이번 시간에는 2019년 CVPR에서 소개된 6DoF pose Estimation에 관한 논문을 리뷰하겠습니다. 역시나 CVPR에 소개된 논문인 만큼 짜임새있게 구성되어 있네요. 비교적 최신논문인만큼 구글링해도 영문/국문 리뷰가 안나오던데 6DoF Pose Estimation 공부하시는 분들에게 도움이 되게끔 작성해보겠습니다.
앞으로는 논문리뷰를 작성할때, 해당 논문을 최대한 이해해보고 비판/분석적으로 작성을 해볼까합니다. 기존에는 논문을 요약하는데 모든 에너지를 소비하였다고 생각되기 때문입니다. 좀 더 가치있는글은 논문을 요약하는것이아닌 논문을 읽고나서 느낀 생각, 이해를 바탕으로하는 설명 등이 포함되어야 한다고 생각합니다.
가볍게 읽어볼 내용들…
해당 논문의 Introduction에서는 6DoF pose estimation의 중요성, 활용범위, challenging한 요소, 과거/현재의 방법론들을 언급합니다. 관심이 있으신분들은 한번 가볍게 읽어보세요.
Introduction 뒷부분에서는 해당 논문에서 제안하는 방법론들을 소개합니다. 뒤에서 더 자세하게 소개되니 설명은생략하겠습니다.
마찬가지로 Related work에서는 전체적인 흐름을 알려주는데 6DoF pose estimation이 익숙하지 않으신분들은 읽어보시면 도움이 될거같습니다. 저 역시도 익숙치 않아서 한번 읽어보았는데 흥미로운 주제였지만, 논문을 읽고나면 다 까먹을만한 내용들인거같아서 너무 깊게 읽어보시는건 권해드리지 않습니다. 마찬가지로 가볍게 읽어보세요.
해당 논문의 방법론
잡담이 길어졌는데… 먼저 해당 논문의 주제에 대해서 간략하게 소개하면, Single RGB이미지만을 사용하여 6 DoF의 pose를 estimation하는 task입니다. 그 중에서도 occlusion와 truncation에 좀 더 강인하게 작동하는 것을 목표로합니다. 기존 방법론들은 Image coordinates이나 heatmap을 regression하는 방식으로 6DoF pose estimation 문제를 풀었는데 이와는 다르게 voting방식으로 접근하였습니다.

해당 논문의 1페이지에 들어가는 Figure(티저영상) 입니다. 전체적으로 어떠한 원리로 voting이 이루어지는지 추상적으로 보여줍니다. Single RGB 이미지가 인풋으로 들어가고 CNNs를 통해 vector장을 구합니다. 해당 벡터장은 픽셀마다 keypoint의 위치를 가르키는 유닛벡터로 구성되어져있습니다. 이 후 이 벡터들을 이용하여 voting하는 방식으로 keypoint의 위치를 predict합니다. voting할때는 RANSAC-based 방법이 적용되며 이에 대해서는 뒤에서 다시 설명하겠습니다. (g)와 (h) 그림을 잘보면 truncation과 occlusion에 대해서도 강인하다고 어필하려고 노력한 흔적이 보이네요.
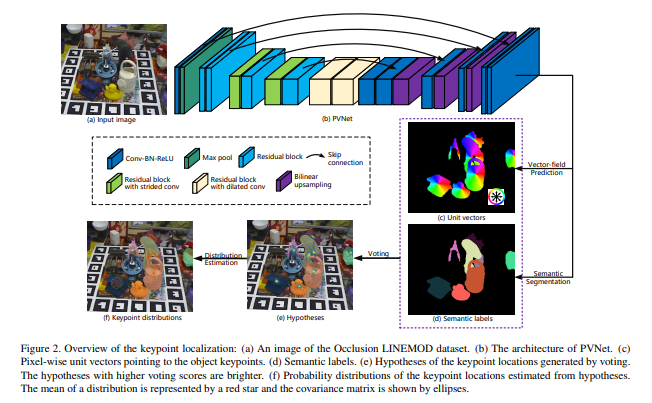
전체적인 아키텍쳐입니다. 앞으로는 제 리뷰에서는 위의 그림처럼 참고하시라고 주석까지 같이 가져올 예정입니다.
