해당 논문이 너무 길어서 두번에 나눠 리뷰를 진행할 예정입니다.

해당 논문은 Series of monocular images를 통해 3D Detection과 Tracking을 수행한 논문 입니다. 위의 티저 영상에 나타나듯 단일 이미지로 3D Detection을 수행하고, 시퀀스 이미지의 정보를 통해 강인한 Tracking까지 수행하는게 해당 논문의 핵심입니다. 또 이러한 모델을 학습하기위해 GTA에서 데이터셋을 구축하였고, 이를 공개까지 하였다고 합니다.
해당 논문의 저자는 online 3D tracking framework를 제안합니다. 해당 프레임워크는 3D object의 검출과 추적(track)을 동시에 수행하는 것이 특징입니다. 해당 모델은 가장 먼저 Faster RCNN을 통해서 RoI를 추출하고, 해당 ROI를 이용해 3D properties를 예측합니다. 여기서 3D properties는 3D bounding box center, depth, dimension, orientation 입니다. 또 추가로 해당 프레임 워크는 quasi-dense similarity learning으로 instance descriptor vector를 만들도록 학습한다고 합니다. quasi dense similarity learning은 뒤에서 설명하겠지만 결론적으로 같은 car라는 class에서도 실제 두 프레임에서 동일한 차가 어떤 것인지 구별할 수 있는 vector를 학습한다고 생각하시면 됩니다. 그리고 추가적으로 Tracking에서 occlusion과 reappearance가 발생할 때 robust하지 못한 문제를 해결하기 위해 motion-aware association과 depth ordering matching algorithm을 새롭게 적용합니다. 마지막으로 instances의 움직임(movement)을 캡처하고, 3D pose를 업데이트 하기 위해 VeloLSTM을 제안합니다. (VeloLSTM은 2편에서..) 이러한 전체적인 내용이 담긴 프레임워크는 다음과 같습니다.
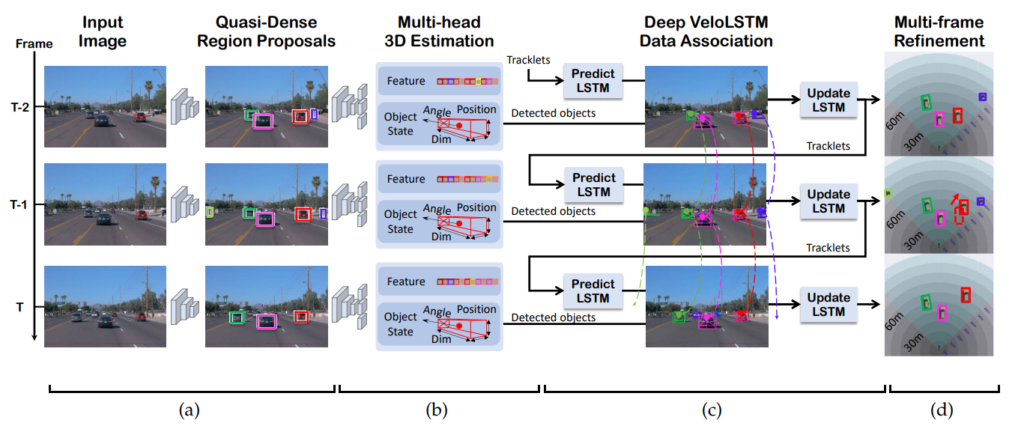
그럼 앞에서 부터 설명하겠습니다. (a) 파트는 모두가 알고있는 Faster RCNN을 이용한 RoI를 추출하는 부분입니다. 저자는 Faster RCNN을 통해 RoI를 추출하고, 해당 RoI feature를 두개의 lightweight multi-head network에 입력으로 사용한다고 합니다. 여기서 RoI feature는 RoI Pooling 대신 RoI Align을 사용했다고 합니다. 그러면 이러한 RoI Feature를 multi head network에 입력으로 사용하여 어떠한 값을 예측할까요? 바로 per-instance similarity feature embedding과 3D information 을 예측합니다. 하나씩 살펴보겠습니다.
Quasi-dense Similarity Learning
먼저 저자는 여러 시퀀스의 이미지에서 동일한 instance를 정확하게 찾아야 tracklets(궤적?)을 찾을 수 있기 때문에 동일한 instance를 찾기 위해 contrastive loss를 사용한 quasi-dense proposals을 적용합니다. 해당 방법은 저자도 잘 설명하고 있지만 먼저 발표된 논문이 더 잘 와닿아서 해당 그림을 가지고 설명하겠습니다.
