2017년에 발표된 Mask R-CNN에 대해 리뷰하겠습니다.
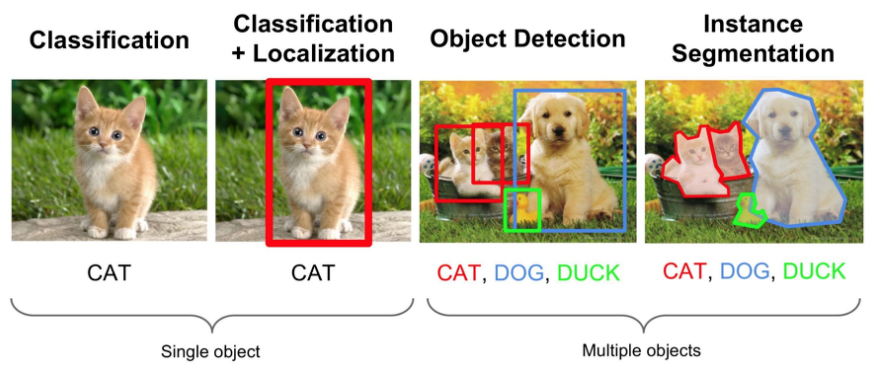
Instance Segmentation 는 Semantic Segmentation과 달리 아래 그림처럼 같은 class 중에서도 instance 별로 구별하는 task 입니다.
본 논문에서는 instance segmentation의 방법론으로 Mask R-CNN을 제안하였습니다.
Introduction
Mask R-CNN은 Instance Segmentation을 수행하기 위한 모델이다. 저자는 논문에서 간단하고 직관적인 모델임을 강조하는데, object detection을 위한 Faster R-CNN에 segmentation mask를 예측하는 branch만 추가한 것이기 때문이다. 앞서 서술하였듯 segmentation mask를 예측하는 branch를 class와 bbox를 예측하는 모델에 병렬로 추가하는 것이므로 작은 overhead를 가진다는 장점이 있다. 다만 기존 Faster R-CNN과의 차이는 크게 세 가지가 있는데, 이는 다음과 같다.
- bbox 예측하는 branch에 병렬로 mask prediction branch 추가
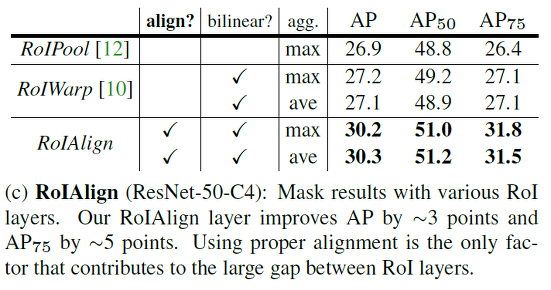
- RoIAlign : RoIPool 대신 RoIAlign 사용하여 각 pixel에 대한 정확한 위치 정보 유지
- mask와 class prediction 분리 (class와 관련 없이 segmentation)
기존 Faster R-CNN은 RoIPool을 사용함으로써 input과 output간의 pixel 간 align을 고려하지 않았지만 여기서는 RoIAlign을 사용하여 정확한 위치정보를 담아 높은 성능 향상을 보였다고 한다. 자세한 구현 원리는 뒷장에서 서술하였다.
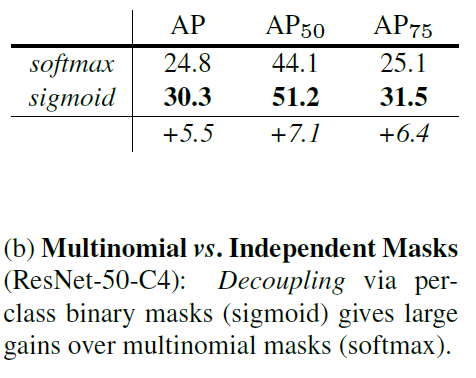
Mask prediction과 class prediction을 분리하였다. 이를 통해 mask prediction은 multi class들을 고려할 필요 없이 binary mask에 대해 predict 하면 되기 때문에 성능 향상을 가져왔다고 한다.
