한다음 더한 값이 PRO-score이며, Pro-score의 값이 높을 수록 크고 작은 anomaly가 다 잘 localized 되었다 라네요. 이해가 안가는 부분은 원문으로 가지고 왔는데… 구글링해봐도 해당 매트릭이 잘 안나오네요.
평가
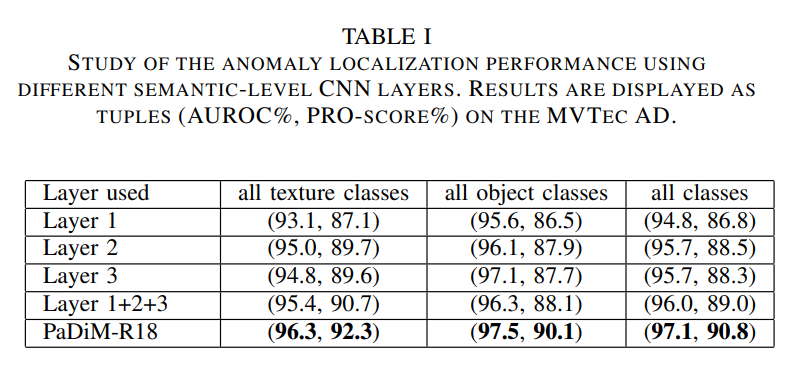
위에는 MVTec-AD 데이터셋에서 각각의 layer에 대해서 ablation study한 결과이구요.
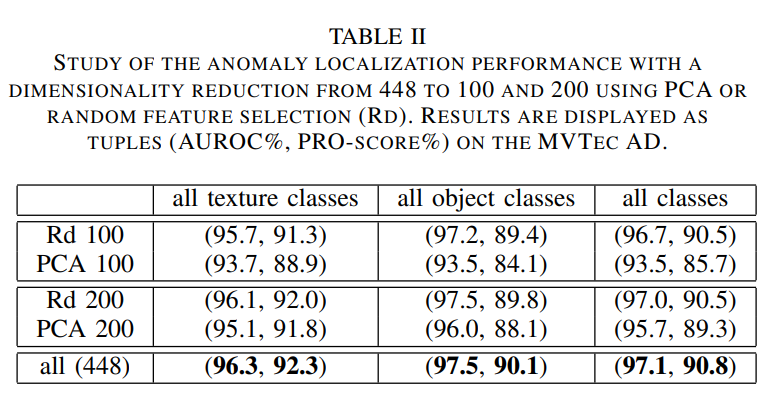
PCA를 하여 차원을 감소시킨거보다 RANDOM하게 감소시킨게 더 성능이 좋았다고 한걸 실험적으로 보이네요.
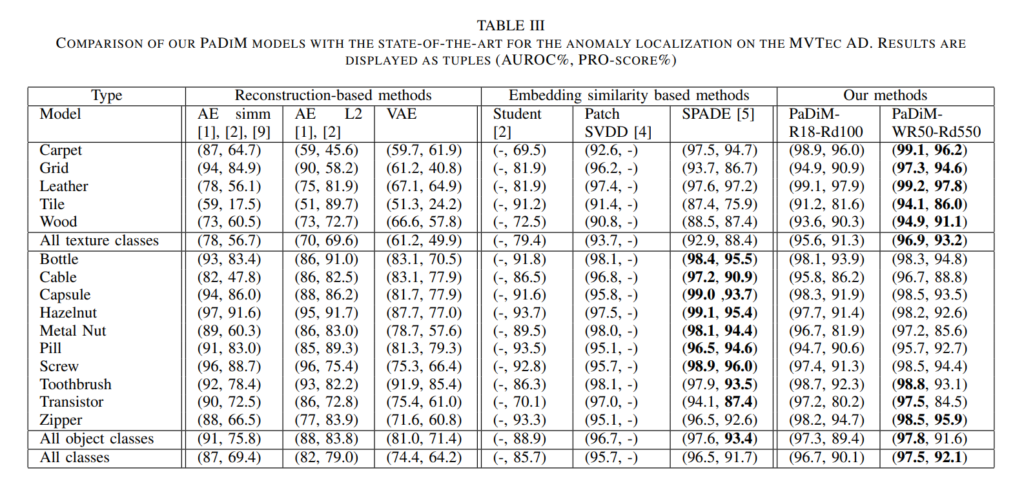
그리고 Localization에 대해 MVtec 데이터셋에서 평가매트릭 All object classes의 Pro-score 을 제외한 모든 매트릭에서 소타를 달성했네요.(ALL SCORE 기준)
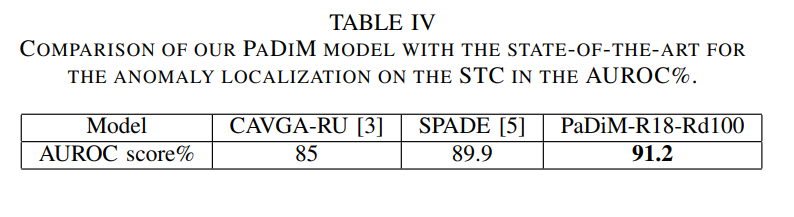
STC 데이터셋에서도 sota 모델들과 비교했을때, sota를 달성했구요.

