

최근 NLP 분야에서 CNN이나 RNN과는 구조가 아예 다른 self-attention 기반 방법론인 Transformer가 등장했고 좋은 성능을 내며 SOTA를 달성하고 있습니다. 더불어 컴퓨터비전 분야에서도 이러한 Transformer 구조를 응용해 ViT(Vision Transformer), DeTR(Detection Transformer)와 같은 방법론들이 Image Classification과 Object Detection좋은 성능을 보이며 등장하였습니다.
그러나 컴퓨터비전 내에서 NLP와 가장 유사한 특징이 많은 Video 관련 Task에서는 Transformer를 활용한 방법론이 최근까지 제안되지 않았으며 여전히 2D, 3D CNN이 주를 이루고 있었습니다.
Video 관련 Task에서 Tranformer에 대해 진전이 없던 와중, 2021년 2월 말 Facebook에서 TimeSformer라는 이름으로 Transformer를 Video action recognition에 적용한 방법론을 처음으로 제안하였고, 이 방법론은 현재 기존의 방법론들을 제치고 SOTA를 달성하게 되었습니다.
기존 Video action recognition에서 주로 사용되던 CNN과 비교했을 때 Transformer 다음과 같은 세가지의 장점이 존재합니다.
- CNN은 Inductive bias가 강하지만 Transformer는 상대적으로 Inductive bias가 약하다.
Inductive bias는 처음 보는 문제를 해결하기 위한 추가적인 가정을 의미합니다. Inductive bias가 강하다면 데이터 셋의 크기가 적어 표현할 양이 적다면 충분히 유용하나 데이터 셋 크기가 커졌을 때 모델의 표현력을 특정 가정 내의 제한한다는 단점이 있습니다.
예를 들어 CNN의 경우 Locality에 대한 강한 가정이 존재합니다. 당연히 컴퓨터비전에서 사용하니 지역적인 정보가 유의미하다는 가정하에 Local 정보를 Convolution 연산으로 aggregation하기 때문입니다. 그러나 이러한 가정하에 설계된 모델은 한번에 모든 정보를 보는 것이 아닌 주변 정보를 참고하며 연산하기에 모델의 깊이가 깊지 않다면 Global한 표현력이 떨어지게 됩니다. Transformer는보를 Convolution 연산으로 aggregation하기 때문입니다. 그러나 이러한 가정하에 설계된 모델은 한번에 모든 정보를 보는 것이 아닌 주변 정보를 참고하며 연산하기에 모델의 깊이가 깊지 않다면 Global한 표현력이 떨어지게 됩니다.
Transformer는 Self-attention 기반으로 입력의 모든 정보를 활용할 뿐 추가적인 가정이 부족하여 약한 Inductive bias를 지닙니다. 이러한 이유로 Transformer 기반 모델은 대용량 데이터 셋을 표현할 때 좀더 강인하게 작동합니다.
- CNN은 long-range dependency를 파악하는데 제약이 있으나 Transformer는 feature를 직접적으로 비교해 short-range 뿐만 아니라 long-range dependency를 파악하는데 이점이 있다.
앞서 설명한 내용과 비슷하게 CNN은 Local 정보를 aggregation 하며 기술하기 때문에 특정 정보와 그에 멀리 떨어져 있는 정보(long-range)를 비교할 때 독립적으로 두 정보만 사용하는 것이 아닌 둘 사이의 정보에 의존성을 띄게 됩니다. 그러나 Transformer는 self-attention 방식을 활용해 feature 끼리 비교하기 때문에 short-range와 long-range 정보 모두 독립적으로 파악하게 됩니다.
- Transformer는 CNN에 비해 학습과 평가가 빠르다.
특히 Video 분야에서는 입력으로 들어가는 이미지가 많은데, 같은 비용 내에서 Transformer는 CNN에 비해 속도가 빠르기에 더 많은 데이터를 사용할 수 있다는 장점 또한 존재합니다.
본 논문의 저자는 이와 같은 장점들로 Transformer를 Video action recognition 분야에 적용하게 되었습니다.
1. The TimeSformer Model
Transformer를 적용하기에 앞서 기존 NLP의 Transformer는 모든 token 쌍 간의 유사도를 측정하는 방법을 수정하여 적용하였습니다. 이는 Video 내의 모든 patch 간의 계산 비용이 크다고 생각했기 때문이며 이를 이후 설명할 5가지로 변경해 설계하였습니다. 그러나 이를 설명하기 이전에 기본적인 구조를 처음부터 서술하겠습니다.
