해당 논문은 Point cloud로부터 Semantic Segmentation을 푸는 방법이며, Point의 geometry 정보와 point로부터 feature를 추출한 정보 같이 사용한 Point based method로 SOTA를 달성한 방법론입니다.
Method
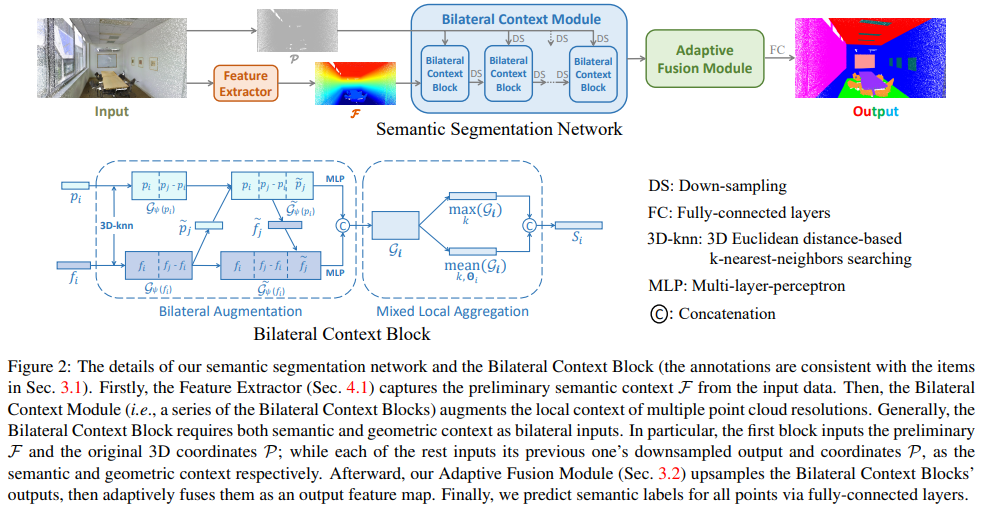
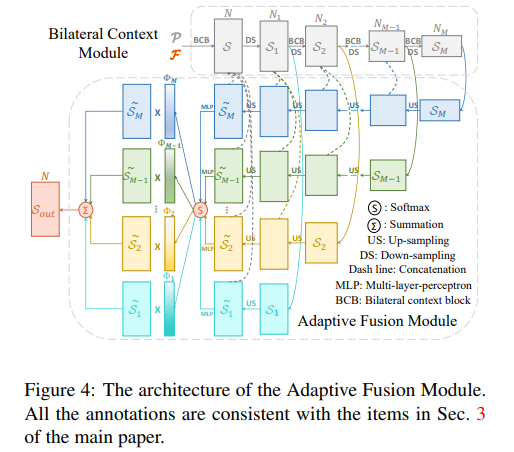
해당 논문의 키 컨셉은 3D point의 geometry 정보와 Point로부터 추출한 feature 정보를 융합함으로써 풍부한 정보들을 유지하고, Fig 4와 같이 스케일마다의 정보를 결합함으로써 스케일에서의 정보를 유지하는 것에 있습니다.
Key Module
Bilateral Context Module
3차원 정보를 가진 많은 데이터들은 3D point cloud 정보외에도 RGB color, light intensity 등을 같이 제공해줍니다. 이러한 정보들도 3D scene을 이해하는데에 매우 중요한 정보입니다. Bilateral Context Module은 geometry 정보와 context를 모두 이용하며, 적절하게 융합함으로써 3차원 scene에 대한 이해를 키우고자 합니다.
Bilateral Augmentation
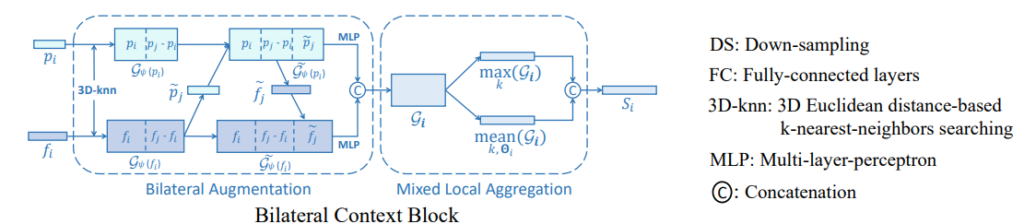
Scene에서 측정된 모든 Point cloud를 사용하기에는 어려움이 존재합니다. 너무 많은 정보를 가지고 있고, 클래스를 분류하는데에 있어서도 비효율적인 면이 있습니다. 해당 방법론에서는 point cloud를 3D KNN을 이용하여 비지도 학습을 진행합니다.(KNN시 point cloud에 해당하는 feature도 포함하여 정보를 가져갑니다.)