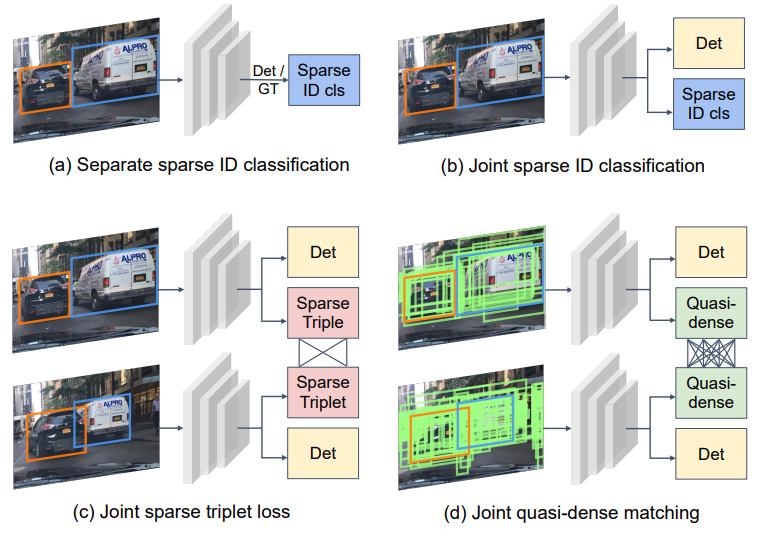
일반적으로 tracking이란 단순히 우리가 그림에서 자동차를 찾는 Detection과는 다른 문제입니다. Detection 문제에서는 위의 그림과 같이 이미지에 2대의 차량이 있고 그 두대를 찾으면 그만입니다. 하지만 Tracking에서는 각 차량에 대해서 ID cls까지 분류할 수 있어야합니다. (그래야 다음 프레임에서도 분류 할 수 있으니까요) 그럼 이러한 tracking을 수행하기 위한 방법은 어떤게 있을까요?
가장 나이브한 방법으로는 그냥 우리가 사용하는 GT bbox를 가지고 각각 ID cls를 부여해서 모델을 학습하는 방법이 있을 것입니다. 이는 위에서 그리 (a)와 같습니다. 그리고 여기서 조금더 나아가 (b) 와 같이 Detection과 ID Classification을 joint 한 방법론도 있습니다. 그리고 위에 그림을 설명하는 논문인 ‘ Quasi-Dense Similarity Learning for Multiple Object Tracking ‘ 에서는 모델이 예측한 Proposal들을 가지고 Desnse하게 ID를 분류할 수 있는 방법을 제안합니다. 해당 내용은 다시 리뷰중인 논문의 그림을 가져와서 더 자세히 설명하겠습니다.
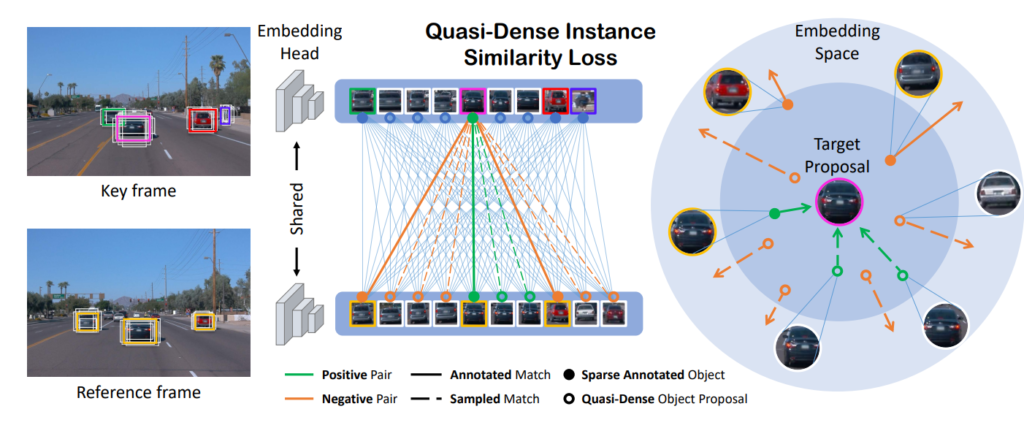
위의 그림과 같이 실제 해당 논문은 연속적인 이미지에서 동일한 instance를 찾고, 해당 instance의 tracklet을 구하는 방법을 사용하고 있습니다. 따라서 각 instance를 정확하게 분류하는 것이 중요하고, 저자는 이를 위해서 Quasi-Dense Instance Similarity Learning을 수행합니다. 위의 그림에서 실제 RoI를 선별하면 Object 주변에 많은 Box들이 높은 Confidence를 가지게 됩니다. 일반적으로 2D Detection에서는 이를 NMS로 처리하여 제거하지만, 해당 방법론에서는 실제 가장 score가 높은 박스와 IOU가 0.7 이상인 box는 positive로 0.3이하인 박스는 negative로 설정하여 contrastive learning을 수행합니다. 이때 특징으로는 시퀀스 이미지 각각에서 Faster RCNN에서 나온 RoI, 즉 Proposal(potential regions of interest)를 사용하기 때문에 computational redundancy를 줄일 수 있다고 저자는 이야기 합니다. 그럼 위의 그림처럼 Reference frame과 Key frame은 어떻게 정의할까요? 저자는 시퀀스 이미지에서 Key frame의 앞,뒤 3장 이내의 이미지를 Reference로 사용했다고 합니다.