Input clip
입력으로는 Video 에서 샘플링된 HxW 크기의 F개 프레임이 사용됩니다.
Decomposition into patches
각 프레임은 이전 컴퓨터비전에 먼저 Transformer를 도입했던 방법론인 ViT의 방법을 따라 크기가 PxP인 N개의 겹치지 않는 patch로 나뉘며 N은 HW/(PxP)개가 됩니다. 그리고 구한 patch들을 flatten하여 3xPxP 길이의 vector로 변경하며 이를 x_{(p,t)}로 표현합니다. 여기서 p=1,…,N 으로 프레임 내의 위치를 의미하며, t=1,…,F로 프레임의 시간 순서를 의미합니다.
Linear embedding
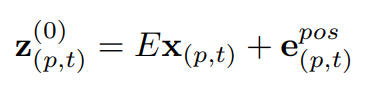
x_{(p,t)} 는 크기가 Dx3xPxP이며 learnable한 matrix인 E와 곱해져 선형 연산되며, 이에 크기가 D이며 learnable한 positional embedding인 e^{pos}_{(p,t)}가 더해져 크기가 D인 z^{0}_{(p,t)} 가 만들어 집니다. 이렇게 embedding된 z^{0}_{(p,t)} 를 NLP의 token과 같이 Transformer의 실질적 입력으로 사용하게 됩니다.
Query-Key-Value computation
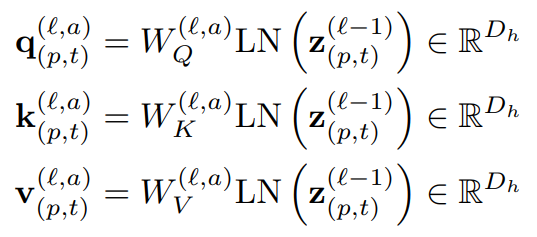
TimeSformer는 총 L개의 encoding block으로 구성되어 있으며 매 l block마다 z^{l-1}_{(p,t)}의 입력으로부터 query/key/value vector를 계산해나가게 됩니다. 식 (2)에서 LN은 LayerNorm을 의미하며 \alpha=1,...,A로 attention head의 인덱스를 의미합니다. 또한, 각 attention 모듈은 D_{h}=D/A 크기로 embedding 시키게 됩니다.
Self-attention computation
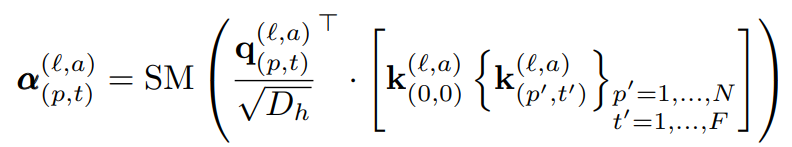
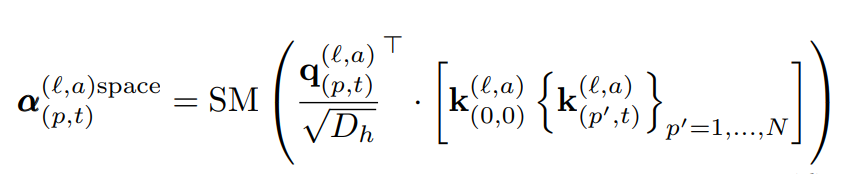
기존 Self-attention weight \alpha^{l,/alpha}_{p,t} 를 구하는 방식을 따르면 식 (3)과 같이 내적 연산으로 구성됩니다. 여기서 SM은 Softmax를 의미합니다. 식 (3)과 같이 계산하는 것은 총 NF+1 번의 연산을 하며 해당 장 서두에서 언급했던 것처럼 계산 비용이 커지게 됩니다. 저자는 이러한 계산 비용을 줄이기 위해 5개의 구조를 구성시 프레임 내의 위치 정보인 spatial 정보와 프레임 간의 순서 정보인 temporal 정보를 동시에 계산하지 않고 식 (4)와 같이 매번 따로 계산하는 방식을 도입하였습니다.
