배경
안녕하세요. 오늘 소개할 논문은 CVPR 2021 3월에 공개된 논문으로 아직 한달이 채 되지 않았습니다. 교수님의 추천으로 읽어보고 이렇게 리뷰남기게 되었습니다.
해당 논문은 수중환경에서의 이미지 품질 개선입니다. 수중환경에서의 이미지 품질개선은 수중로봇과 컴퓨터비전을 이용한 task를 할 때 중요한 주제중 한개입니다.
이번 논문을 읽을때에는 읽으면서 중요한 부분을 A4용지에 정리하면서 읽었습니다. 그래서 해당 리뷰에서는 정리했던 내용을 위주로 쭉 요약해나가며 설명해드리겠습니다. 그리고 중간중간 저의 생각을 좀 담아볼 생각입니다. (비판적 사고)
Abstract
기존 수중환경 이미지 개선 연구에서는 RGB colour space만을 사용하는 경우가 많았습니다. 그래서 논문에서는 RGB와 HSV의 colour space를 사용하는 연구가 가치있다고 주장합니다.
논문에서는 총 3개의 블락으로 구성된 end-to-end learnable network를 제안합니다. 해당 네트워크는 아래와 같이 구성되어 있습니다.
- RGB Pixel-level Block
- HSV Global-adjust Block
- Attention Block
위의 블락들에 대해서는 이름으로부터 직관적으로 어떠한 역할을 하는지 예상 해볼 수 있습니다. 자세한 설명은 나중에 아키텍쳐 그림과함께 하겠습니다.
Introduction
대다수의 논문이 그렇듯 연구분야에 대한 백그라운드 소개와 필요성에 대해서 먼저 언급합니다. 수중이미지의 품질개선을 통해 생선감지, 난파선 탐지, 고고학분야등에 쓰일 수 있다고 하면서 문제점들을 언급하는데요. 대충 요약하자면 수중이미지의 문제점은 아래와 같습니다.
- Backscatter
- Low Contrast
- Low Brightness
- Low Colour Deviations
- Blurry details
- Uneven Bright Speck
상당히 많네요… 1번은 수중환경에만 국한되는것이므로 좀 낯선 용어일텐데요. 물속 입자들이 카메라의 플래쉬를 반사시켜 빛이 퍼지면서 화질이 떨어지는 현상이라고 하네요. 이는 탁한 물일수록 더 심해진다고 합니다. 자세한 내용은 해당 링크를 참고하세요.
이러한 복합적인 이유로 수중에서의 이미지의 화질은 많이 떨어지게 됩니다. 그래서 화질개선에 대한 연구가 많이 있었습니다.
기존연구들에서는 히스토그램 평활화, 물리학을 기반으로한 방법들을 사용하는데 이러한 방법들은 실제 복잡한 환경을 너무 간단하게 simplify했다는 문제가 있습니다. 수식적으로 풀기위해 많은 파라미터를 가정하였고, 이로인해 오차가 발생하여 여전히 많이 미흡한 실정이었습니다.
그러는 와중에 딥러닝이 발달하며, 딥러닝을 이용한 수중이미지 품질개선 연구들이 진행이 되었는데요. 주로 RGB colour space만을 사용하여 품질개선을 시도하였습니다. 물론 RGB colour space만을 사용해도 꽤나 괜찮은 결과를 가지지만, insufficient texture details, Background colour cast 등이 여전히 문제로 남습니다.
그래서 해당 논문에서는 HSV colour space까지 활용하며, 이와 더불어 attention 기법을 적용합니다. HSV colour space를 이미지 개선 연구에 활용한 사례는 있었지만, 수중이미지에 활용한건 이번이 처음이라고 주장하네요. 그리고 channel-level이 아닌 pixel-level의 attention을 플러스 알파로 언급합니다.

해당 위의 그림은 해당 논문에서 제안하는 네트워크의 결과물입니다. 첫 번째 행은 raw data, 그리고 두 번째 행은 네트워크를 통해 개선한 이미지 입니다.
Related works
수중이미지에 관심이 크게 없으신분들은 제 리뷰에서 해당부분을 스킵하셔도 무방하다고 생각합니다.
요약하자면, 수중이미지 품질개선은 CNN기반과 GAN기반으로 나뉩니다. 관련 연구들을 언급하고요.