그 후, local geometric context in 3D space
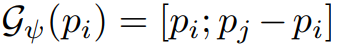
local semantic context in feature space
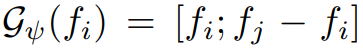
를 구하면서 각 feature의 정보와 상대적인 정보를 내포한 context를 생성합니다.
이를 통해서 point와 주변 포인트 간의 geometry와 feature 정보를 가질 수 있지만, 이는 주변을 표현하기에는 비효율적 입니다. 이는 2가지 이유를 들 수 있습니다.
- 고정된 차원을 가진 local geometric context in 3D space(p는 x, y, z)는 고차원인 feature space에서 약한 일반화 능력을 가지게 됩니다.
- KNN을 이용하여 얻어진 local semantic context in feature space는 가까운 영역과 중복된 표현을 가지게 됩니다.
이러한 두가지 문제를 해결하기위햇 해당 방법론에서는 두 정보를 고려한 augment를 제안합니다. 먼저 각각의 feature를 유연하고 각자의 feature에 맞도록 만들기위해서 MLP를 이용한 Feature Extract를 사용합니다.
해당 방법론에서는 이러한 정보들은 같이 사용하기 위해서 MLP를 이용합니다.
수식 (1)의 MLP는 풍부한 segmentic 정보(고차원 정보)를 가진 G(fi)를 이용하여 3DoF(pi) 예측을 목적으로 설계됩니다. 그럼으로써 양측면을 고려한 이웃 ~pj를 만들 수 있습니다.
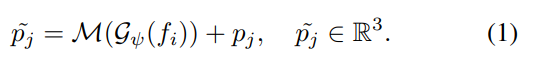
수식 (2)에서는 geometry 정보를 이용하여 feature를 예측하는 MLP를 이용하여 이웃 feature 정보 fj를 결합함으로써 양측면을 고려한 이웃 feature ~fj를 만듭니다.
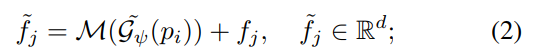
(위의 식에서 M은 아래 수식 형태의 MLP를 의미하며, 구체적인 구조 conv와 BN-ReLU가 결합된 MLP입니다.)
그 다음, 아래의 수식과 같이 geometry 정보와 feature 양측면의 정보가 고려된 Bilateral Augmented context를 생성함으로써 두 정보간의 애매모호한 관계를 해소합니다.
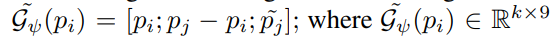
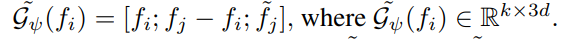
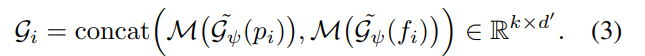
Mixed Local Aggregation
양측면을 고려한 정보를 토대로 효율적이게 local information을 요약하여 표현 할 수 있습니다. 하지만 아직도 가까이에 위치한 point들은 유사한 context를 가지기 때문에 차별성을 가지기에 부족합니다. 이러한 문제를 해결하기 위해서 k neighbor를 모두 고려하여 가장 maximum 값을 가진 값을 획득하는 max term과 전체적인 context를 고려한 mean term을 두어 차별성을 더 이끌어냅니다.
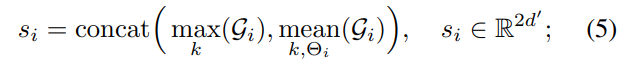
Adaptive Fusion Module
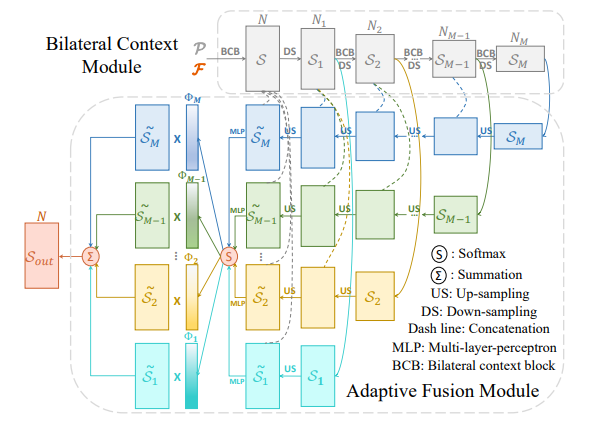
Adaptive Fusion Module은 간단합니다. UNet과 유사한 형태를 가진 모듈로 encoder-decoder 형태에 같은 scale을 가진 feature map들은 concat 해줌으로써 각 scale을 정보를 가진 상태에서 upsampling을 진행하는 구조를 가집니다.
