- 논문 소개
본 논문은 video understanding의 핵심적인 문제인 video action recognition task를 해결하기 위한 모델을 2D CNNs, 3D CNNs으로 나눈다. 본 논문은 2D CNNs는 비디오의 시간적 관계를 볼 수 없으며, 3D CNNs는 연산량이 많다는 단점을 문제상황으로 하여 2D CNNs 구조에 필요한 정보를 embedding 한 효율적인 모델을 제시하여 이러한 딜레마를 해결하였다고 제시하는 논문이다.
이때 모델이 action recognition 문제를 해결할 때 보아야하는 시간적인 정보들을 spAtio-temporal, Channel and moTion excitatION 세가지로 분류하여 정의하여 각 철자를 따 ACTION-Net이라 명명하였다.
위의 세가지 정보를 담기 위하여 세가지 경로를 갖는 모델을 제시하였는데 각 경로는 다음과 같다.
Spatio-Temporal Excitation (STE) path
Channel Excitation (CE) path
Motion Excitation (ME) path - 기존 흐름
기존의 흐름은 앞에 밝혔듯이 3D CNNs framework와 2D CNNs framework 두가지 흐름으로 나뉜다.
먼저, 3D CNNs은 sptio temporal modeling에 효율적이지만 적절한 정보를 캡쳐하는 것에 대해서는 부족했다. (전체적 정보를 이용하기는 하나 중요 프레임을 잘 선택한 것이 아닌 단순히 많은 정보를 보기 때문이라 해석하였다. 대표적인 예시로 keyframe 선택을 잘 하였을때 성능이 높아지는 연구들이 반례가 된다고 생각한다. 모델 작동에 혼란을 주는 데이터를 제거하였을 때 더 성능이 올랐기 때문이다.) 또한 3D CNNs 은 large-scale의 dataset (kinetics, moment in time, Activenet)이 공개되기 이전에는 차원이 높아짐에 따라 overfitting과 느린 수렴에 대한 문제점을 갖고 있었다.
둘째로 slowfast나 optical flow 정보를 보충하여 two-stream architecture를 갖는 모델은 two-stream을 이용하지 않는 모델보다 상당히 성능을 높였으나 연산량이 매우 많아 real-world applications 적용에 어려움이 있다.(본 논문은 VR과 같은 응용 프로그렘에 적용할 수 있는 모델을 중점으로 하고있다)
마지막으로 2D CNN based frameworks는 짧은 snippets에 주로 적용되는 가벼운 연산과정을 갖는다는 장점이 있지만, temporal modeling에 어려움을 겪는다는 근본적인 어려움을 갖고있다.
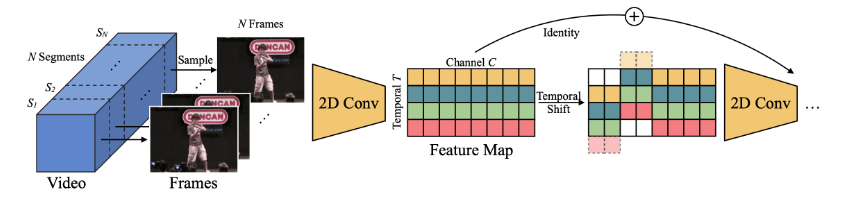
본 연구의 선행 연구라 할 수 있는 TSM 은 입력 데이터 channels의 일부를 temporal 축으로 shifting하여 2D CNNs 에 시간적( temporal ) 정보를 embedding 한 사례라 볼 수 있다.
기존의 연구에서 시간적 정보를 담기 위해 기존의 연구는 input level을 변형하였다. 예를 들어 slowfast는 느리고 빠른 sampling rate의 입력을 이용하였고 optical flow라는 움직임을 묘사한 데이터를 입력데이터로 사용하기도 했다. 이러한 흐름은 보통 연산량을 높이는 방향이라는 단점이 있다.