Encoding
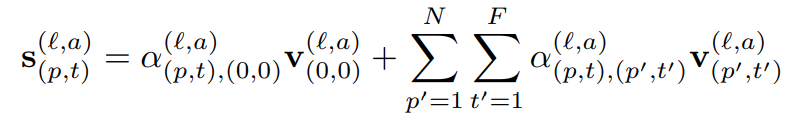
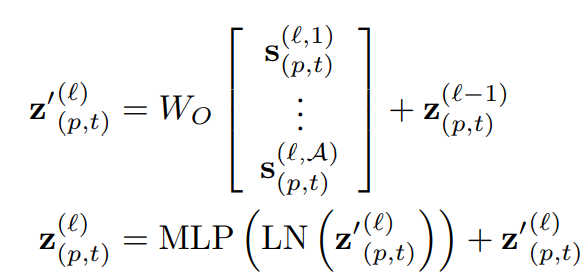
매 block에서 구해진 value vector와 query/key vector로 만들어진 Self-attention weight를 이용해 식 (5)와 같이 s vector를 계산하며 모든 attention head에서 나온 s vector를 concat한 뒤 MLP를 통과시킵니다. 이 때, 연산 전 vector와 연산 후 vector간의 residual conntection을 활용하며 이 과정은 식 (6)과 같습니다.
Classification embedding
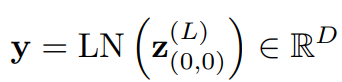
모든 block을 통과한 최종 결과 값에 LayerNorm을 해주며 하나의 MLP를 통과시켜 class마다의 confidence를 구하게 됩니다.
Space-Time Self-Attention Models

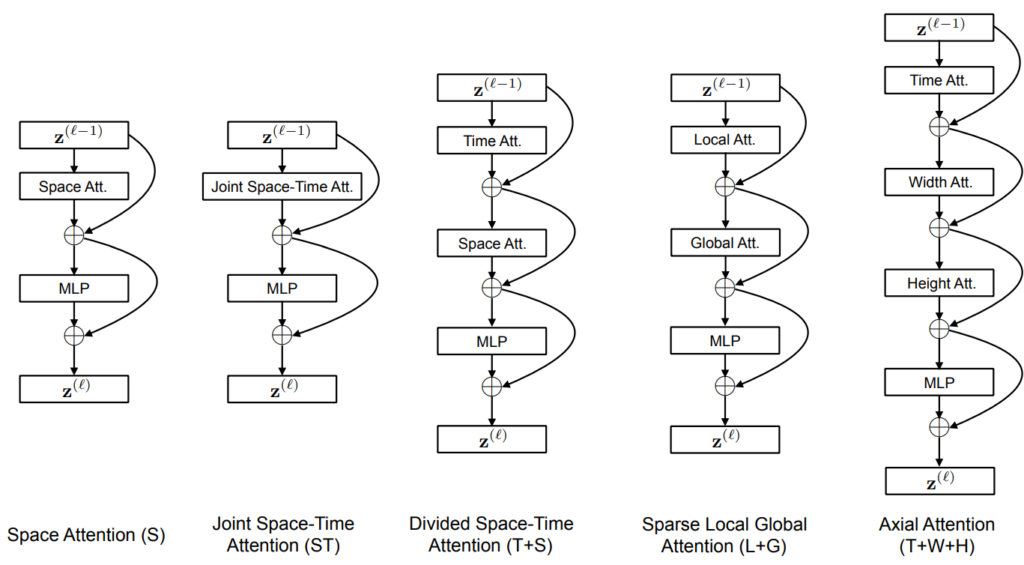
방금 서술했던 Transformer의 구조를 기준으로 이전에 언급했듯, 저자는 계산 비용을 줄이기 위해 5가지의 구조를 제안했으며 Fig 2와 같습니다.
- Space Attention (S)
ViT에서의 방식과 동일하고 한 프레임 내의 patch들에 대한 attention을 주는 방식이며 베이스라인으로 삼은 방식입니다.
- Joint Space-Time Attention (ST)
N개의 patch와 F개의 프레임을 모두 다 보는 방식이며, 계산 비용이 크다는 단점이 제기된 방법입니다. 다른 방법들과 성능 비교를 위해 추가된 듯합니다.
- Divided Space-Time Attention (T+S)
해당 patch에 대해 temporal attention을 계산하고 해당 프레임 내의 patch 들과 spatial attention을 계산하는 방식입니다. 이는 Space Attention, Joint Space-Time Attention과 비교될 수 있으며 계산 비용을 NF+1 번에서 N+F+2 로 줄이게 됩니다.
- Sparse Local Global Attention (L+G)
전체 프레임을 F x H/2 x W/2 크기의 patch로 나눠 기존 나눴던 N개의 patch에 대해 Local attention을 적용하며, 이후 temporal 하게 앞뒤 프레임에 대해 sparse한 Global attention을 적용하게 됩니다. 이를 통해 빠르게 대략적인 spatiotemporal attention을 적용할 수 있게 됩니다.