약간의 다른 부분은 Point-level에서의 정보를 획득하기 위해서 마지막단 feature map을 모두 결합, MLP를 태운 후, SoftMax를 적용합니다. 그 후, 마지막단 레이어에 곱해주어 Self-attnetion과 같은 효과를 가집니다. 그 후, 모든 feature map를 더해 geometry와 context(color) 양측면이 고려된 정보와 스케일이 고려된 최종 feature map S_{out}를 획득합니다.
Loss
Loss는 크로스 엔드로피와 모든 Bilateral Context Block(수식 (7)에서는 m /in M)에 적용되는 수식 (4)로 구성됩니다. 수식 (4)는 수식 (1)의 feature(color)로부터 3DoF를 예측하는 MLP에 적용됩니다.
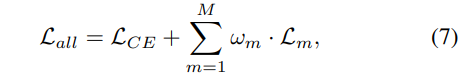
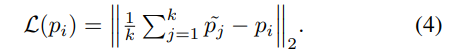
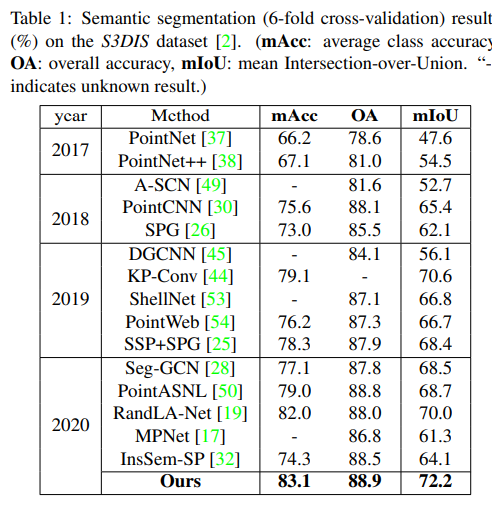
Experiments
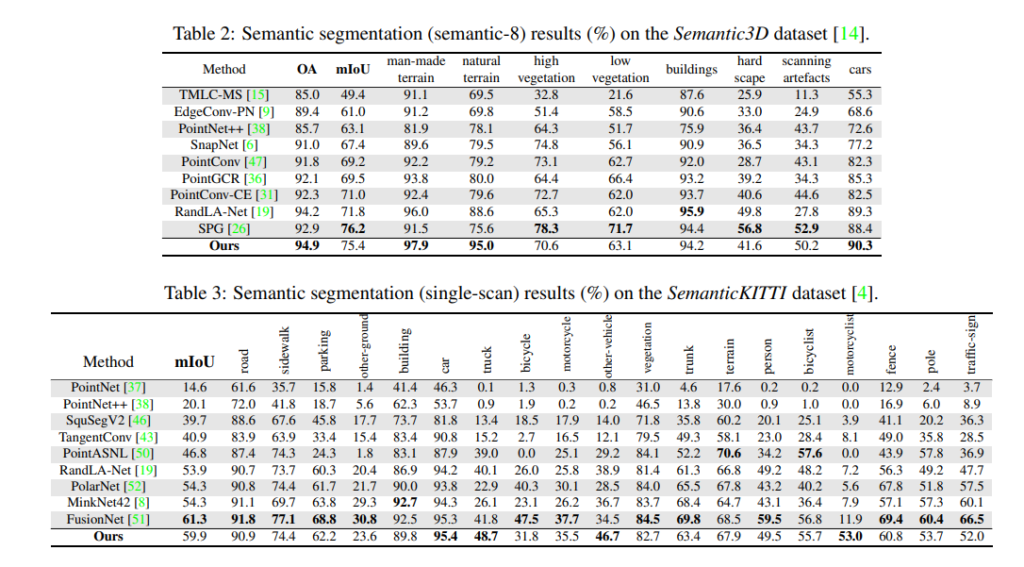
================================================================
color 정보와 3D 정보를 MLP를 이용한 방법은 정말 참신한 방법으로 보인다.
이후 VIO에도 적용 시, 영상 정보와 IMU 정보를 융합하는 방법에 고려해보는 것도 좋아보인다.