데이터셋은 인공적으로 만들기에는 복잡하여 간단하게 mask를 씌워서 만든다거나 하기보단 GAN기반으로 만들어야 한다고 언급합니다.
그리고 유명한 데이터셋 몇몇들을 언급합니다.
그리고 HSV colour space를 사용했던 과거 연구들에 대해서 언급합니다.
간략히 요약해봤는데 관심가시는분들은 직접 읽어보세요. 내용이 어렵지않아 금방 읽을 수 있습니다.
Proposed Model
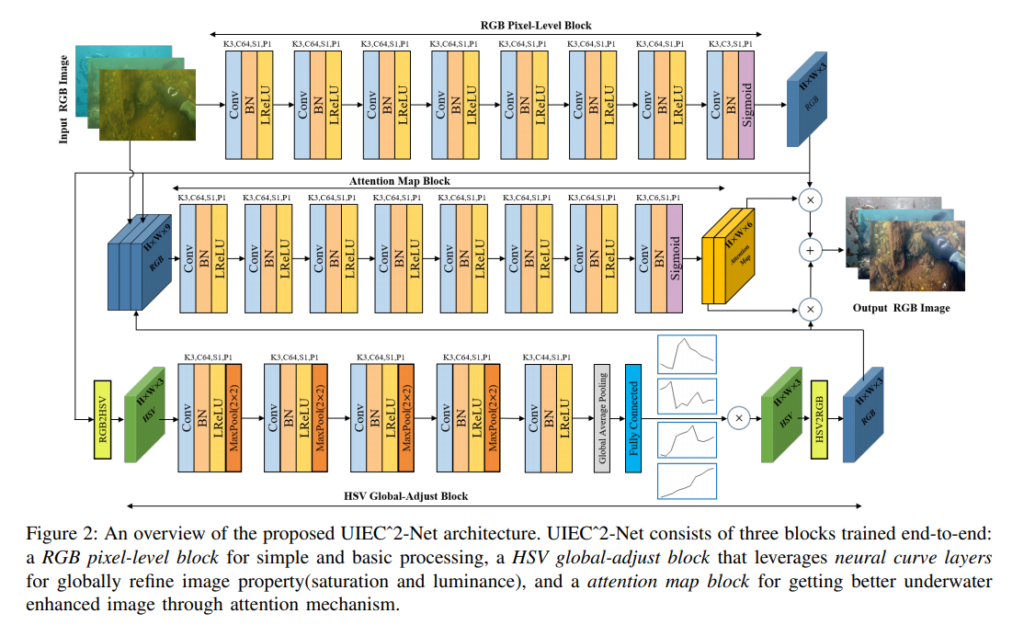
리뷰를 읽기전 해당 네트워크 구조를 한번 꼼꼼히 살펴보시길 권장드립니다. 사실 논문에서도 해당 네트워크 구조를 친절하지만 복잡하게 설명하는게 주된 내용입니다. 언제나 그렇듯… 네트워크 구조를 글로 설명하면 복잡해보이는거 같은건 어쩔 수 없는거 같네요. 그림이 너무 작으신분들은 논문을 클릭하셔서 보세요.
그럼 블록단위로 설명을 해보겠습니다.
RGB Pixel-level Block
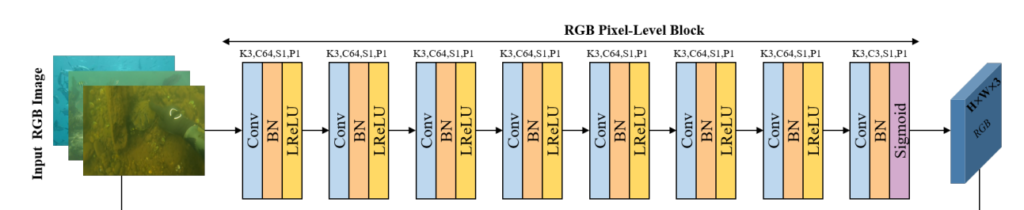
위의 아키텍쳐에서 해당 블록 부분만을 캡쳐해왔습니다.
간단한 CNN구조이며, 블록의 구조는 직관적이기 때문에 설명을 생략하겠습니다. 특이점이라하면 K=3, S=1, P=1로 인풋 이미지의 H와 W가 유지되며 마지막 Conv layer에서는 채널을 3으로 만들어주어서 H*W*3의 feature space를 생성합니다.