이를 반영하여 해당 연구는 “plug-and-play”(그림1에서 확인하듯이 하나의 모듈로 구현), “lightweight” 특징을 갖고자 하였고 feature level로 다중 정보를 다루는 접근을 시도하여, 다중 입력을 통한 시간적 특징 대응과 feature level 접근을 통한 경량화된 접근을 시도하였다. - Design of ACTION
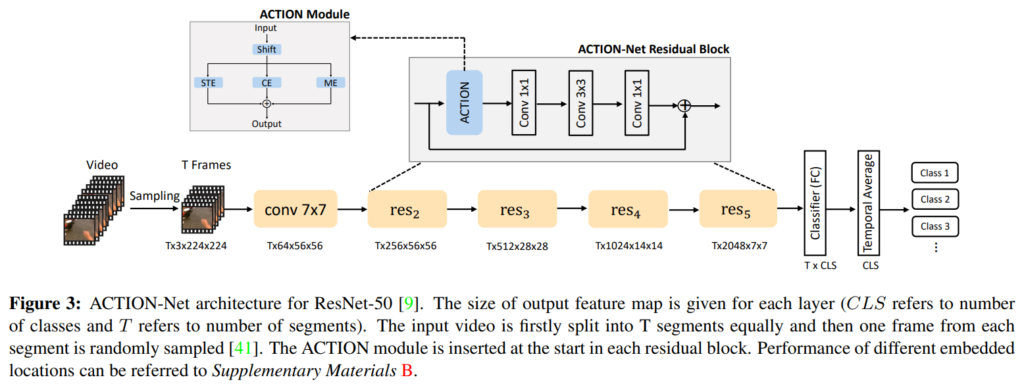
ACTION-Net을 구성하는 ACTION Module은 위에 언급하였듯이 Spatio-Temporal Excitation (STE), Channel Excitation (CE) and Motion Excitation (ME) 세가지 submodule로 구성된다. 각 모듈의 아키택쳐는 그림 2와 같다.
앞으로의 각 기호를 다음과 같이 정의한다. N (batch size), T (number of segments), C (channels), H (height), W (width). ACTION module은 기본적으로 (N*T, C, H, W)의 4D 입력을 받아 (N, T, C, H, W) 의 5D 입력으로 사용하며 다시 (N*T, C, H, W) 4D 의 출력값을 갖는다.
- STE
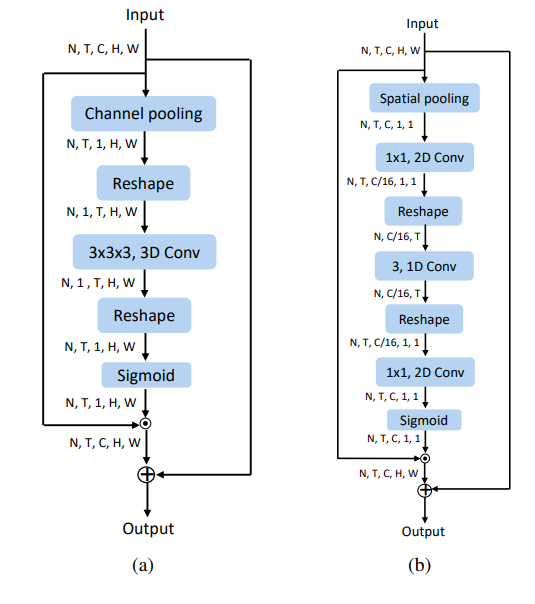
STE는 3D convolution 을 활용하여 video에서 spatio-temporal 정보를 추출하였다. - CE
