딥러닝을 학습 시키기 위해서는 정답과 추정된 무언가를 비교한 Loss가 매우 중요하다. 우리는 이 Loss를 모델의 원하는 학습 방향성으로 두고 있기 때문이다. 그리고 좀 더 원하는 결과의 방향성이 있다면 새로운 Loss를 추가해서 Multi Loss로 학습하게 된다. 이때 우리는 모델이 두가지 로스를 모두 만족시켜 최고의 성능을 보여주기를 원하지만, 항상 원하는 성능이 나오는 것은 아니다. 두가지 로스가 서로 충돌하며 오히려 두가지 모두 성능이 안좋아진다거나 하나만 유독 성능이 좋다거나 하는 결과물이 대부분인 경우가 많다. 이러한 Multi Loss의 문제를 잡고자 한 것이 이 소개해드리는 논문의 주요 Contribution이다.
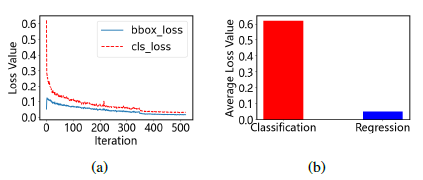
Object Detection은 딥러닝이 발달한 이후로 줄곧 많은 관심을 받으며 성장을 해오고 있다. 이Object Detection은 딥러닝에서 크게 Object의 위치를 찾는 Location Regression과 Object의 종류를 맞추는 Classification 이 두가지를 동시에 진행한다. 따라서 현재 두가지 Task를 모두 성능을 높이기 위해서 Regression Loss와 Classification Loss두가지를 Multi Loss로 사용하고 있다. 두가지 로스 각각 다양한 종류가 있지만 그래도 각각 큰 틀은 유지하고 있다. 하지만 이 두가지 로스는 위에서 말한 Multi Loss의 문제점을 보여주고 있다. 그림 1의 (a) , (b)를 보면 Classification Loss의 초기 스케일이 매우 커 학습의 좀더 지대한 영향을 끼치고 있는 것을 볼 수 있다.
이러한 Multi Loss의 문제점을 Object Detection 에서는 Objective Imbalance라고 부른다. 이 Objective Imbalance를 바로 잡기 위해서 소개하는 이 논문에서는 Adaptive Loss Weight Adjustment (ALWA) 를 제안한다.
- Adaptive Loss Weight Adjustment (ALWA)
1.1 Task Weighting
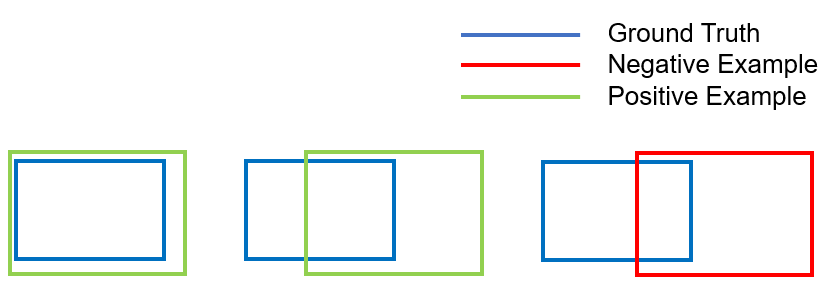
Object Regression Loss와 Classification Loss는 많은 연관이 있다 이는 그림 2를 보면 알 수 있는데, 윈도우를 슬라이딩 되면서 로케이션이 GT 와 멀어지면 Classfication 또한 다흐게 판단하게 된다, 이것은 두 Loss가 연관이 있다는 것이고 이러한 결과를 나타낼 경우 단순히 두 Loss를 더해서 Total Loss로 계산 하는 것은 Objective imbalace 문제를 해결 할 수 없다는 것을 의미한다고 한다.
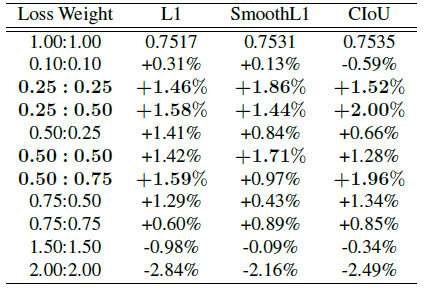
L1, SmoothL1, GIoU, DIoU, CIoU와 같이 Box Regression을 위한 Loss 는 여러가지가 있는데 표 1과 같이 Reggression 과 Classification을 합칠때 Weight를 어떻게 두고 합치느냐에 따라서 각 방법론의 성능은 달라진다고 한다. 또한 데이터셋이 바뀔때마다 Loss Weight도 다 바뀌어야하는 것이 문제라고 하며 이를 해결하기 위해서 두 Loss의 경향성 부터 먼저 분석해봤다고 한다.