Mask R-CNN
Mask R-CNN은 Faster R-CNN과 동일하게 2-stage며 RPN은 동일하게 사용한다. 그리고 class와 box를 동시에 예측하는 두번째 stage에 각 RoI에 대한 binary mask를 예측하는 branch를 추가한다.
최근 연구는 class와 mask를 동시에 예측하지만, 본 논문에서는 그렇지 않다. Faster R-CNN에서 나온 bbox를 기반으로 segmentation을 실행하기 때문에 segmentation mask에서는 class를 고려할 필요 없이 binary mask로 예측한다.
RoIAlign
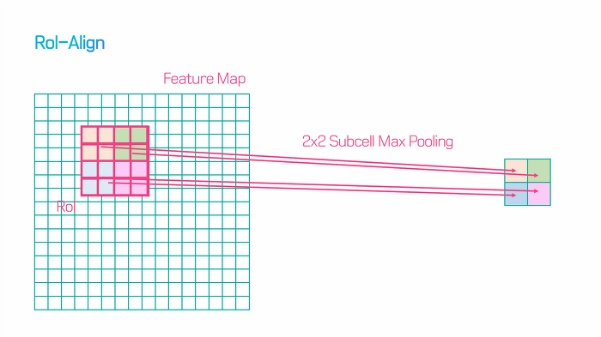
RoI Pool에서는 RoI가 소수점 좌표를 가질 경우 반올림해서 Pooling 진행하는데, 반올림함으로써 원래 위치 정보가 왜곡되기 때문에 정확하게 pixel-by-pixel로 detection 해야하는 segmentation task에서는 문제 발생한다. 따라서 RoIAlign을 통해 pixel의 본래 위치 정보를 보존할 수 있도록 하였다.