- Axial Attention (T+W+H)
우선 해당 patch에 대해 temporal attention을 계산하고 patch의 위치 기준 행, 열 순서로 놓여진 patch에 대해 spatial attention을 계산하는 방식입니다.
2. Experiment
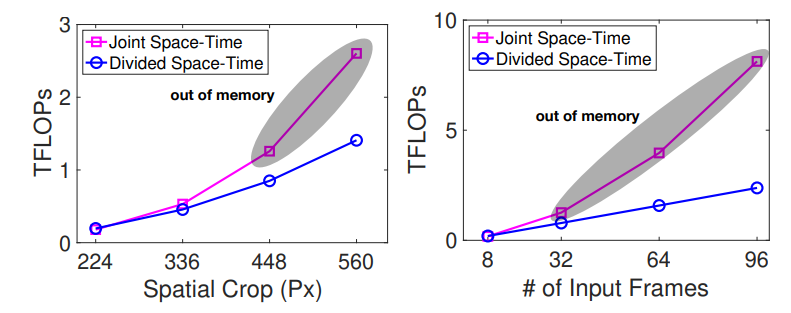
Fig 4는 spatial attention과 temporal attention을 동시에 적용할 때와 아닐 때의 입력 resolution 혹은 프레임 수에 따른 계산량을 의미합니다. 한 프레임의 패치가 많아지든, 프레임의 총 수가 많아지든 저자가 제안한 한번에 하나씩 attention을 주는 방식이 좀 더 높은 계산효율성을 갖는 것을 알 수 있습니다.
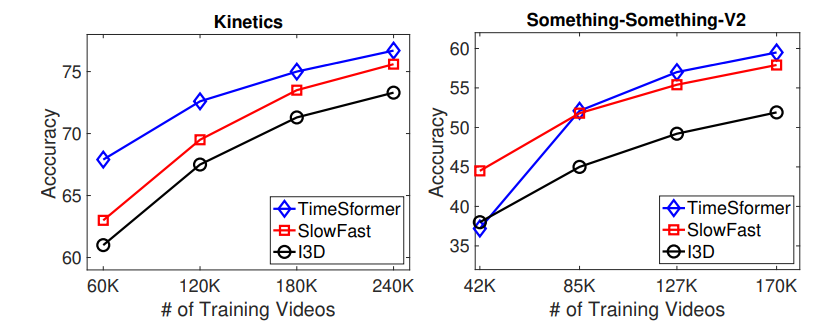
Fig 5는 Transformer가 약한 Inductive bias를 지녀 대용량의 데이터 셋일수록 강인한 표현력을 지니는 것을 뒷받침합니다. 기존 SOTA 방법론들보다 데이터가 많아져도 계속 높은 성능을 보이는 것을 알 수 있습니다.
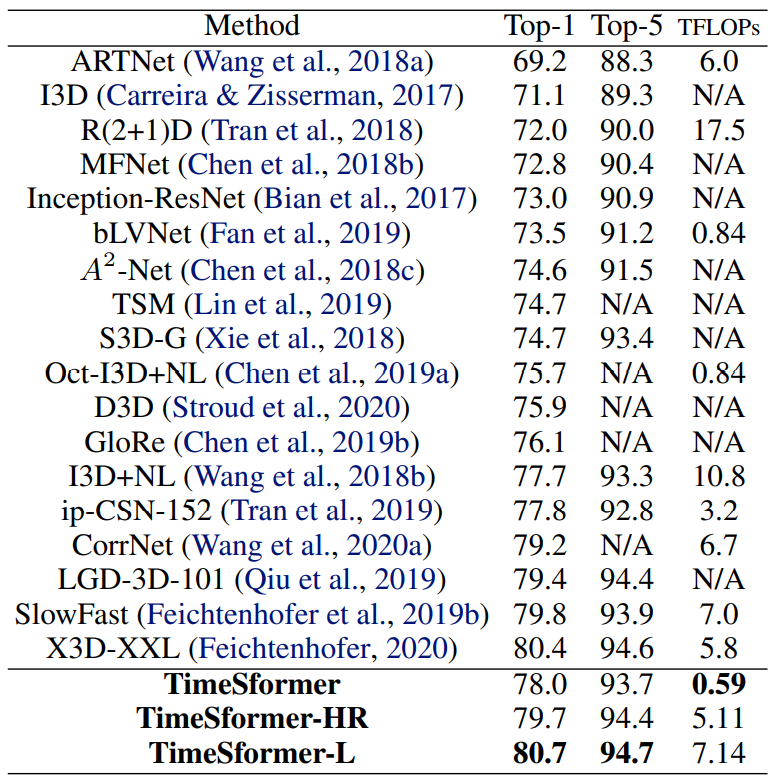

Fig 6과 7은 각각 Kinetics-400과 600에서 기존 CNN기반 SOTA 방법론들과의 성능 비교입니다. 여기서 TimeSformer는 default version으로 8x224x224 크기의 clip을 사용하였으며 TimeSformer-HR은 보다 high resolution으로 16x448x448 크기의 clip을 사용한 것을 의미합니다. 그리고 TimeSformer-L은 long range 이해를 위해 많은 프레임을 사용한 방법이며 96x224x224 크기의 clip을 사용하였고 앞선 두 방법보다 초당 샘플링 수를 4분의 1로 줄여 보다 넓은 범위를 입력으로 사용하게 됩니다. 서두에 서술하였듯이 기존 CNN 기반 SOTA 방법론들보다 성능도 우수하며 계산 효율성도 높은 것을 알 수 있습니다.