해당 논문에서 제안하는 부분은 PVNet으로 (b)에 해당합니다. 실험은 총 4개의 데이터셋에서 진행하였지만, 그중에서 한개는 저희가 이번에 작성한 MLPD논문에서 한것처럼 synthetically generated된 dataset입니다. PVNet은 occluded / truncated image에 좀더 강인하다고 주장을 하고있는데, 그를 확인하기 위해 임의로 가공한 데이터셋이 바로 Truncation LINEMOD dataset입니다. 음… 위의 아키텍쳐 그림에서는 occlusion dataset이 input으로 들어가네요.
Input으로는 항상 2D의 Single RGB가 들어가고, 해당 논문에서 제안하는 PVNet을 거치면서 2가지 task를 simultaneous 하게 수행합니다.
- Vector field Prediction
- Semantic Segmentation
해당 과정을 통해 픽셀마다 어떤 class에 속하는지 Semantic label이 부여가되고, 해당 클래스안에서 keypoint를 가르키는 vector를 얻게 됩니다. 이해를 돕기위해 Figure2에서 일부분을 확대한 그림 몇개를 가지고와서 설명을 이어나가 보겠습니다.
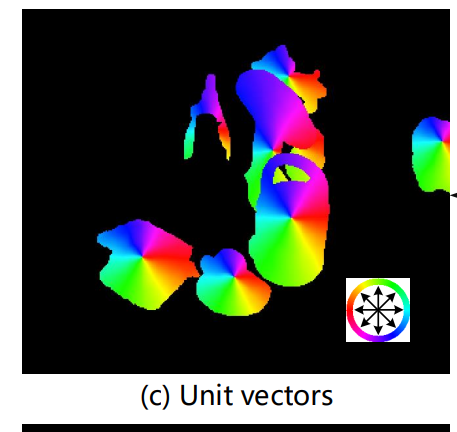
해당부분은 뽑아낸 벡터장입니다. 색상을 화살표로 바꾸어 생각해보면 각각의 instance마다 keypoint를 가르키고있음을 알수있습니다. 이제 이렇게 각 instance마다 있는 keypoint를 RANSAC-based voting방식을 통해서 구하는 과정을 알아봅시다.

결과부터 보자면, voting을 통해 얻은 keypoint hypotheses입니다. Voting을 하는과정에서는 RANSAC-based 방법을 적용해 outlier를 제거합니다. 구체적인 과정은 아래에서 설명을 이어나가겠습니다.
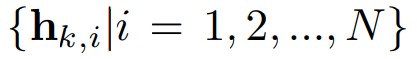
먼저 위에서 h는 hypothesis로 voting을 통해 얻은 keypoint값 입니다. 총 N번의 voting을 할 경우 N개의 hypothesis를 얻을 수 있습니다. voting을 하는 과정은 논문에서는 형식적인글로 설명해야하니 복잡하게 설명된거 같은데 생각보다 간단합니다. 그냥 랜덤하게 2개의 pixel을 고르고 그 pixel에서의 각각의 vector가 가르키는 화살표를 이었을때의 교차하는점을 keypoint로 후보군으로 정합니다. 그렇게 총 N개의 keypoint 후보군을 선정하게 됩니다.
이러한 voting방식이 occlusion과 truncation에 강인하게 할 수 있는 핵심 기술로 작용합니다. 해당 논문에서는 다양한 데이터셋에서 실험적으로 자신들의 주장을 증명하였습니다. 사실… 결과만 놓고보면 vector들이 가르키는 정보가 짤리거나 가려지더라도 keypoint에 대한 정보는 voting을 통해 정해지기 때문에 당연히 occlusion과 truncation에 강인하다고 생각할 수 있지만, 그러한 방법론을 처음으로 생각해내는건 쉽지 않은거 같습니다.