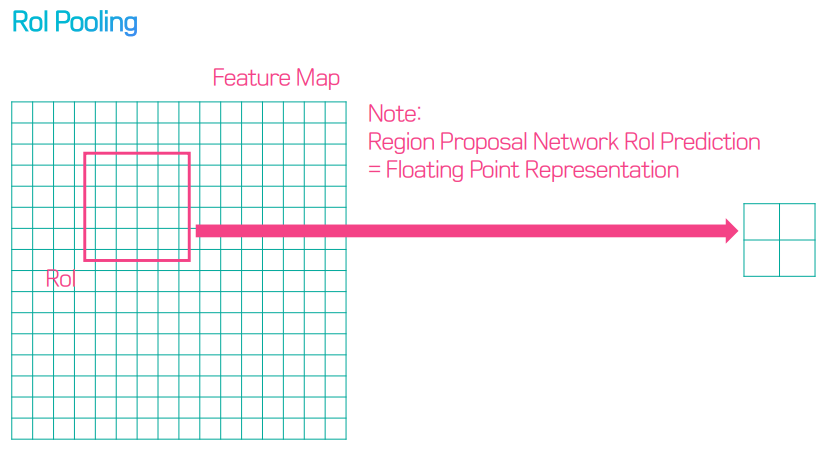
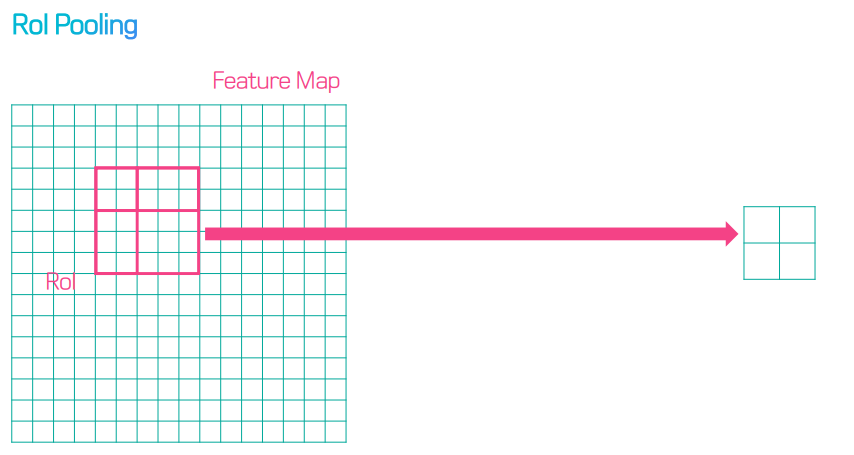
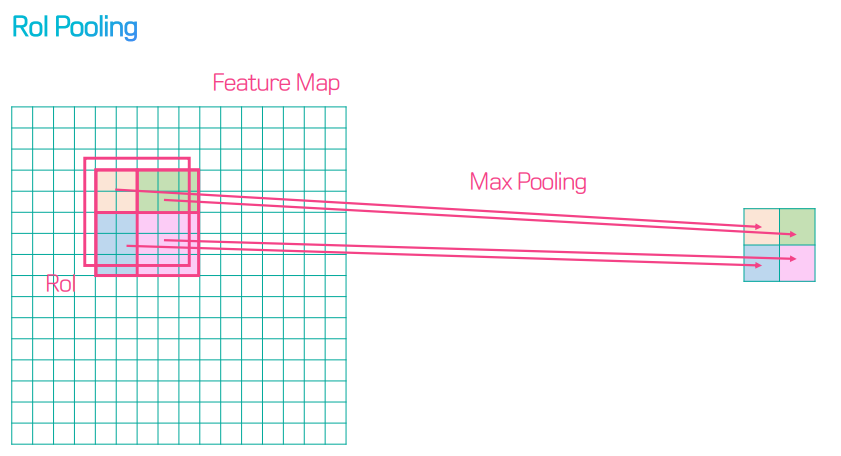
따라서 정보가 왜곡되는 RoI Pooling 대신 RoI Align을 사용한다.
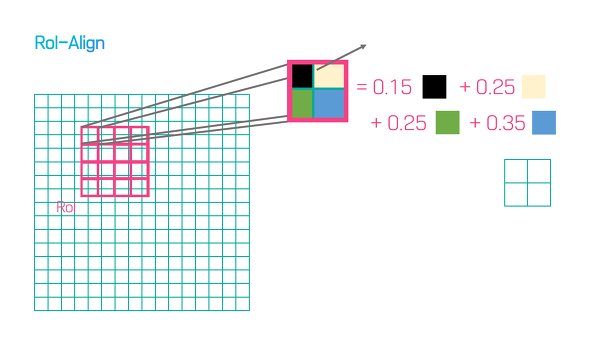
RoI Align에서는 아래 화살표처럼 원래 피처맵의 포인트로부터 bilinear interpolation을 하여 점의 값을 구한다.

아래 그림처럼 4개의 피쳐가 차지하고 있는 비율을 곱한 후 max pooling 하여, 원래 위치 정보를 최대한 반영하는 bilinear interpolation을 수행한다. 이로 인해 mask accuracy가 크게 향상되었다고 한다.
즉 RoI를 비롯한 Mask R-CNN의 순서는 다음 그림과 같다.
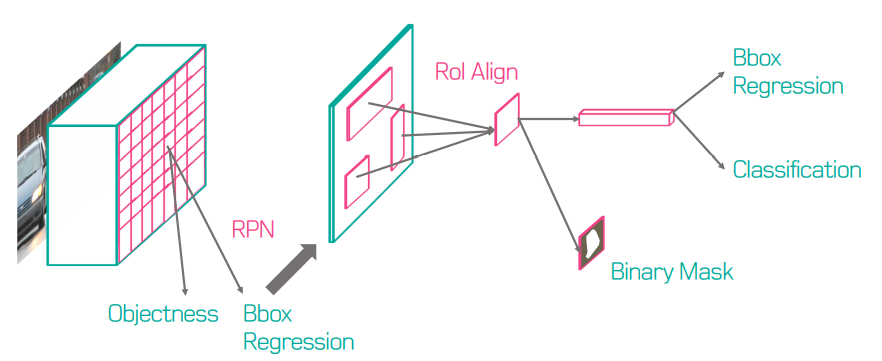
Network Architecture
네트워크 구조는 크게 두 가지로 나뉜다.
