Before Review
이번주 Review의 주제는 Model Scaling 입니다.
본격적인 Review를 시작하기전에 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks(2019 , Mingxing Tan) 에 나와있는 자료를 하나 참고하겠습니다
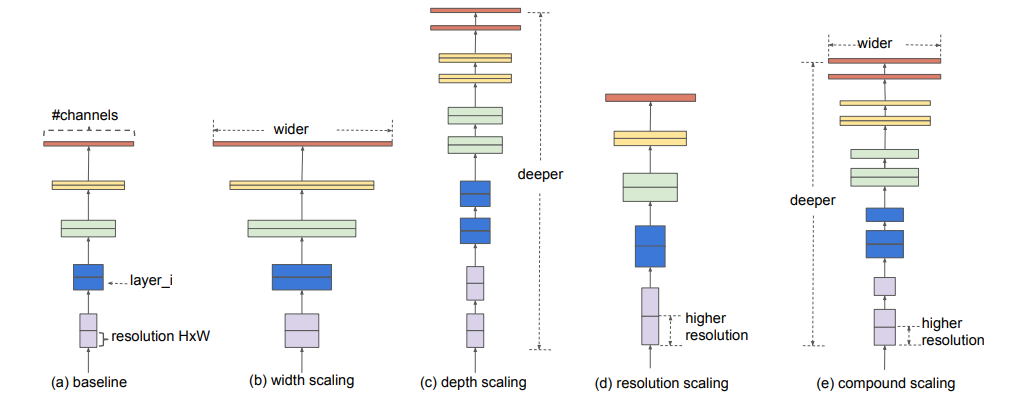
기존 Model Scaling 방법이 어떤식인지 큰 흐름을 보여주고 있는 그림입니다.
대게 Model Scaling은 모델의 Accuracy를 향상시키기 위해 사용한다고 합니다.
Scaling은 Filter의 채널수(width)를 늘리거나 , Layer수(Depth)를 늘리거나 , Input-size(Resolution)를 늘려주는 방법들로 구성이 됩니다.
알고 가면 더욱 이해가 잘될 것 같아 언급하고 Review를 시작하겠습니다.
Introduction and Motivation
- 본래 일반적으로 Deep Learning 모델에는 속도가 빠르면 정확성이 떨어지고 , 정확성이 올라가면 속도가 느려지는 Trade-off 관계가 존재합니다.
- CNN model의 “width” , “depth” , “resolution” 을 조절 해주는 model scaling 방법들이 존재하고 있지만 scaling 방법들의 trade-off 관계가 완벽히 연구되지 않았다고 합니다.
- 대부분의 기존 연구들은 accuracy를 향상시키는 데에 초점을 두었었습니다.
- 그래서 본 연구의 Motivation은 다음과 같습니다. “Can we design scaling strategies that optimize both accuracy and model runtime(speed)?”
- 본 연구는 Fast scaling이라는 방법을 제시했고 , 이는 동일한 Accuracy지만 더 빠른 Runtime을 가질 수 있게하는 Scaling 방법입니다.
- 핵심은 Activation을 최소한으로 증가시키면서 모델을 scaling 해주는 방법을 제시하는데 ,이는 width에 초점을 맞추고 Depth와 resolution에는 낮은 비중으로 scaling 하는 방법입니다.