CE는 그림 2의 (b) 구조를 갖는다. 이는 STE의 3D convolution 부분에 1D convolution구조를 갖으며 이 구조로 얻고자하는 시간적 정보의 특성은 입력 부분에서 확인할 수 있다. 처음 입력된 데이터(N, T, C, H, W)를 (N, T, C, 1, 1)의 형태로 표현하여 사용한다. 이후 채널값 C를 scale ration인 r 비율로 압축하여 (N, T, C/ r , 1, 1) 표현한다. 여기서 채널값이란 단순 RGB 3체널이 아닌 그림3과 같은 모델의 아웃풋 결과이다. 체널값을 직접적으로 융합시키면서 융합된 정보를 추출한다. - ME
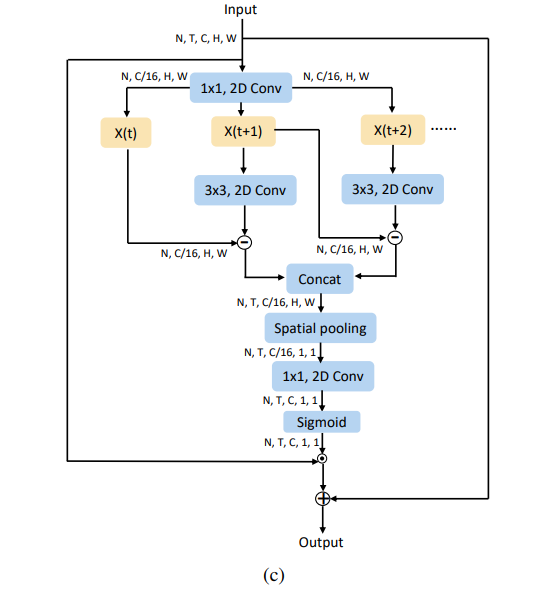
ME는 motion based 정보를 pixel level이 아닌 feature level에서 추출하고자 한다. STE 와 같은 로스라고 생각될 수 있지만, 입력단이 아닌 feature level을 이용하여 구별된 로스로 적용된다.
4. Ablation study
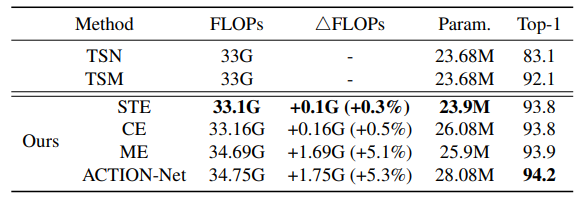
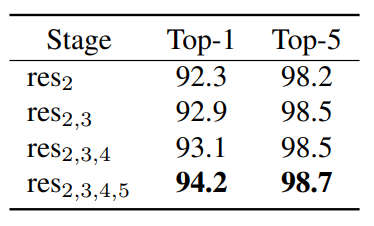
5. 실험
VR과 같은 기기에 적용하기 위해 경량화된 모델을 주장하였으므로 EgoGesture, Jester와 같은 VR 기기에 적합한 데이터셋과 Something-Something V2 데이터셋을 실험에 이용하였다.
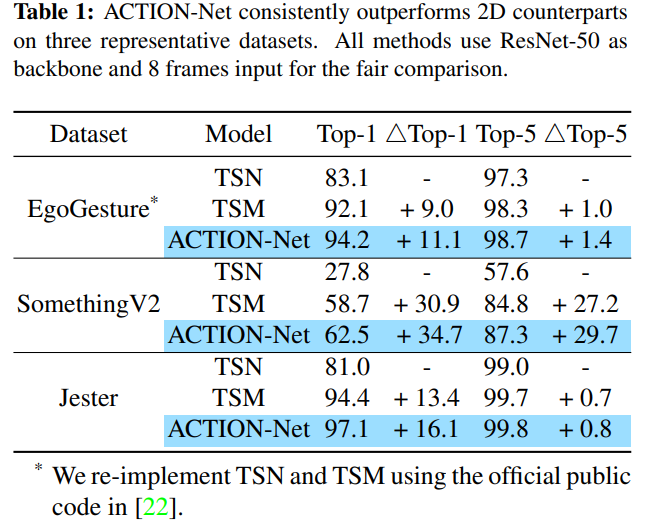
좋은 video action recognition 성능을 보인다.