
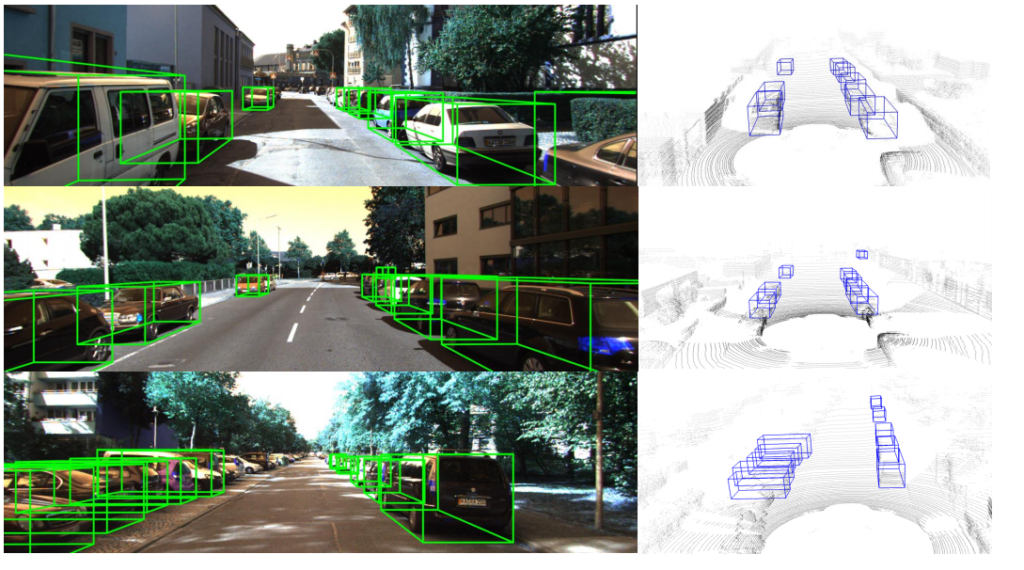
2021년 WACV에 나온 “Cross-Modality 3D Object Detection”논문에 대해서 리뷰를 진행하겠습니다.
Abstract
본 논문에서는 2D 이미지와 3D Point Cloud의 각 장점을 모두 살릴 수 있도록 Fusion을 수행하여 3D Detection을 수행하는 논문입니다. 저자는 2D 이미지는 풍부한 Semantic 정보를 가지고 있으며, 3D Point Cloud는 distance 정보를 가지고 있어 각각의 장점을 모두 잘 살릴수 있도록 각 모달리티를 잘 합치면 더 좋은 3D Object Detection이 가능하다고 이야기합니다. 그리고 저자는 두 모달리티를 잘 Fusion하는 2-stage Architecture를 제안합니다. 본 논문에서 제안하는 아키텍처는 입력으로 binocular(아마도 스테레오…?) 이미지와 raw point clouds를 받으며, 3D Detection 결과를 나타내게 됩니다. 자세한 설명은 뒤에서 다루겠습니다.
Challenges
LiDAR를 통해 얻은 3D Cloud point는 abundant한 Geometry 정보를 카메라로 취득한 2D Image는 rich한 semantic information을 내제하고 있습니다. 2D Object detection에서 딥러닝이 이용되면서 정말 많은 성능 향상이 이뤄졌져 처음 3D Object Detection을 수행하기 위해서 2D Object Detection과 동일하게 접근하였습니다. 하지만 2D Object Detection에서 사용된 방법들은 3D Detection에서 Poor한 결과를 나타냈고, Point Cloud를 사용해 3D Detection을 수행하는 것이 훨 씬 좋은 성능을 나타냈습니다. 몇몇 연구자들은 3D Point Cloud를 2D에 Projection 시켜 Detection을 수행하기도 하였고, 다른 연구자들은 3D와 2D에서 모두 ROI를 추출해 Detection을 수행하기도 하였습니다. 하지만 Projection을 수행할때는 많은 정보가 손실됐고, 2D-3D 모두에서 ROI를 추출할때는 너무 중복된 정보가 많기 때문에 비효율적이였다고 저자는 설명합니다. 이러한 단점을 극복하고자 2D detection을 사용하지만 3D Point를 frustum개념으로 접근하여 3D Detection을 수행하는 방법도 개발됐으나, 이또한 일부분만 사용하는 단점으로 두 모달리티의 정보를 온전히 사용할 수 없다는 단점도 있었습니다. ( frustum 를 사용한 방법은 이전에 리뷰된 글을 확인하시면 됩니다. ) 이처럼 2D-3D 두 정보를 가지고 3D Detection을 수행하기 위한 많은 방법들이 있었지만 각각의 단점들이 존재했다고 저자는 이야기합니다.