그러면 이러한 컨셉을 기본으로 설계한 Loss는 다음과 같습니다.
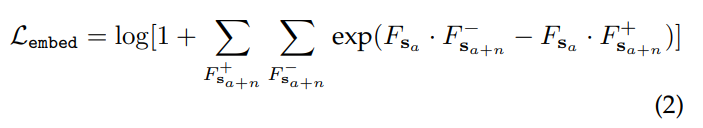
기본적인 형태는 크로스 엔트로피의 형태를 띄고 있으며 위의 수식에서 +,- 는 Postive와 Negative를 F_s는 emvedding feature를 그리고 s_a는 key frame이며 n은 해당 프레임에서 앞뒤 n장 이미지를 의미합니다. 해당 부분에서 목표는 positive 임베딩 벡터간의 코사인 유사도는 최대가 되며(가까워지며) Negative 임베딩 벡터간의 코사인 유사도는 최소가 되도록 모델을 학습한다고 합니다. 이를 위해서 추가적인 Loss를 추가하며 이는 다음과 같습니다.
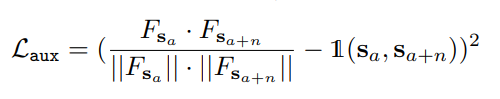
따라서 최종적으로 ‘Quasi-dense Similarity Learning’을 위한 Loss는 다음과 같습니다.

정리하면 해당 학습 방법을 통해서 시퀀스 이미지에서 동일한 instance를 잘 찾을 수 있다고 합니다. 자 그러면 다음으로 3D information을 추론하는 head network에 대해서 살펴보겠습니다.
3D Bounding Box Estimation
저자는 3D Bounding Box를 Estimation 하기 위해서 Mousavian et al의 방법을 확장했다고 합니다. 그럼 Mousavian et al의 방법이 무엇인지 부터 알아봐야겠죠..? 해당 논문의 제목은 다음과 같습니다. ‘ 3D Bounding Box Estimation Using Deep Learning and Geometry ‘ 해당 논문에서는 어떤 방법을 이야기하고 있을까요?
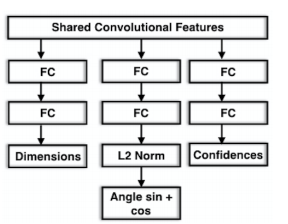
‘3D Bounding Box Estimation Using Deep Learning and Geometry ‘ 논문에서는 (2D Detection 결과를 crop한 이미지를 가지고) Dimensions, Angle, Confidences 3가지를 예측합니다.
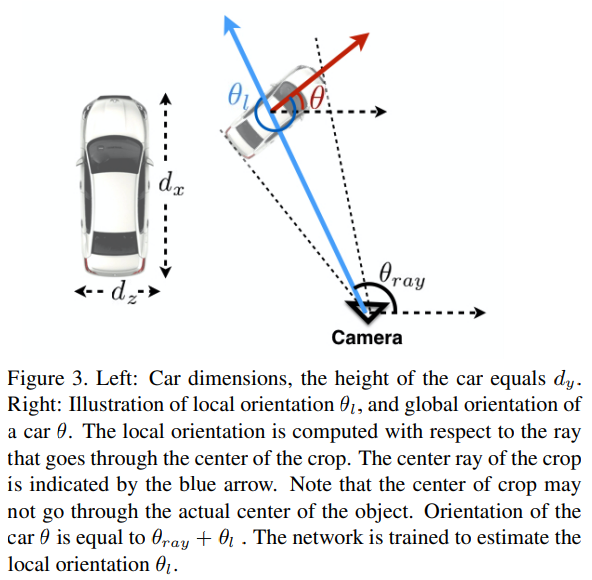

여기서 Dimension은 3D Box에서 차량의 크기를 의미하며, angle은 위의 그림에서 θ_l을 의미합니다. θ_l를 모델이 예측하면 차량의 Global 방향을 얻을 수 있다고 합니다. 여기서 ray는 논문에서 다음과 같이 설명합니다.
We thus regress to this local orientation θl . Fig. 4 shows an example, where the local orientation angle θl and the ray angle change in such a way that their combined effect is a constant global orientation of the car. Given intrinsic camera parameters, the ray direction at a particular pixel is trivial to compute. At inference time we combine this ray direction at the crop center with the estimated local orientation in order to compute the global orientation of the object.