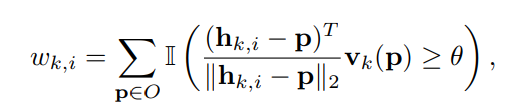
k번째 keypoint에 대한 많은 hypothesis keypoint들 중에서 i번째에 대한 Voting score는 위와같이 정해지게됩니다.
Instance내에 있는 모든 pixel들에서 위의 식에서 threshold값인 세타(0.99)를 넘기는 식의 결과를 모두 더해서 산출합니다. 이때 II는 indicator입니다. (제가 이해하기로는 이런데 그럼 score가 0~1 사이값이 아닌 값이 나오네요? 잘못이해한거 같기도하네요. 혹시 틀린거같으면 댓글남겨주세요)
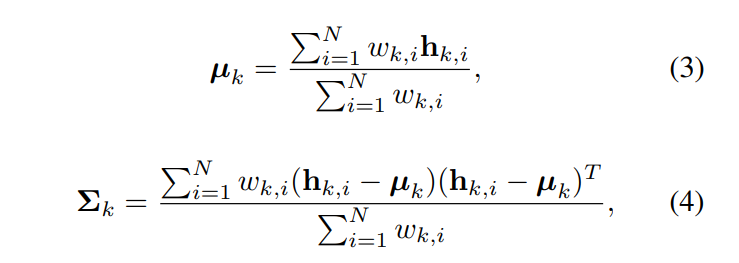

이제 위에서 구한 voting score와 hypothesis를 이용하여 mean(Eq 3)과 covariance(Eq 4)를 구해줍니다. 해당 과정은 그림 (f)에 좀 더 직관적으로 나타나있습니다.
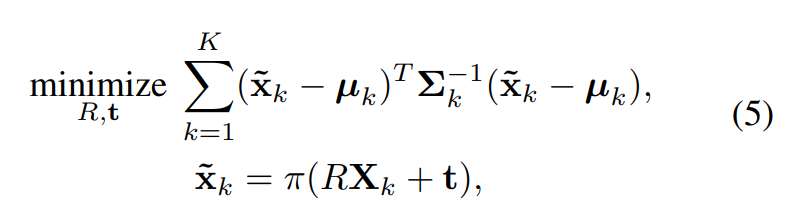
그리고 그를 이용하여 구한 Mahalanobis distance를 최적화 시키는 방향으로의 R과 t(3D pose)를 구합니다. 여기서 x틸다 k는 2D로 proejection된 X_k입니다.
이 다음 수치해석 방법중 하나인 Levenberg Marquardt algorithm을 사용하여 (5)를 풀어줍니다.
Keypoint selection
3D 좌표계상에서의 keypoint selection에 대해서 알아보겠습니다. (위에서 다룬 2D 상에서가 아닌 3D 좌표계 상임을 주의합시다. 저는 해당 부분 때문에 헷갈려서 여러번 반복해서 읽었습니다. 논문에서 명시적으로 언급을 했으면 덜 헷갈렸을거 같네요)
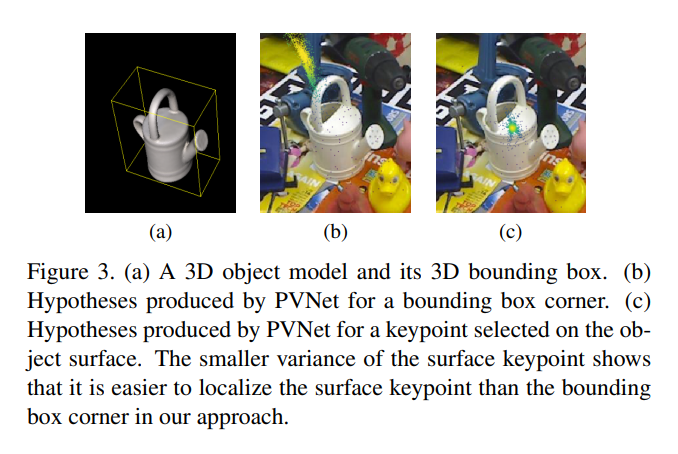
기존 방법론들은 위의 Figure 3. (a)와같이 3D 바운딩박스의 8개의 모서리를 keypoint로 사용하였습니다. 그러나 이러한 접근은 instance내의 pixel들과의 거리가 멀어지면서 localization error를 증폭시킬 수 있습니다. 그래서 PVNet에서는 object의 surface에 keypoint를 위치시키는 방법을 택하고, 이는 variance를 줄일 수 있습니다. 그림 (b)보다 (c)에서 좀 더 조밀하게 (variance가 작게) 나타남을 볼 수 있습니다.