Contributions
본 논문에서 저자는 앞서 설명했던 문제를 해결할 수 있는 피처레벨에서 Fusion을 수행하는( 논문에서는 Deeply fused라고 표현함) multi-modal two-stage 3D object detection frame work를 제안합니다. 본 논문에서 제안하는 방법은 2D Image와 3D Point cloud 모두를 온전히 사용하며 각각의 특성을 잘 살리며 Fusion을 수행할 수 있다고 저자는 주장합니다. 해당 프레임 워크는 2 Stage 방식인데 먼저 first stage에서는 raw 3D point cloud를 사용하는 pointnet++와 Resnet-50과 FPN을 적용한 2D 네트워크 백본에서 추출된 각각의 피처맵을 point-wise feature fusion을 수행한다고 합니다. 이때 해당 모델 학습을 위해서 2D detection과 3D detection을 잘 결합하기 위한 새로운 reprojection loss를 제안했습니다. 또 multi modal fusion의 ability를 더 잘 활용하기 위해 First stage에서 생성된 Proposals 내부의 point clouds와 image areas(?)를 모아서 feature map 레벨에서의 결합을 위한 RoI-wise fusion을 적용했다고 합니다. point-wise feature fusion으로 semantic information을 더 풍성하게, RoI-wise feature fusion으로는 robust local proposal representation을 달성할 수 있었다고 합니다. 또 추가적으로 joint anchor mechanism, pseudo LiDAR point clouds등을 사용하였다고 하는데 뒤에서 이야기하겠습니다. 정리하며 본 저자가 주장하는 Contribution은 다음과 같습니다.
- We propose a two-stage fusion framework to combine the best of binocular image pairs and point clouds for 3D object detection.
- By projecting 3D bounding box to 2D image space, we propose a 2D-3D coupling loss to take full use of image information and constrain the 3D bounding box proposal to conform to the 2D bounding box.
- We compensate the sparsity of point clouds by adding pseudo-lidar points to the real 3D scene.
Proposed Method
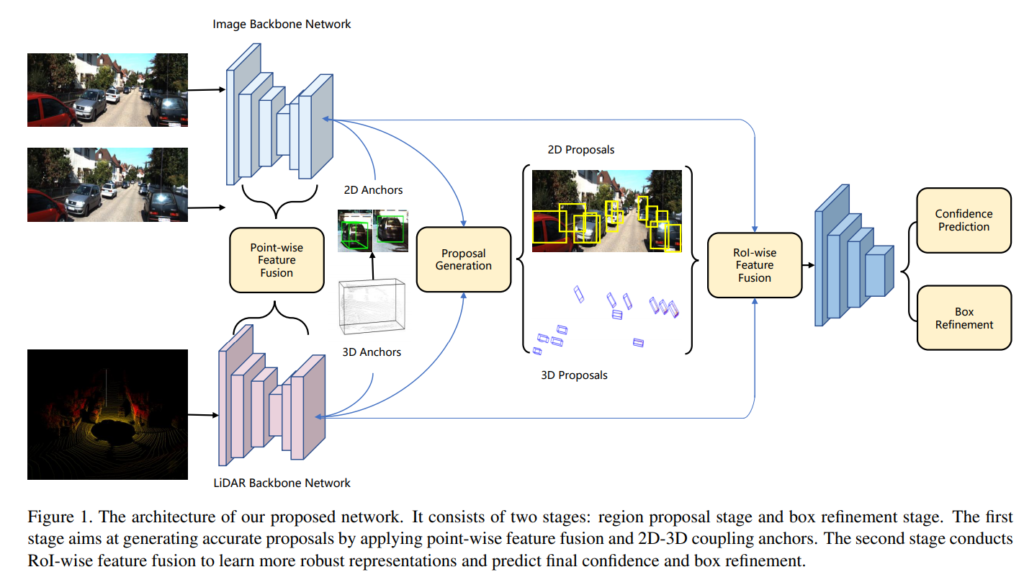
본 연구에서 제안한 아키텍처 입니다.
Feature Extractor
본 논문에서 제안된 아키텍처는 입력으로 binocular(stereo) image와 point cloud를 사용합니다. 앞서 설명했듯 image의 feature 추출을 위해서 ResNet-50과 FPN을 적용한 백본을 사용하였습니다. Point Cloud의 feature 추출을 위해서는 raw 3d point cloud를 사용하는 pointnet++를 백본으로 사용하였다고 합니다. Feature Extractor를 디테일하게 살펴보면 다음 그림과 같습니다.