Detection에 대해서도 소타를 달성했구요.
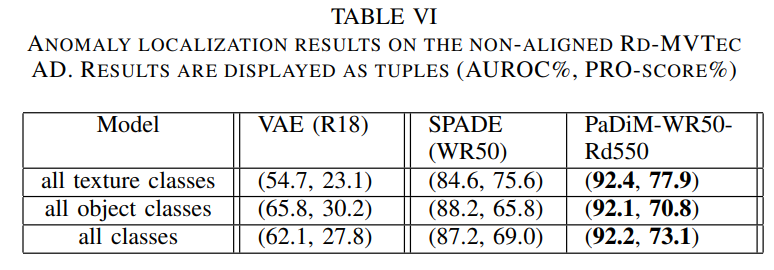
자체적으로 만든 RD-MVTec-AD 데이터셋에서도 소타를 달성했습니다. 해당 데이터셋은 align이 맞지않는 real-world 상황을 재현하기 위해 random rotation과 random crop을 적용하였습니다.
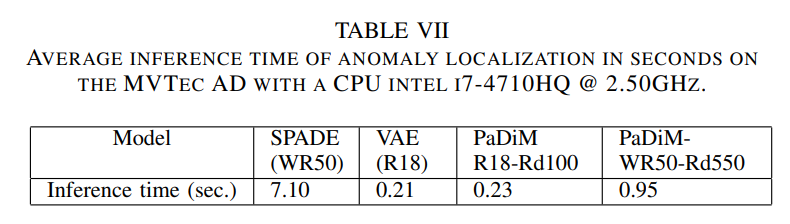
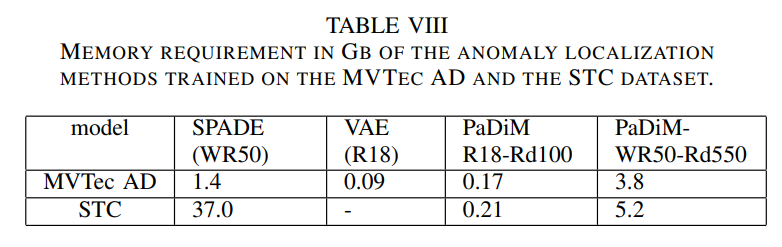
차원감소로 dimension을 줄이며, complexity를 줄였기 때문에 속도도 빠르구요.
결론적으로 노말이미지 세트를 이용하여 구한 multivariate gaussian distribution과 테스트 이미지의 마할라노비스 거리를 구해서 anomaly인지 여부를 판단하는 그런 논문이었습니다. 성능이 좋고, 속도가빠르다는 것이 논문의 핵심기여이고요. 추가적으로, 얼라인이 맞지않는 데이터셋을 만들어서 해당 데이터셋에서 좋은 성능을 보임으로써, anomaly detection이 align이 맞지않는 데이터셋에서도 가능하게하는 가능성을 보였습니다.
이상 리뷰 마치겠습니다.
신기한 연구를 소개시켜주셔서 감사합니다. 해당 방법론을 적용하려면 detection이후의 detection된 영역을 crop하고 수행해야할 것 같습니다. background가 많은 이미지에 대해서도 annomaly detection이 가능할까요? 만약 Detection이 필요하다면 anomaly object를 모델이 정상적으로 detection을 수행할 수 있을까요?
네 지적하신대로 MVTec-AD 데이터셋은 이미지내에 인스턴스가 가득차있다라고 가정합니다. 즉 디텍션이 퍼펙트하게 되어있는 상태를 가정합니다. 하지만, 해당 방법론에서는 패치단위로 피쳐를뽑기 때문에 디텍션이 완벽하게 되어있지 않는 경우에 좀 더 강인합니다. 해당 논문에서는 디텍션이 완벽하게 되지 않은 상황(얼라인이 맞지 않는상황)을 재현하기 위해 랜덤크랍과 랜덤로테이션을 적용하여 평가를 진행하였고 해당 경우에 대해서도 소타를 달성했습니다. 따라서, 디텍션이 완벽하지 않은 상황에서도 anomaly 디텍션이 가능할 수 있을 가능성을 제기했습니다.