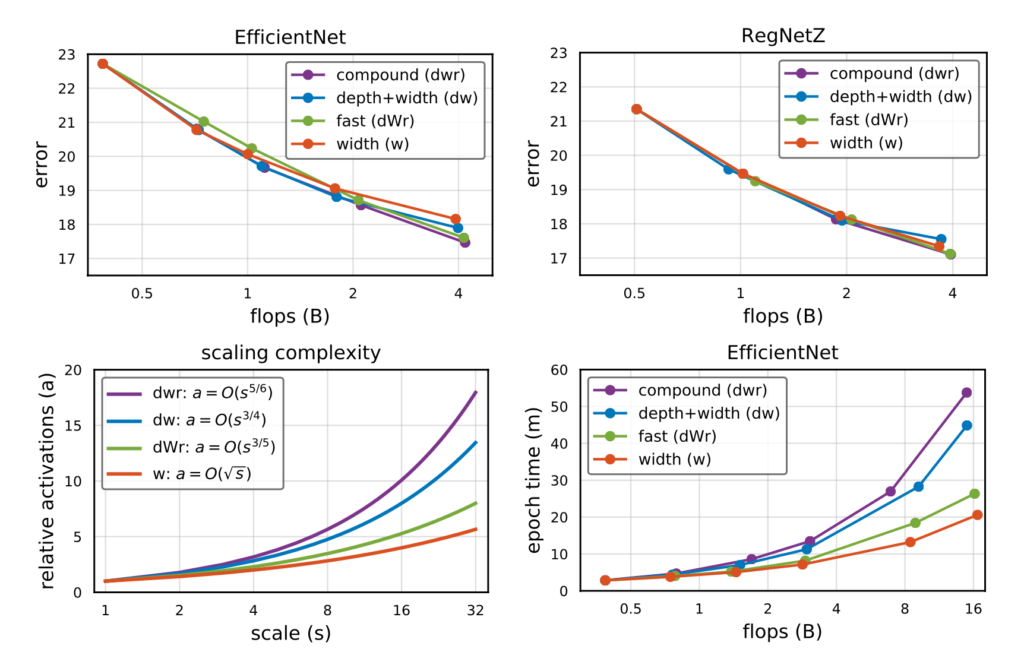
그래프의 x축에 나와있는 flops는 연산능력 , 연산량 이런 개념이고, scale은 scaling factor인데 scale이 클수록 높은 비율로 scaling 한 것을 의미합니다.
- 본 논문에서 제시하는 방법은 연두색 그래프로 나타나 있습니다. fast scaling(dWr)이 정확도 측면에서는 EfficientNet 논문에서 나온 Compound scaling(dwr)과 비슷하거나 동일한 성능을 보여주지만 , epoch time과 scale증가에 따른 activation의 점근적 증가율이 낮은 것을 확인할 수 있습니다.
- scale을 키워줌으로써 activation이 천천히 증가하는 것은 Run-time 측면에서 중요한 역할을 하는데 이유는 뒷부분에서 다루도록 하겠습니다.
- 본 Paper의 아이디어를 살펴보기전에 우선 Model의 complexity를 설명하는 지표에 대해 간단히 알아보겠습니다. (flops , parameters , activations)
Complexity of Scaled Models
Network의 Complexity를 측정하는데에 사용이 되는 3가지 Metric을 소개하겠습니다. 논문에서 자세하게 설명은 하고 있지 않아 일단 원문 그대로 가져왔습니다.
- Flops : To mean multiply adds
- Parameters : To denote the number of free variables in a model
- Activations : To define the number of elements in the output tensors of CNN layers
Flops는 연산량을 뜻하는 것 같습니다.
Parameter는 Weight 나 bias같은 그런 Parameter들을 말하는 것 같습니다.
Activations는 activation function을 통과한 element들의 수를 얘기하는 것 같습니다.
(해석에 부족한 부분이 있다면 comment 남겨주시면 감사하겠습니다)
width 와 depth resolution을 가지고 flops , parameters , activations 들을 계산하는 법을 알아보겠습니다.

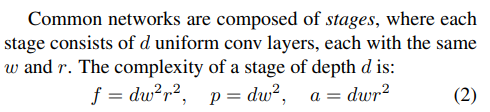
사실 저게 어떻게 도출이 됐는지를 이해하진 못했는데… 뒤의 내용을 살펴보니 이해못해도 지장이 없기 때문에 우선 설명은 생략하겠습니다.
핵심은 Flops , Parameters , Activations 들을 depth , width , resolution의 식으로 표현했다.

single scaling 일때 flops , parameters , activations들이 어떤 비율로 계산이 되는지 보여주는 Table입니다.
주목해야되는 부분은 다른 detph나 resolution은 activation을 s만큼 scaling한것에 비해 width 만 activation을 √s 만큼만 scaling 시켰다는 것입니다.
이런 observation은 뒤에 서술하겠지만 저자가 사용할 아이디어의 핵심이 됩니다.

위의 테이블에서는 한가지만 scaling 한것이 아닌 여러가지 조합(depth-width , width-resolution , depth-width-resolution ..)network들의 Complexity를 보여줍니다.
Compound scaling(dwr)은 activation이 거의 linear하게 증가한 것을 확인할 수 있습니다.
scaling 방법에 따른 Complexity가 어떻게 변하는지 살펴봤습니다. 이제 이런 Complexity metric과 Model Runtime 간의 관계를 밝혀보겠습니다.