PVNet에서는 물체의 표면에 있는 총 8개의 keypoint를 사용합니다. 이는 computation time과 accuracy의 trade-off를 고려하였을때, 실험적으로 나온 결과입니다. object의 centre를 기준으로 초기화하고, 그로부터 가장 먼 곳을 keypoint로 더해나가는 식으로 총 8개의 keypoints를 선택하게됩니다.
예시를 통한 설명
이번에는 이해를 돕기위해 예시를 들어서 설명을 하겠습니다.
2D의 RGB이미지가 (H, W, 3)의 shape를 가졌다고 해봅시다.
PVNet을 통과하면 총 2개의 tensor가 output으로 나옵니다.
각각의 tensor는 마지막 1×1 conv를 통해 feature map을 통과하고 아래와 같이 나옵니다.
- H ×W ×(K ×2×C)
- H×W ×(C+1)
이런식으로 나오게됩니다. 우선 1번 tensor에 대해서 설명하자면, K는 keypoint의 개수로 실험적으로 8개로 정한 값입니다. 2는 벡터의 방향을 나타내는 i, j 성분이고, 어떤 클래스에 속하는지 one-hot-encoding형태의 값 일 것입니다. (이해를 바탕으로 추측한 값입니다. 논문에는 해당값들이 어떠한 것을 represent 하는지 나와있지 않습니다.)
2번 tensor는 1번보다 훨씬 쉽게 Class 혹은 background일 가능성에 대한 score로 나옵니다.
좀 더 구체적으로, 1번 tensor는 각각의 pixel마다 (K ×2×C) 의 정보를 담고 있습니다. 그리고 그 정보는 해당 픽셀에서 각각의 keypoint들에 대한 vector값과 어떠한 class에 속하는지에대한 정보를 담고있습니다.
평가
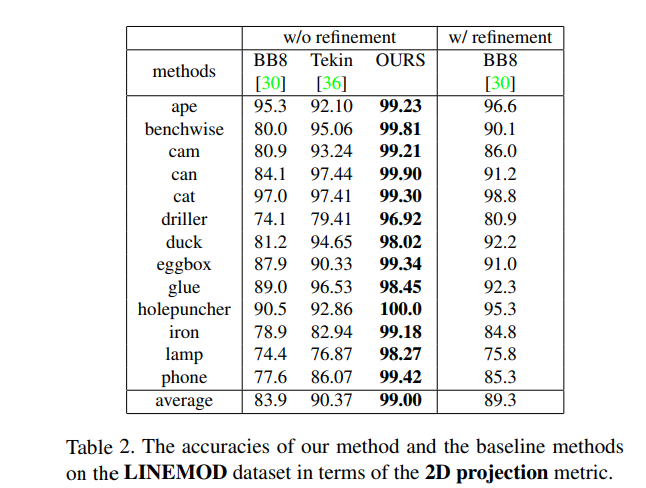
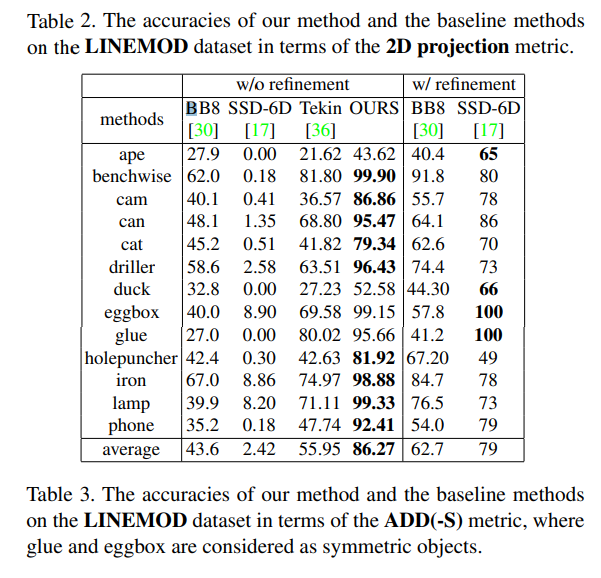
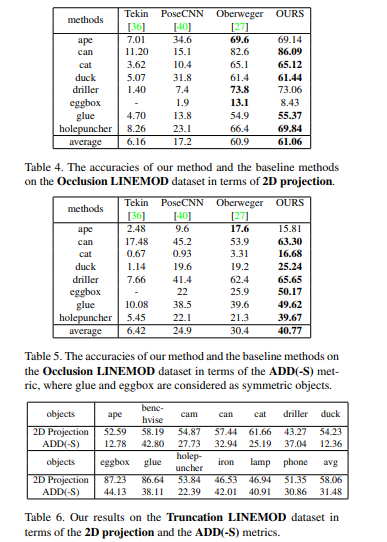