-
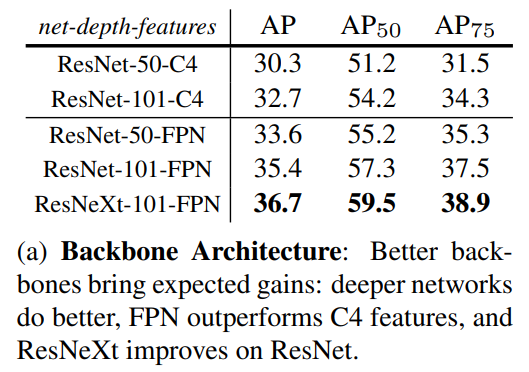
Convolutional Backbone Architecture
- ResNet
- FPN : 다른 층들에서 RoI 피처 추출. 나머지는 resNet과 비슷 ⇒ ResNet-FPN
-
Network Head : bbox(cls & reg), mask 예측
- 각각의 RoI에 mask segmentation을 하는 Fully Convolutional Network(FCN)을 추가하였다.
Mask R-CNN Loss Function
loss는 매우 간단하다.
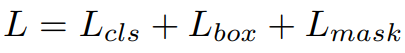
(L_cls와 L_box는 Fast R-CNN에 정의된 것과 동일한 classification loss와 bounding-box의 loss이다.)
- L_cls : Softmax Cross Entropy (loss of classification)
- L_box : bounding-box regression
- L_mask : Binary Cross Entropy
Experiments
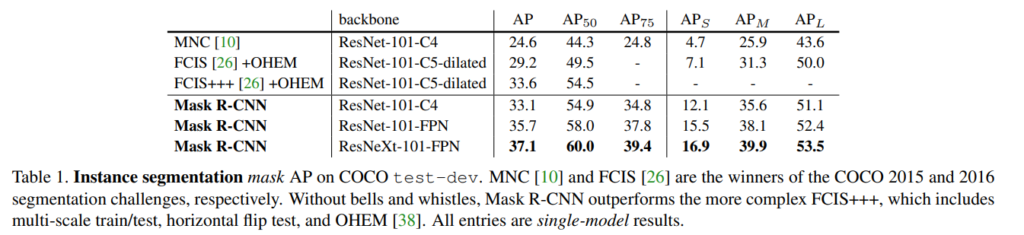
그러나 Mask R-CNN은 Detect된 bbox를 기반으로 segmentation을 하기 때문에 bbox가 탐지되지 않으면 segmentation이 불가능하다는 단점이 있다고 한다.
Reference
PR-057 Mask R-CNN : https://www.slideshare.net/TaeohKim4/pr057-mask-rcnn
마침말
순서가 조금 이상할수도 있지만, 다음에는 Mask R-CNN을 읽으면서 이해가 안되던 Faster R-CNN에 대해 찾아보고자 합니다.
저자는 논문에서 계속 Faster R-CNN에 mask 예측만 추가한 것이니 간단하다고 언급하는데, 정작 이 논문을 읽는 저로서는 Faster R-CNN에 대한 이해가 부족하니 전혀 간단하지 않더군요.
그래도 instance segmentation이라는 task를 알아보는 색다른 경험이 되었던 것 같습니다.
게다가 이 모델이 pose estimation에도 꽤나 좋은 성능을 가져왔다 그러니 이것에 대해서도 찾아보고 싶다는 생각도 들더군요. 아무튼 이 task도 object detection을 기반으로 확장되었다니 놀라지 않을 수 없었던 것 같습니다.