Runtime of Scaled Models
- 다시 한번 본 Paper의 Motivation을 상기시켜 보면 , fast 하면서 accurate한 scaling 방법을 고안하는 것이었습니다.
- 위에서 다양한 scaling 기법에 대한 flops , parameter , activation들의 변화를 살펴봤습니다.
- 여기서는 어떠한 요소가 model Runtime에 가장 밀접한 관계가 있는지 알아보겠습니다.
- 밑에 그림을 보면 flops , parameters , activations이 증가함에 따라 Runtime을 각각의 scaling 기법을 적용해 표현한 그래프입니다.
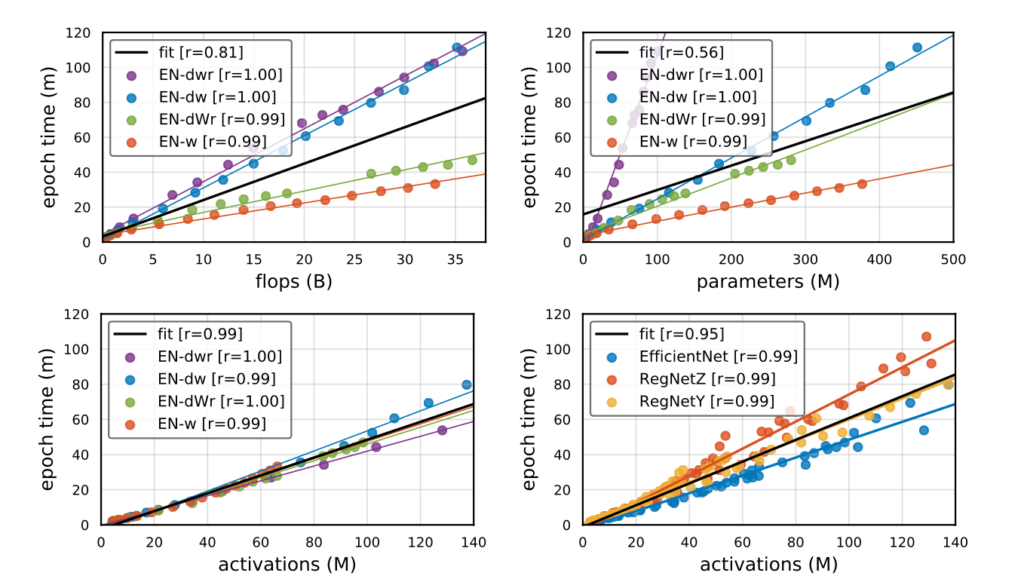
그래프를 간단히 설명하면 EN-OO 라고 적혀있는 것은 Efficient-Net에 4가지 scaling 기법을 적용한 것입니다.(single-width , depth-width , Compound , fast-Compound)
r 은 Pearson Correlation 를 계산한 것이며 flops , parameters , activations 들과 Runtime 간에 관련성을 나타내줍니다.
Fit 이라고 적혀있는 검정색 line은 전체 데이터의 분포를 설명하는 line이라 생각하시면 됩니다.
하나씩 확인을 해보자면 먼저 Flops의 Pearson Coefficient는 0.81 입니다. 서로 비슷한 추이를 가지고 있는 것 같지만 Flops가 Runtime을 완전히 예측할 수는 없습니다. Scaling 기법별로 증가하는 추이가 조금 다르기 때문입니다.(dwr , dw 기법이 dWr , w 기법보다 더 빠르게 증가)
그 다음 Parameter의 Pearson Coefficient는 0.56 입니다. 확실히 scaling 기법마다 증가하는 추이가 완전히 다른것을 확인 할 수 있습니다. 따라서 parameter의 증가로는 Runtime을 예측할 수 없습니다.
마지막으로 Activation입니다. Activation은 scaling 기법과는 관계없이 일관된 추이를 보여주고 있습니다. 따라서 Activation으로 Runtime을 예측하는 것은 좋은 접근입니다.
확인해보면 Activation이 Runtime과 가장 높은 관련성을 보여주고 있다는 것을 확인할 수 있습니다.
즉 , Activation의 증가가 Runtime에 더욱 치명적이다 라는 의미를 내포하고 있습니다.