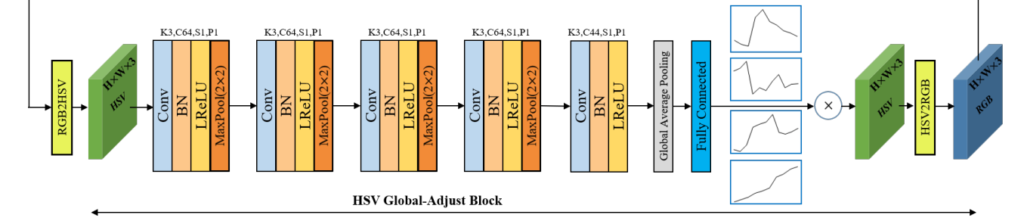
다음으로는 HSV Global-adjust Block에 대해서 설명해드리겠습니다. 위에서 구한 RGB feature map을 인풋으로 받고, 미분가능하며 RGB colour space를 HSV colour space로 변환해주는 레이어를 거칩니다. 그리고 간단한 CNN 구조를 거친 후 44개의 채널로 나옵니다. 이 후 Global Average Pooling을 거치고, 1*1*C의 형태로 나온 후, Fully Connected Layer에 인풋으로 들어갑니다.
그리고 fully connected layer에서는 piece-wise linear curve의 knot points를 regression 해줍니다. 이게 무슨소리 이냐면…
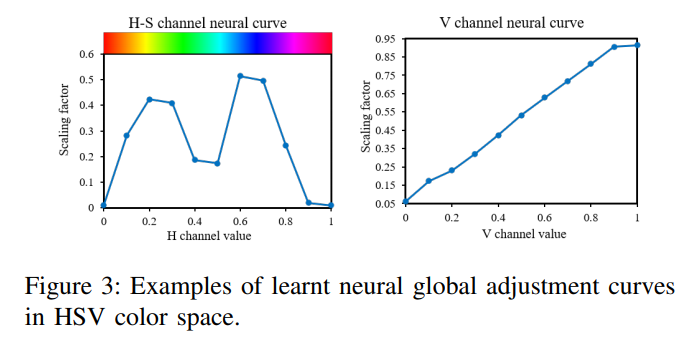
위의 그림처럼 H-S, V 채널의 scaling factor를 regression으로 구하는 셈 입니다. 그리고 해당 scaling factor는 HSV 이미지에 곱해진 후 다시 RGB이미지로 변환됩니다. 이 후 RGB layer를 통과해서 feature map을 형성합니다.
Attention Block

Attention Map에서는 앞에서 구했던 feature maps들을 사용하여 attention 기법을 적용해줍니다. 일단 인풋으로 raw RGB이미지와 위에서 구한 2개의 feature maps을 받습니다. 그리고 역시나 간단한 CNN 구조를 통과하고 H*W*6 형태의 attention map을 생성합니다. 이때, 6채널중 앞의 3개는 RGB에 대한것이고, 뒤의 3개는 HSV block 결괏값에 해당하는 것 입니다.
그렇게 구한 H*W*6의 Attention map은 위에서 구한 feature map들과 곱해집니다. 곱해진 값들… 즉, H*W*3 , H*W*3 두개의 값은 더해져서 최종적인 Output RGB Image를 도출합니다.
Loss
Loss term은 총 4개를 사용합니다.
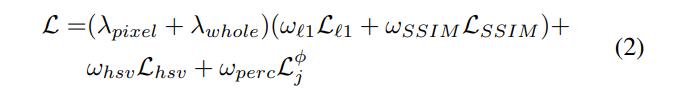
위와같이 최종loss는 람다(weight)와 HSV Loss, L1 Loss, SSIM Loss, Perceptual Loss에 각각 weight factor가 붙은 합으로 이루어지며, 해당 최종 loss를 이용하여 back propagation 합니다. 이 때, w와 람다들은 모두 하이퍼 파라미터로 논문에서 어떠한 값을 사용했는지 명시되어있습니다.

먼저 HSV Loss입니다. 정의역을 참고하시라고 위의 원문까지 같이 끌고왔습니다. HSV에 대한 설명은 여기를 참고해주세요. 해당 링크를 보시면 H는 0~360 S,V는 각각 0~100 사이의 값인데 논문에서는 이를 0~2pi , 0~1사이의 값으로 사용하였네요. 사실 어차피 total loss할 때 weight factor가 곱해지니 어떤식으로 정의해도 상관없을거 같긴 하네요.