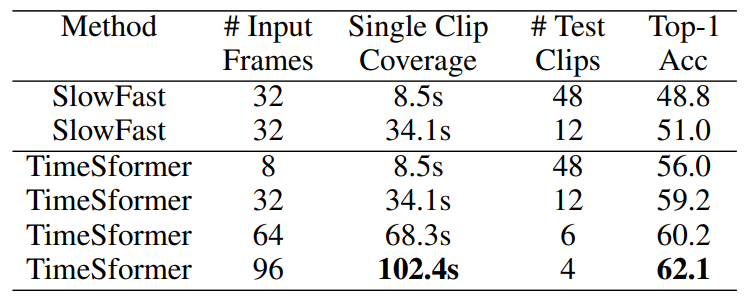
또 하나 주목할 점은 TimeSformer을 평균 7분정도의 video로 구성된 HowTo100M 데이터 셋에서 실험했을 때 성능이 높은 것뿐만아니라 각 clip이 수용가능한 프레임길이가 상당히 긴 것입니다. 기존 CNN 기반 방법론들은 해결하지 못하였거나 비용이 큰 메모리를 두어 Long-term video를 분석하려 했던 것에 반해 TimeSformer는 이를 보다 적은 비용으로 해결했다는 것이 이후 Long-term video 연구는 Transformer 기반으로 설계되지 않을까라는 생각이 들게 됩니다.
3. Reference
[1] https://arxiv.org/pdf/2102.05095.pdf
[2] https://robot-vision-develop-story.tistory.com/29
Transformer의 기여는 기존 re-current 정보를 전달하는 방법이 아닌 고려할 current 정보 근처 정보들의 상관성을 고려한 attention을 제안함으로써 행렬 연산에 최적화된 기법을 제안한 것에 있다고 생각합니다.
그렇기에 attention을 구한 정보의 space가 중요해 보입니다.
ViT인 경우 영상 분류 문제를 푸는 것이 목적이기에, 영상의 2차원 공간에서 나눈 patch를 사용했고,
해당 방법론은 비디오 문제를 푸는 것이 목적이기에, 비디오의 temporal 정보도 사용한 것으로 이해를 했습니다.
그렇기에 정보의 어떤 공간으로부터 attention을 볼지에 대해 방법을 제시한 Fig3의 방법을 이해하는 것이 중요해 보이는데요.
여기서 말하는 self-attention, spatiotemporal -attention, teporal-attention에 대한 설명이 없어 충분한 이해가 힘들었습니다. 나중에 시간이 되신다면 Fig 3에 대해 설명을 풀어 주시면 감사드리겠습니다.
self-attention은 input 차원에 대한 가중치를 input으로 만들어 적용하시는 것이라 이해하시면되며
spatiotemporal-attention이란 spatial attention이랑 temporal attention을 같이 적용하는 것을 의미합니다.
spatial attention은 한 frame 내에서 local하게 attention을 주는 것을 의미하며 temporal attention은 여러 연속된 frame에서 같은 위치에 해당하는 patch들끼리 attention을 주는 것을 의미합니다.
fig3의 경우는 attention이 적용되는 순서가 다름을 포인트로 보시면 좋을 듯하며, 만약 내부의 연산과정이 궁금하시다면 본문의 수식 부분을 참고하시거나 공식 github의 코드를 참고하시면 되겠습니다.