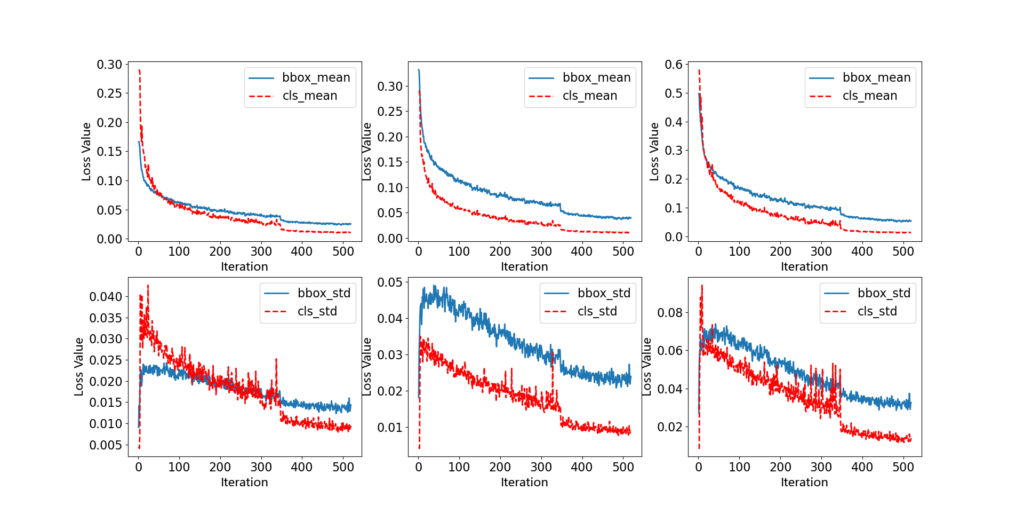
그림 3은 두 로스의 비율이 다를 때 로스의 경향성을 본 것이다. 이 것과 표 1을 보고 총 세가지의 결과를 도출해냈다고 한다.
- Classfication Loss 가 떨어지는 폭이 Regression 보다 커야 한다.
- 로스는 1보다 작아야한다.
- Classfication Loss와 Regression Loss의 폭은 크게 차이 나선 안된다.
위 세가지를 지키는 Loss Weight를 사람이 정하며 찾지 않고 학습하며 찾기 위해 다음과 같은 알고리즘을 썼다고 한다.
1.2. Algorithm Description
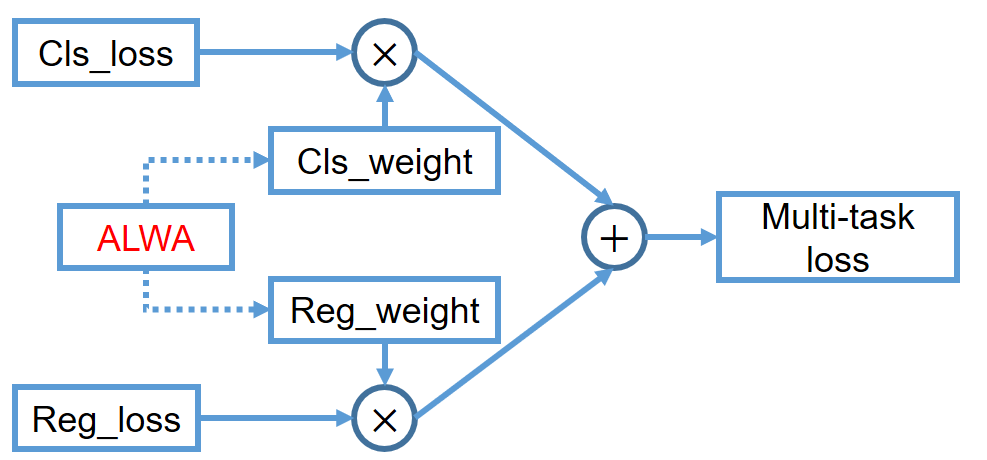
Classification Loss와 Regression Loss를 그림 4와 같이 Weight를 주고 Fusion 해준다. Weight를 구하는 방식은 다음과 같다.

- Weight 를 처음에는 1:1로 고정한다.
- C iteration을 돈 후 만약 Cls가 Reg 보다 크다면 cls weight를 조정해서 Cls가 더욱 작도록 조정해준다.
Result

그림 6은 RetinaNet에 ALWA를 적용하고 성능을 본 결과 ALWA를 적용 하니 False Positive 가 준것 을 알 수 있다.
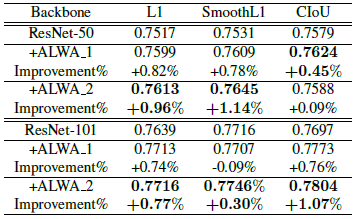
ALWA를 적용했을때 거의 모든 상황에서 성능이 오른 것을 볼 수 있다.
리뷰를 보니 ALWA_1이 있고, ALWA_2로 보입니다. 성능지표 결과 또한 ALWA_2가 더 좋은 성능을 가진 것 같습니다. 리뷰에 기재된 알고리즘은 ALWA_1에 대한 설명 같네요. 추가로 설명 부탁드립니다.
_1과 _2는 원스테이지냐 투스테이지냐 차이입니다
리뷰를 읽어보니 classification loss와 regression loss의 scale에 따라 adaptive한 weight를 주는 방식으로 이해를 했습니다.
그런데 맨 위의 두 loss 그래프를 보면 처음에만 scale 차이가 크고 이후에는 이 차이가 적어지는 것으로 봐서는 제안된 ALWA는 학습 초반에만 영향을 미치고 이후에는 영향이 미미한가요? 이를 설명하는 ablation study가 따로 있을까요?
그림 3을 말씀하시는건가요? 그거면 ALWA를 적용안한겁니다