L1 loss는 익숙한 개념이므로 넘어가겠습니다.

SSIM은 위와같이 GT와 predicted image의 standard deviation과 mean값으로 계산되고, 해당 SSIM값의 평균을 1에서 빼준것을 SSIM Loss로 사용합니다.

Perceptual loss도 이름은 어려워보였는데, L1 loss랑 크게 다르지 않네요. feature space상에서 predict 이미지와 GT 이미지의 값을 빼준 값을 모두 더해준다음 C,H,W의 곱으로 나누어주었네요.
Experiment
실험은 인공적으로 만든 데이터셋과 real-world 데이터셋 에서 진행하였으며 결과는 아래와 같습니다.
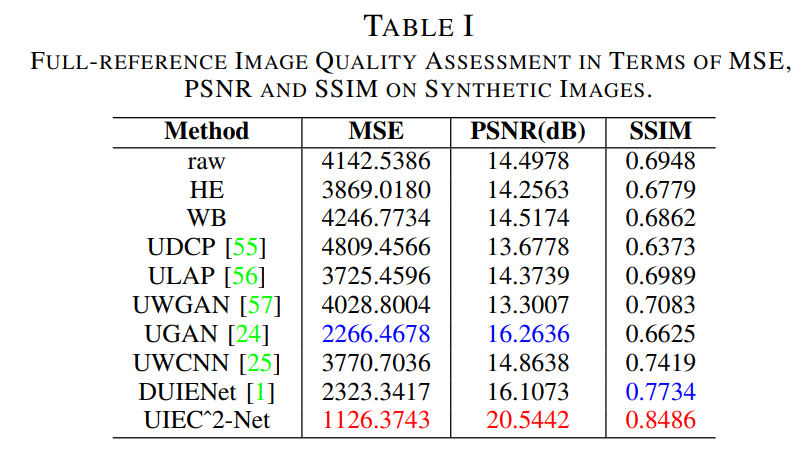



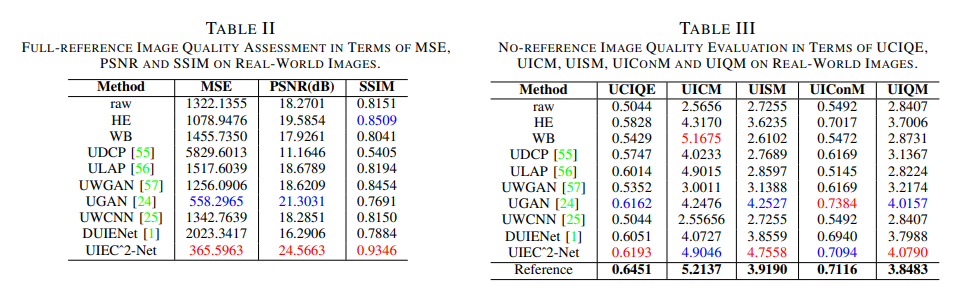
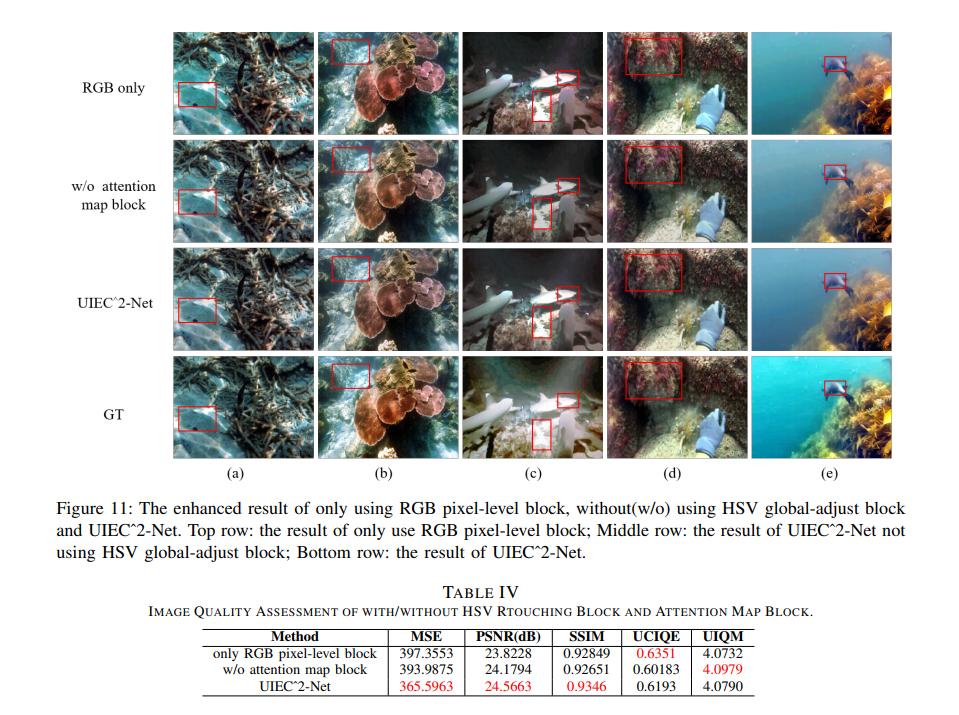
총평
개인적으로 느끼기에 CVPR 논문치고 사소한 에러가 많은거 같았습니다. 영어 문법, 오타, reference mapping 에러… 등등
그리고 기존에 있던 방법론들을 짜깁기하여 모아서 수중환경에 재활용 했다는 느낌이 강했습니다. 또한 간단한 네트워크 구조를 일부러 Simple하게 하여 장점을 살렸다고 하는데 그 일부러 simple하게한 이유에 대한 논리가 빈약한거 같습니다.
그럼에도 불구하고 좋은논문이며, CVPR에 Accept될 수 있었던 이유는 설계한 네트워크를 이용하여 좋은 성능을 달성하였기 때문이라고 생각합니다.
성능이 애매 했다면… 글쎄요? CVPR은 어림도 없었을 겁니다. 최근 논문들을 읽으며 느끼는게 많은 실험을 반복하며 좋은 성능 나온걸 확인하고, 해당 좋은 성능에 의미부여를 하여 논문을 작성하는게 일반적인 루트인거 같습니다.
해당 논문을 읽다보니 그 과정이 유난히 도드라지게 보이네요.
