이번에 리뷰할 논문은 그동안은 저가 다루지 않은 주제인 Facial Surface Geometry 관련 논문입니다.
Facial Surface Geometry는 쉽게 말해 사람 얼굴에 맞는 face landmarks를 구하는 task로, 페이스메시지나 일반적인 사진 앱에서 사용할 수 있는 AR 분야에 많이 사용되는 것 같습니다.
해당 논문에서는 인공신경망을 통해 3차원 mesh vertices의 위치를 추정하는 문제를 풀고자 하며, 이때 입력 영상은 단순히 핸드폰을 통해 구한 RGB 이미지 한장만으로 깊이 추정 센서 없이 3D landmark를 추정한다는 점에서 의의를 두는 것 같습니다.
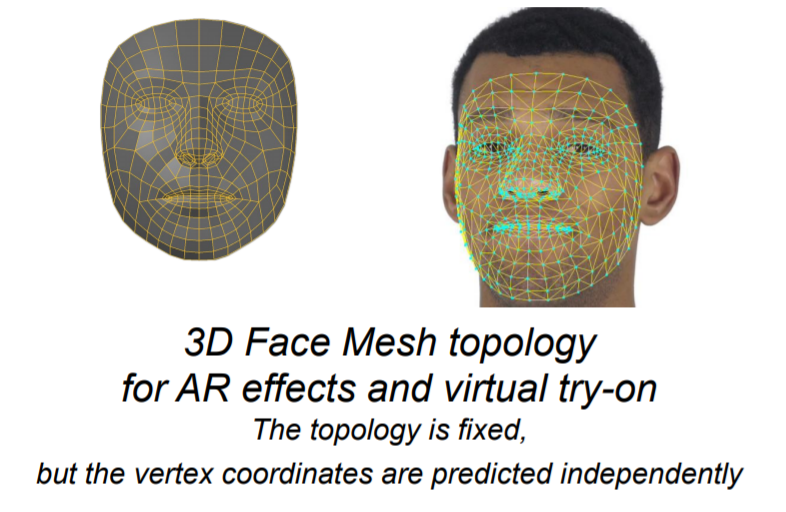
Image Processing Pipeline
먼저 촬영된 영상으로부터 매우 가벼운 얼굴 검출 모델 을 사용하여 얼굴 주변부와 몇몇 landmark 점들(눈 중심, 귀 가장자리, 코 등)을 계산한다고 합니다.
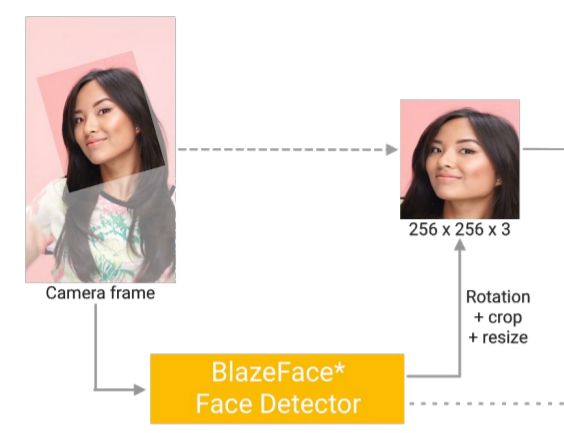
여기서 구한 landmark들은 crop된 얼굴 영상이 사각형과 수평축에 맞는 두 눈 중심을 통과하는 직선과 알맞게 정합되도록 회전하는데 사용됩니다.
그 다음은 이전단계에서 crop, rotation 된 얼굴 영상을 인공신경망에 입력 크기에 맞추어 resize를 해주어야 하는데, GPU를 사용하는 모델의 경우 256 × 256 의 크기로 resize를 하며, CPU를 사용하는 모델의 경우 128 × 128 입력 사이즈를 가지게 됩니다.
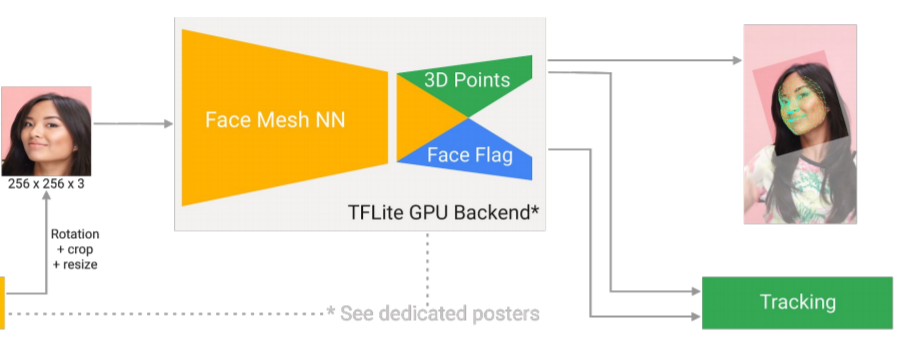
해당 모델은 3D landmark 좌표계를 가지는 vector를 생성하게 되는데, 이는 원본 이미지 좌표계 다시 맵핑됩니다.