Fast Compound Model Scaling
- 앞선 실험에서 Model의 Run-time과 activation이 큰 연관 (scaling 기법 상관없이 activation이 증가하면 Runtime이 증가한다) 을 가지는 것을 확인했습니다.
- 그래서 저자는 scaling 방식을 가능한 activation을 최소화시키는 방향으로 고안했습니다.
- 아이디어는 Single-scaling 결과를 관찰한 것에서 기인합니다. Width가 그나마 activation 증가에 덜 영향을 주기 때문에 Width scaling에 비중을 높이고 , Depth와 Resolution에 비중을 줄이는 방향으로 설계 합니다.(위의 Single scale Table을 확인해보시면 됩니다)
우선 0 < alpha < 1 인 alpha를 가지고 상수들을 정의해줍니다
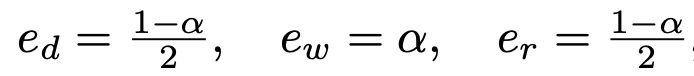
위에서 정의한 상수들을 이용하여 scaling factor를 정의해줍니다.
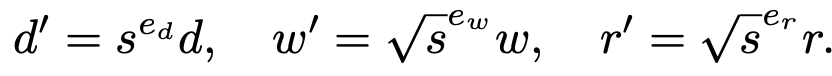
이런식으로 정의된 scaling factor들을 살펴보면 결국 alpha가 1에 가까울 수록 , width의 비중이 높아지고 depth 와 resolution의 비중은 낮아지게 됩니다.(저자는 fast scaling을 위해 alpha를 0.8로 설정했습니다.)
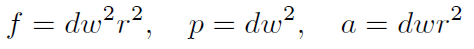
그 다음 complexity를 구해주는 식에 대입을 해준다면 아래와 같은 결과를 얻을 수 있습니다.
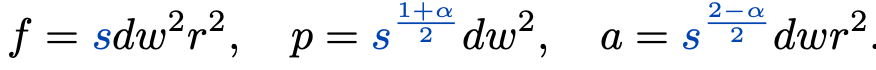
이러한 alpha들을 조절해줌으로써 다양한 결과들이 나온다고 합니다.
- alpha = 0 : resulting in depth and resolution scaling (dr)
- alpha = 1/3 : corresponds to uniform compound scaling (dwr)
이때 , 흥미로운 부분이 1/3 < alpha < 1 부분인데 , alpha가 1에 가까우면(width에 비중을 높게 준다는 의미) fast scaling이 된다고 합니다
아래 Table을 확인하면 activation이 비교적 적게 증가하는 것을 확인할 수 있습니다.
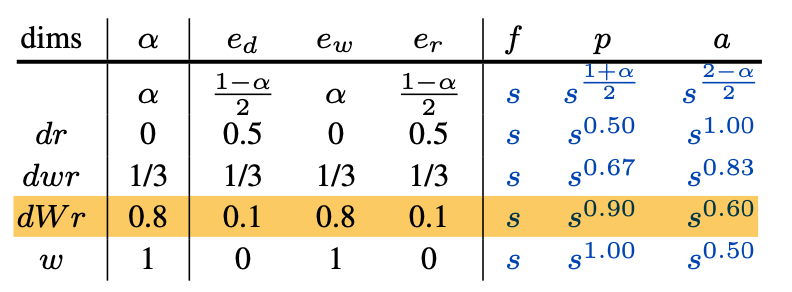
Experiments
Experiment의 모델은 EfficientNet과 RegNet을 사용한다고 합니다.
EfficientNet
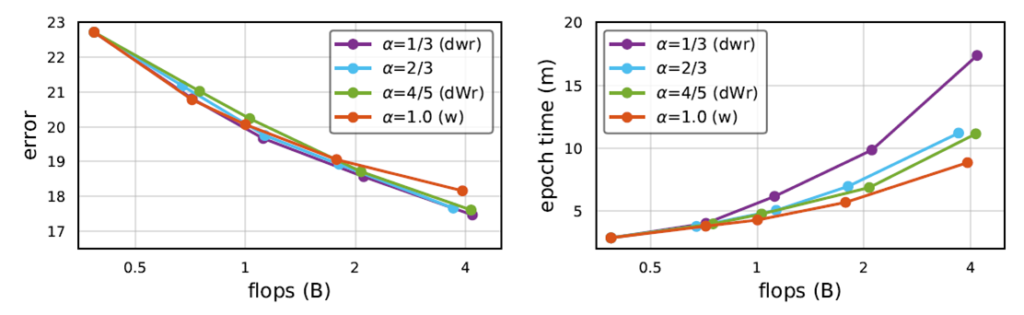
Accuracy는 uniform compound scaling(dwr)인 보라색 선이 제일 높지만 fast-scaling(dWr)이 compound scaling(dwr)에 비해 Speed가 더 빠른 수치를 가지는 것을 확인할 수 있습니다.