음 단순히 좋은 성능을 달성했다기 보다는 Under water 이미지 Enhancement를 위해 RGB Space만 다루는 기존 방법들과는 다르게 HSV color sapce를 함께 다루고 있고, 하나의 네트워크로 두 space를 모두 다룰 수 있다는 점이 key contribution이 아닐까요? Under water 도메인에서는 HSV space로 문제를 다루는게 효과적이였다는 내용을 처음으로 이야기하는데, 이부분이 가장 큰 핵심인 것 같습니다. 말씀하셨던 성능이 좋은 것은 그것을 증명하는 실험일 뿐이라고 생각합니다. 다시말하면 성능차이가 지금처럼 드라마틱하지 않더라도 기존의 방법들보다 조금이라도 좋은 성능이 나온다면, Under water 분야에서는 HSV Color space도 유의미하다는 이야기를 처음 하므로 좋은 논문이 될 것 같습니다.
네 글에서 적어놨듯 논문에서는 HSV colour space를 “수중환경”에 적용한게 처음이다라고 주장하고 있습니다.
리뷰 잘 읽었습니다.
질문을 몇가지 드리자면, 정성적 결과들을 보면 Paired한 Dataset을 사용하는 듯 싶은데, 잘 촬영된 영상(GT)을 GAN을 통하여 downgrade 시켰다고 보면 될까요?
그리구 또 다른 질문으로 왜 이 논문에서는 HSV를 처음부터 원본 RGB를 변환하여 입력으로 안넣고, RGB block을 통과하여 나온 RGB feature를 변환시켜서 사용하나요?
“Paired한 데이터셋”이라는 말을 이해 못했습니다. 논문에선 RGB만을 사용합니다. 데이터셋은 synthetic 하고 real-world 두개를 사용합니다. 두번째 질문는 제 기억으로 논문에 나와있지 않아서 잘 모르겠습니다.
입력과 GT가 동일한 장면에 대해서 학습하는 것을 Paired 데이터셋이라고 표현하였습니다.
동일한 장면에 대해서 화질이 좋은 영상과 그렇지 못한 영상을 동시에 구한다는 것은 어려울 듯 하여 서로 동일하지 못한 unpaired scene으로 학습하는지, 아니면 GAN을 통한 합성으로 화질이 좋지 못하는 영상을 만드는지에 대해 물어본거였어요.