아무튼 … 다시 리뷰중인 논문으로 돌아와서 해당 논문에서도 위에서 사용한 방법을 기반으로 3D Detection을 진행합니다. 다만 저자가 주장하는 차이점은 이미지로부터 3D bounding box를 예측하는데 필요한 모든 파라미터를 추정한다고 합니다. 또한 Mousavian et al의 방법은 2D box를 통해서 3D object의 방향과 크기를 추정하는것을 집중했지만 자신들은 3D tracking, motion refinement를 통합했다고 합니다. 다시말하면 해당 논문에서 제안하는 프레임워크의 head network는 depth d, 3D bounding box center projection C, dimensions D, and orientation O를 모두 학습하는데 사용해서 해당 파라미터들을 다 예측한다고 합니다.
먼저 3D Location에 대한 정보를 얻기위해 제안하는 모델은 상수 r로 scaled 된 logarithmic depth value를 regress하는 것을 학습한다고 합니다. 이때 학습에는 Smooth L1 loss가 사용됩니다. 기존의 방법들과 다르게 자신들은 logarithmic으로 target을 스케일하여 더 realistic scaling을 했다는게 특징이라고 합니다. 여기서 projection된 3D location P는 3D object center C의 추정된 2D projection을 이용해 계산한다고 합니다. 여기서 잠깐 ‘ 3D object center C의 추정된 2D projection ‘은 무엇일까요? 해당 내용을 바로 뒤에서 설명하고 있습니다.
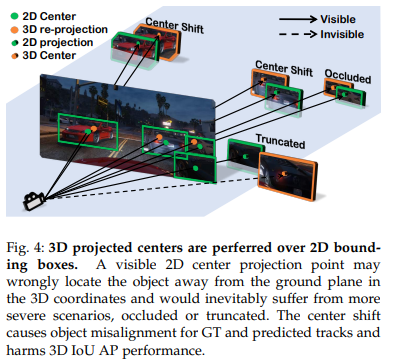
정리하면, 실제 3D Bouding box의 센터를 2D로 projection 하면 이미지에서 찾은 proposal이나 GT의 center와는 약간의 오차가 존재한다고 합니다. 이를 Center shift라고 명명합니다. 저자는 이러한 Center shift를 바로잡기 위해서 a projected 2D point of 3D bounding box center를 예측하기 위한 regression 모듈을 추가합니다. 그리고 해당 모듈의 입력은 Roi aligned feature이며, Loss는 Smooth L1 Loss를 사용합니다. 이러한 방법으로 구한 좀더 정확한 3D bounding box center가 있기 때문에 더 정확한 3D Location을 구할 수 있다고 합니다.
또 정확한 3D box를 예측하기 위해서 3D Confidence를 추가했다고 합니다. 이러한 3D Confidence는 detection에서는 3D objectness score로, tracking에서는 가중치로 사용된다고 합니다. 3D Confidence를 예측하는 모듈을 추가하여 single frame depth estimation의 ambiguity와 multiple frame motion model location prediction에 도움을 주었다고 합니다.(흠, 이부분은 조금 어려워서 이유만…)
그리고 Object Orientation은 카메라 좌표계에서의 object rotation을 θ_cam이라고 할때, θ_cam는 geometry 관계를 이용해 θ_cam = [θ_obs + arctan(u^/f)]으로 구할 수 있다고 합니다. 여기서 θ_obs는 observed vehicle heading, u^은 object center와 이미지의 horizontal center의 image coordinate distance를 그리고 f는 focal length를 이야기한다고 합니다. (아래 그림에서 주황색 정도..?)
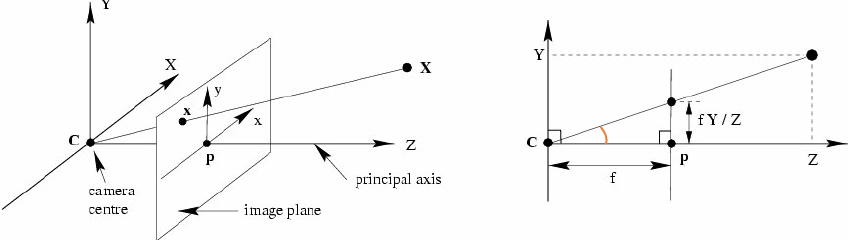
여기서 θ_obs는 위에서 언급한 Mousavian et al의 방법으로 구할 수 있다고 합니다.

마지막으로 Object Dimension은 실제 GT를 이용해 Regression 했다고 합니다.
정리하면, 3D properties를 모두 예측하였는데요, Location P(3차원상 위치), Orientation O, dimension D, 2D projection of its 3D center C를 구할 수 있었다고 합니다.
이제 이러한 것들을 가지고 시퀀스 이미지 프레임에서의 associate를 예측한다고 하는데요.. 자세한 내용은 다음주에! (해당 논문은 24page이므로 제 용량을 초과하였습니다..)