또한 face flag 라는 output은 입력 영상(croped face image)이 실제로 얼마나 잘 align이 맞는지에 대한 확률값을 의미합니다.
Landmark에 각 꼭짓점들 중 x와 y 좌표의 점들은 영상 좌표계를 통해 구해진 2차원 좌표 상에 정보들로 사용하였으며, 깊이 정보를 의미하는 z 축 좌표들은 메시의 질량 중심을 통과하는 기준 평면에 상대적인 깊이로 해석했습니다.
그리고 이렇게 구한 좌표들은 x 좌표 범위와 z 좌표 범위 사이에 고정된 가로 세로 비율이 유지되도록 스케일 값을 재조정합니다. 예를 들어 얼굴 영상의 크기가 절반으로 줄어들게 되면, 그 영상에서의 depth range 역시도 동일한 승수로 스케일이 줄입니다.
만약 입력으로 영상이 아닌 비디오가 들어왔을 경우에는, 매 프레임마다 새로 검출하여 위에서 언급한 과정들을 처리하는 것이 아닌, 이전 프레임에서 계산하였던 예측값을 사용함으로써 얼굴 검출에서 불필요하게 사용되는 용량을 줄인다고 합니다.
이 경우, 첫번째 frame 만을 사용하며 이후 프레임에서 새로 얼굴을 검출하는 과정은 거의 드물게 적용됩니다.(사용자가 face flag 확률값에 대한 임계치를 임의로 설정하여 바꿀 수 있습니다.)
이러한 방식 덕분에, 모델이 실질적인 회전과 이동 변환에 대한 상황들에 더 많은 capacity를 사용할 수 있도록 집중할 수 있다고 합니다.
Dataset, annotation, and training
Dataset은 30K 실생활 속 핸드폰 카메라 사진들을 사용하였으며, 기본적인 augmentation 뿐만 아니라 카메라 센서 노이즈 및 영상 명도값에 대하여 random non-linear parameteric transformation을 적용했다고 합니다.
이러한 augmentation은 다양한 조도 환경에서 강인함을 부여하겠죠?
해당 모델은 총 468 개의 3D mesh points를 predict하므로 이를 학습시키기 위한 GT 정보를 구해야합니다. 하지만 실제 얼굴에 468 개의 points에 대한 GT를 사람이 직접 구하기에는 상당히 시간적, 인력 비용이 많이 들며, 정확한 GT를 만들기에도 애매모호한 점들이 많이 존재합니다.
그래서 포인트를 하나하나 annotation 하는 대신, 논문에서는 iterative procedure를 거쳤다고 합니다.
- 먼저 실제 얼굴 사각 사진에 대해 3DMM 모델을 적용시켜 합성 랜더링을 진행합니다. 그렇게 나온 3DMM 꼭짓점들 중 468개의 subset들을 초기 GT로 이용가능하게 됩니다.
- 그 다음은 위에서 구한 mesh vertices의 subset과 대응되는 2D landmarks는 실제 얼굴 데이터 셋에 annotated합니다.(이게 무슨 말이지는 잘 모르겠네요..?)
그 후에는 SOTA 모델을 영상에 적용하여 검출된 에러가 정상범주안에 있는지에 대한 refinement를 위해 알맞는 필터링을 통하여, bootstrap된 x 좌표와 y 좌표점들을 세분화합니다.
Model Architecture
Mesh prediction mdeol의 경우, residual neural network 구조를 사용했다고 합니다. 이전 layer 내에서 보다 공격적인 서브샘플링을 진행하며, shallow part에 대한 계산을 수행하는데 초점을 두었다고 합니다.
이를 통해, 네트워크의 receptive field는 상대적으로 이른 layer에서부터 입력 영상의 넓은 범위를 볼 수 있다고 합니다.