RegNet
왼쪽이 RegNet-Y 이며 , 오른쪽이 RegNet-Z 입니다.
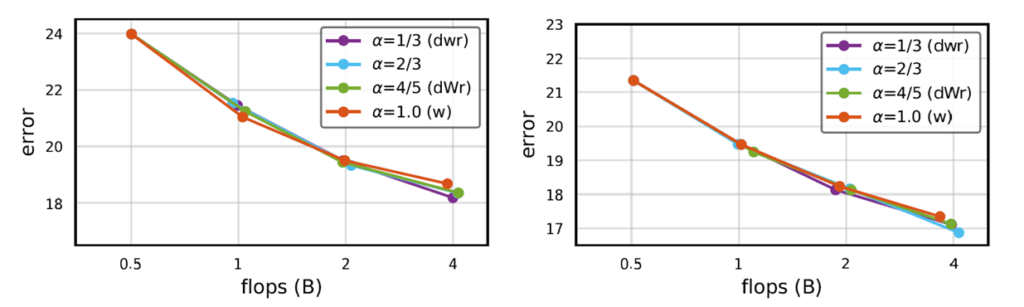
RegNet에서는 정확도가 scaling 기법에 상관없이 대부분 비슷합니다.
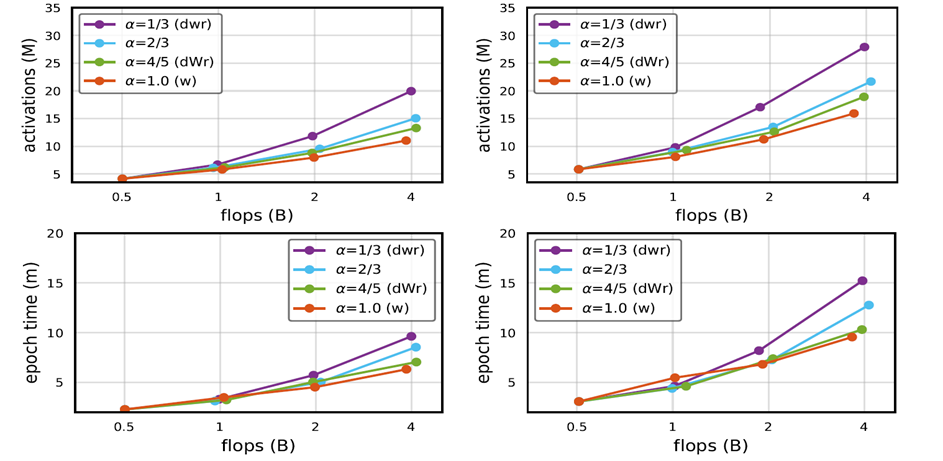
activation의 증가와 Runtime을 비교할때는 두드러진 차이를 확인할 수 있습니다.
확실히 alpha값이 1에 근접할 수록 width에 초점이 맞춰지다 보니깐 activation이 조금씩 증가하고 이로인해 Runtime에서도 좋은 지표를 보여주고 있습니다.
Conclusion
본 Paper의 Contribution을 다음과 같이 정리할 수 있겠습니다.
- Model scaling 기법의 분석을 Flops의 관점 말고도 다른 Metric을 이용해서 설명한점(Activation)
- Accuracy에만 초점이 맞춰줬던 Model scaling 분야에 Speed를 고민하게 만든 점
- 실제로 Accuracy가 높으며 Speed까지 챙긴 Fast scaling 기법을 제안한 점
생각보다 Paper의 아이디어는 간단해서 놀랐습니다.
저자들이 진행한 실험 세팅에 대한 자세한 설명도 나와있어 적용해보고 싶으신 분들은 논문에서 Optimization Setting 부분을 보시면 될 것 같습니다.
Code도 공개가 되어있다고 합니다. https://github.com/facebookresearch/pycls