L_mask : Binary Cross Entropy
mask의 loss가 단순히 BCE로 구해지는 것인가요?
+표 [3]에 mask와 class를 분리함으로써 binary mask 예측을 사용한 결과
라고 했는데 mask prediction에서 binary mask(sigmoid)와 multinomial mask(softmax)를 사용했을 때의 결과를 비교한 것이라고 생각되는데 같은 의미인가요 ?
질문 감사합니다.
첫번째 질문에 대해 답변하자면 RPN을 통해 나온 bbox 안에서 segmentation을 하는 것이기 때문에 object인지 아닌지에 대한 binary 예측을 합니다.
또한 추가 질문으로 생각하신 것과 같이 sigmoid와 softmax를 비교한 것이 맞습니다 🙂
홍주영 연구원님 리뷰 잘 읽었습니다.
명료하게 작성 해주셔서 이해하는 데 헷갈리는 부분 없이 잘 읽었던 것 같습니다.
최근 연구는 instance segmnetation 수행 시 masking과 class 예측을 동시에 진행한다고 설명해주셨는데 최근 연구 방향이 그렇게 전환된 이유와 어떤 게 그걸 가능케 하였는지가 궁금합니다.
본문의 내용 중 다음 글을 보고 질문 주신 것 같습니다. (저도 너무 예전에 작성한 거라… 말이 좀 헷갈리네요)
“최근 연구는 class와 mask를 동시에 예측하지만, 본 논문에서는 그렇지 않다. Faster R-CNN에서 나온 bbox를 기반으로 segmentation을 실행하기 때문에 segmentation mask에서는 class를 고려할 필요 없이 binary mask로 예측한다.”
이 얘기를 아래와 같이 다시 해석(?) 할 수 있을 것 같습니다.
“다른 연구들은 segmentation mask를 multi-class 분류 문제처럼 다루지만, Mask R-CNN은 class 예측은 classification branch에서 하고, mask는 각 class마다 독립된 binary mask를 예측하는 방식으로 처리한다. 즉, segmentation branch 자체에서는 class 정보를 직접 고려하지 않는다. ”
결국 Mask R-CNN의 핵심 설계인 class prediction과 mask prediction의 분리을 강조한 것이죠. 이제 지연님이 질문 주신 것에 답변드리자면..
Q. 최근 연구에서 masking과 class를 동시 예측으로 전환된 이유?
과거 방식(Mask R-CNN 포함)은 classification과 mask prediction을 분리하여 처리했습니다. 즉, box 분기에서 class를 예측하고, 각 class별로 독립적인 binary mask를 예측한 뒤, 해당 class에 맞는 mask를 선택하는 구조였습니다. 이 방식은 학습이 안정적이고 구조가 직관적이지만, segmentation branch 자체는 class 정보를 직접 활용하지 못한다는 한계가 있었습니다.
최근 연구에서는 이러한 분리를 없애고, mask branch에서 바로 class-aware mask를 출력합니다. 예를 들어 per-pixel softmax를 통해 multi-class mask를 직접 예측하거나, class-aware mask embedding을 통해 하나의 branch에서 동시에 segmentation과 classification을 처리합니다.
Q. 그렇게 전환이 가능하게된 이유는 무엇인가요?
여러 이유가 있을 것 같은데요,
(1) Backbone과 feature head의 표현력이 좋아져서, 하나의 출력에서 mask와 class 정보를 동시에 반영이 가능하다는 것
(2) 새로운 모델 구조 (예를 들어 DETR) 등장으로, object query가 class 정보를 포함해, mask와 class를 동시에 예측 가능하다는점
결국 연구가 더 심도있어지면서 2-stage 보다는 end-to-end가 가능하도록 연구를 추구한다는 점 등 다양한 이유로 학습 과정이 간단해지고 발전하는 것 같습니다