Result
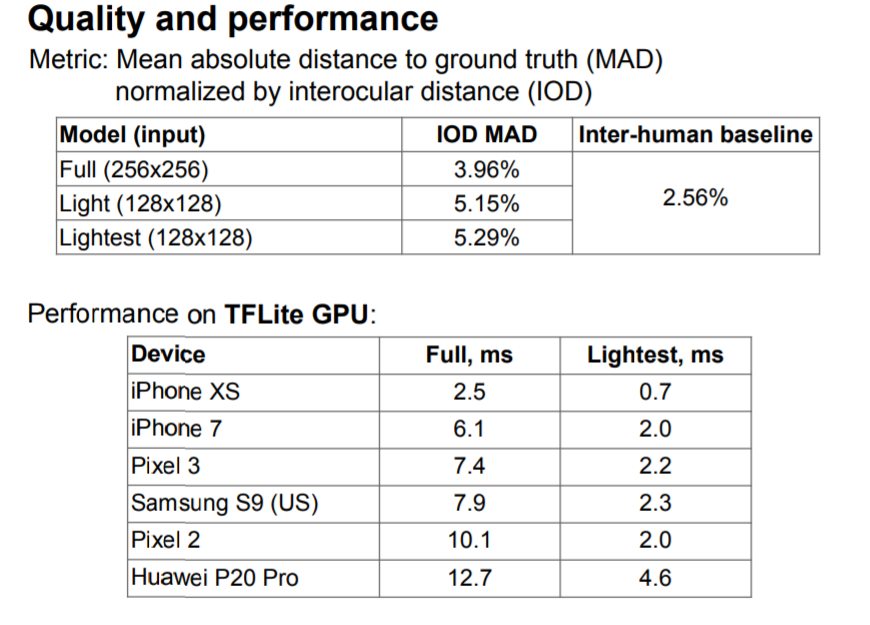
평가 지표로는 예측값과 GT 꼭지점 사이에 거리에 대한 Mean Absolute Distnace(MAD), 그리고 눈 중심 사이에 Interocular Distance(IOD)를 평가했다고 합니다.
z 좌표들은 합성된 데이터 셋을 통한 GT로 학습이 된 것이라, 논문에서는 2D 관련 error만을 리포팅하지만 3D inter-ocular distance 역시도 yaw head roation을 사용하여 계산할 수 있다고 합니다.
평가에 사용된 영상은 총 1.7K 장이며, 정확도 외에도 tensorFlow Lite GPU framework를 기반으로 한 speed 측정도 하였습니다.
결론
workshop 페이퍼라 그런지 내용에 대한 깊이가 상당히 부족하다고 생각됩니다. 네트워크 구조에 대한 세부 그림도 없으며, 추상적으로 이런식으로 작동한다고 언급만 있을 뿐이구요. Capstone에서 사용하기 위한 API인 face-mesh에 대해 알아보고자 읽은 논문인데, 상당히 빈약한 내용에 아쉬울 따름입니다.
gpu와 cpu의 이미지를 다르게 resize하는것은 real-time 으로 동작하기위함 인가요?
네 아마도 논문에서는 결국 성능과 속도 두가지를 모두 잡았다는 것을 강조하기 때문에 cpu에서는 gpu보다 더 작은 사이즈로 resize를 한 것 같네요.
“만약 입력으로 영상이 아닌 비디오가 들어왔을 경우에는, 매 프레임마다 새로 검출하여 위에서 언급한 과정들을 처리하는 것이 아닌, 이전 프레임에서 계산하였던 예측값을 사용함으로써 얼굴 검출에서 불필요하게 사용되는 용량을 줄인다고 합니다.” 라고 하셨는데
만약 영상시작부터 특정시점까지 ‘사람1’이 나오고 그 특정시점 이후에는 ‘사람2’가 나오는 경우, ‘사람1’에서 ‘사람2’로 바뀌는 프레임에서는 이전 프레임의 계산 값을 쓰는 것이 아니라 새로운 계산을 하나요 ?
“이 경우, 첫번째 frame 만을 사용하며 이후 프레임에서 새로 얼굴을 검출하는 과정은 거의 드물게 적용됩니다.”
이 부분이 제가 질문한 부분에 대합 답이 되는 것인가요?
네 논문에서는 두 사람 이상이 나올 경우에 대해서는 전혀 언급된 바가 없어서 정확한 답변을 드리기는 어렵습니다만, 해당 방법론에 대한 데모를 사용해본 기억을 더듬어보면 동영상 속 몇 명에 사람에 대해서 landmark를 계산할 것인지에 대해 미리 세팅을 설정하기 때문에 새로운 사람이 나와서 그 사람에 대한 face flag 값이 이전 프레임에 없는 경우 새로 얼굴을 추정하는 듯 합니다.
그리고 face flag 값이 이전 프레임에서 계산이 되었다고 하더라도, 일정 임계치를 넘지 못할경우 다시 재검출을 하는 것 같구요.