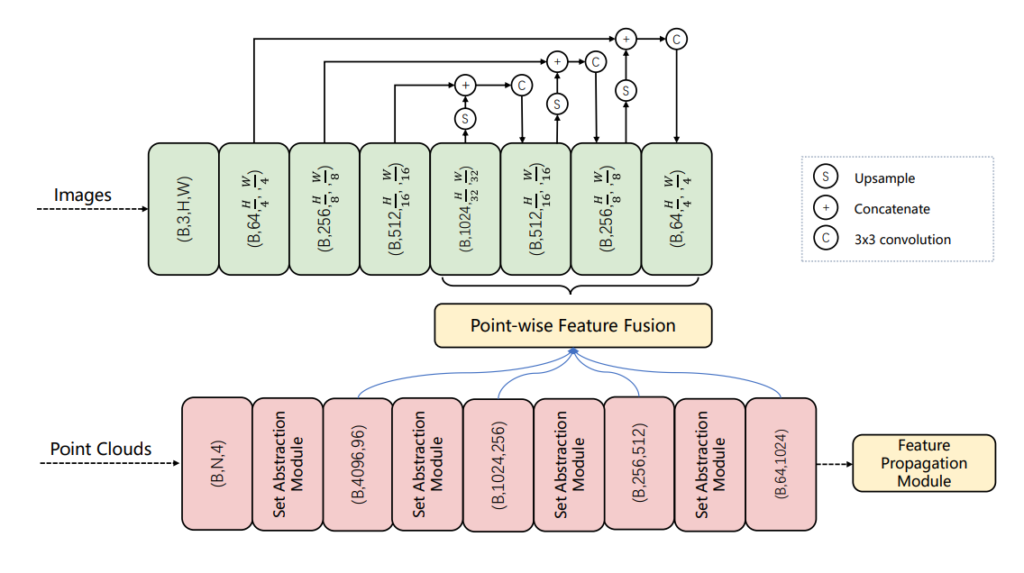
Point-wise Feature Fusion
위의 그림에서 2D Image와 3D Point Clouds의 feature를 추출하는 내용은 쉽게 이해하셨을 것이라고 생각합니다. 그럼 이 두 Feature를 point wise feature fusion을 수행한다는데, 정확히 어떻게 수행하는걸까요? 먼저 X,Y,Z coordinates of points를 4개의 그룹에서 추출합니다. 그리고 해당 포인트를 image feature mpa으로 proection 한다고 합니다. 예를들면 point의 그룹 사이즈가 1024였다면 image featuremap은 (1024,H/32,W/32)로 프로젝션 시켰다고 합니다. 여기서 Pointnet의 방법을 잘 모르시면 헷갈릴수도 있는데 이또한 이전에 리뷰한 글에서 확인하시면 됩니다. (링크)
Joint Anchor
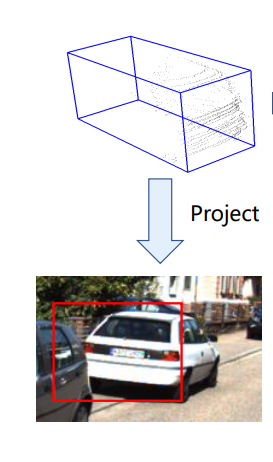
본 논문에서는 2D GT를 얻기위해서 3D anchors를 이용해 2D Anchor를 만들었다고 합니다. KITTI 3D Dataset에는 3D anchor가 존재하는데, 이를 projection하여 2D anchor를 만들었다고 합니다. 이렇게 만든 2D anchor는 scale-adapted하기 때문에 2D anchors of different ratios를 추가적으로 설정할 필요가 없다고 합니다.
Joint Proposal
본 논문에서 제안하는 아키텍처는 classification prediction branch에서 2D-3D anchor pair의 same confidence를 share하도록 force 했다고 합니다. point-wise fused feature에 segmentation head를 적용하여 foreground mask를 예측하였는데, 이때 3D anchor는 각각의 foreground point를 구하고, 이를 image로 projection하여서 2D classification prediction을 수행했다고 합니다. 이때 2D segmentation에는 BCE, 3D segmentation에는 focal loss를 적용했다고 합니다.
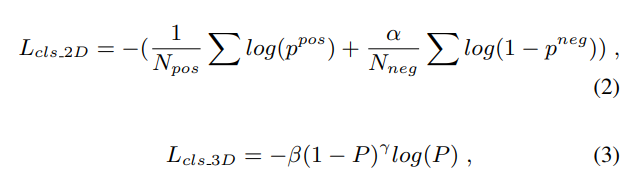
Regression Loss는 2D, 3D에 차이를 추가하여 Loss를 설계했다고 합니다. (디테일한 내용은 논문에서 확인하시길.., 어렵지 않습니다.)
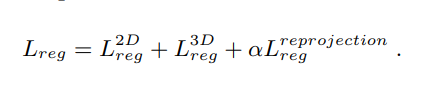
그림으로 표현하면 다음과 같습니다.
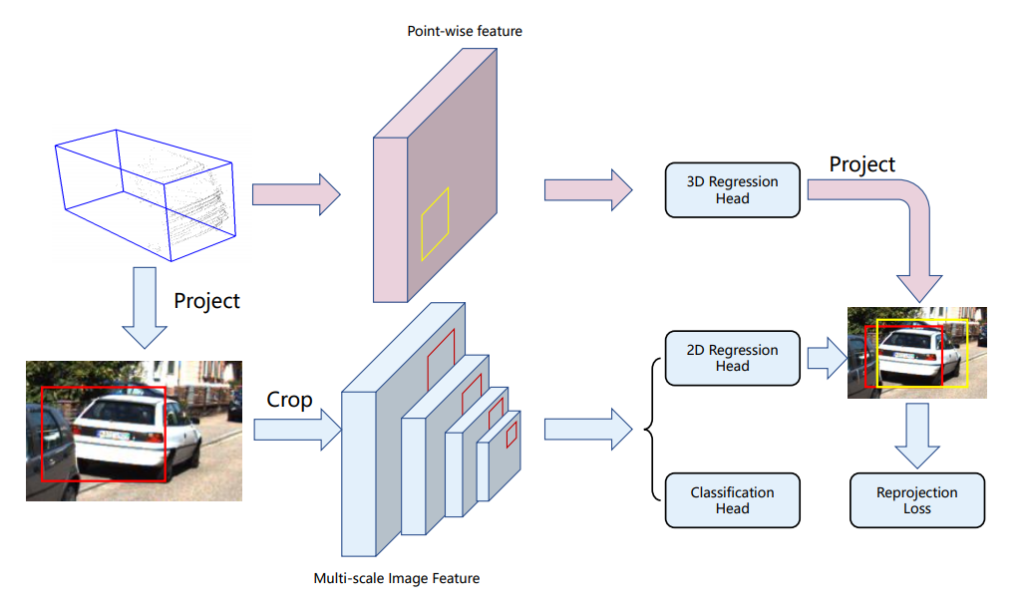
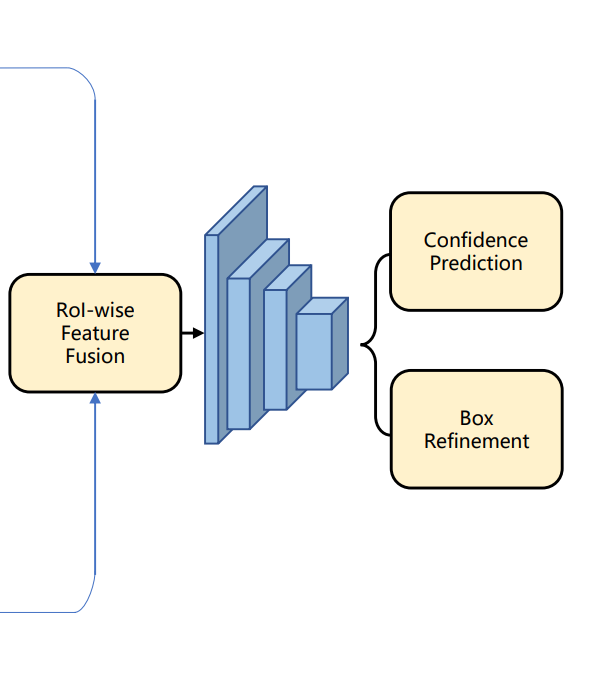
Box Refinement : Proposal-wise(RoI) Feature Fusion
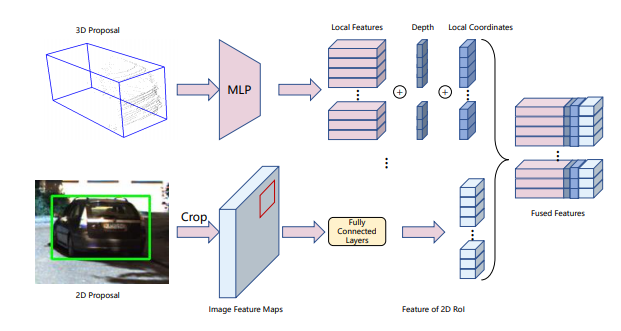
결국 앞에서 2D, 3D 각각에 대해서 proposal을 만들면 해당 proposal에서 각각 모달리티에 대해서 feature를 추출하고 이를 최종적으로 합치고, 해당 fused feature를 가지고 최종적으로 3D box를 구하게 됩니다.
Pesudo-LiDAR Fusion
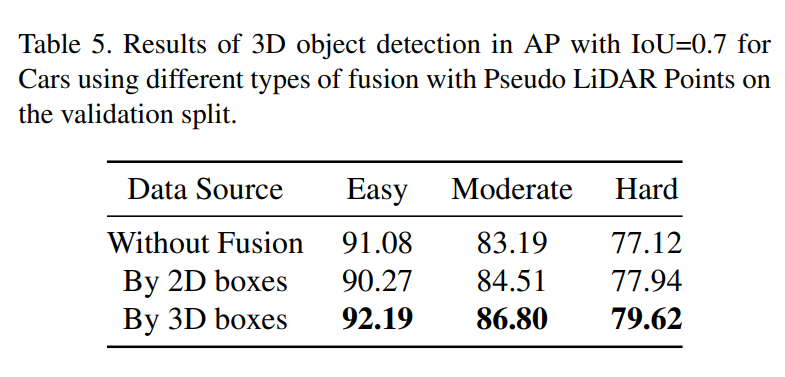
실제 3D point cloud는 너무 sparse하기 때문에 stereo image를 통해서 3D Depthmap을 구하고 거기서 얻은 pesudo LiDAR point를 추가적으로 사용했다고 합니다. 이때 target에 대한 정보만 필요하기 때문에 학습과정에서는 GT 2D boxes 내부의 pseudo LiDAR point만 사용했고, 추론 과정에서는 predicted 2D boxes에서의 pesudo LiDAR point를 사용했다고 합니다.
Experimental Result
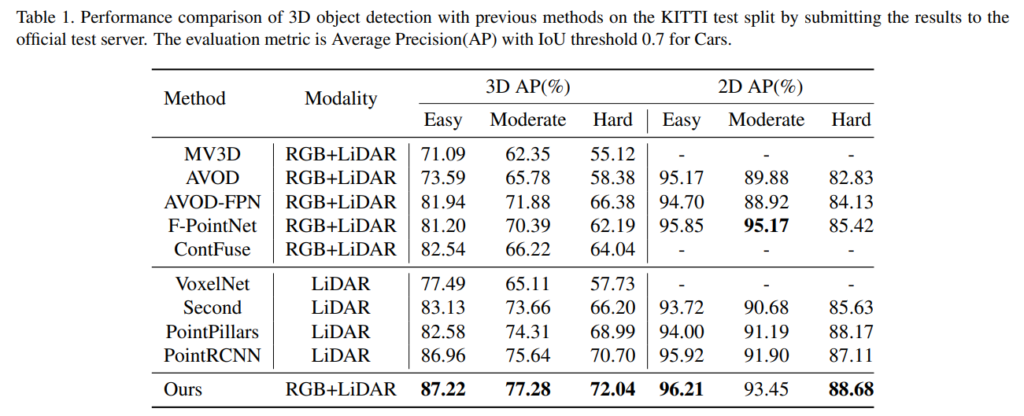
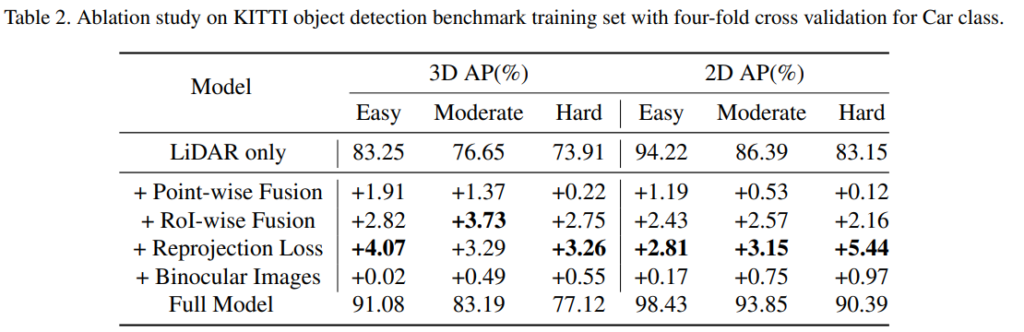
네 뭐 결과는 좋다고 하네요.. 저자 발표영상입니다. 링크 (스크립트 작성해서 읽어주는 프로그램을 사용한것 같습니다.)