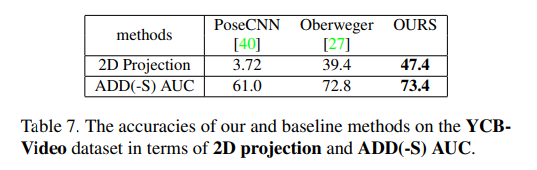
결과는 위와 같습니다. 3개의 dataset과 truncation case를 평가하기위한 sythetically generated dataset 1개를 포함하여 총 4개의 dataset에서 SOTA를 달성하였습니다. 상당히 높은 margin을 가지고 SOTA를 찍었는데 해당 기여만으로도 충분히 논문을 쓸 거리가 되는거 같습니다.
아직 해당분야에 부족하지만 잘 쓰여진 논문이여서 이해하는데 많은 도움이 되었습니다. 역시 CVPR논문은 믿고 읽을만 한거 같습니다.
이상 리뷰 마치겠습니다.
벡터장을 구한다고 하셨는데 해당 벡터를 구하는 네트워크에서 GT는 무엇인가요?
벡터장은 픽셀마다 총 8개 벡터들로 이루어져있습니다. 여기서 8은 하이퍼파라미터지만 실험적으로 8을 사용했습니다. 8개의 벡터는 각 인스턴스의 표면에 있는 keypoint를 가르킵니다. 따라서, 인스턴스 표면에 있는 keypoint가 GT입니다.
좋은 글 감사합니다.
먼저 첫번째 궁금한 점이, N번의 voting에서 N은 사용자가 지정하는 하이퍼파라미터 인가요?
그리고 voting을 한다는 것이 임의의 두 픽셀(벡터)가 연장선을 그려 교차하는 지점을 후보군으로 정하는 것인가요 아니면 거기서 더 나아가 voting 스코어를 계산하여 평균과 분산을 계산하는 과정까지를 말하는 것인가요?
첫번째 질문에 대한 답은 YES입니다. 그리고 두번째 Voting 은 후보군을 정하는것 까지이고 voting score
및 평균과 분산은 뒤에 PnP 계산에 활용됩니다.
벡터장과 Segmantation 정보다 Loss구할때 사용되는 건가요?
네 output 으로 나온 텐써는 2종류가 있는데 그중 classification 을 위한 tensor에서는 각 픽셀이 어디에 속하는지, 즉 Seg 정보가 들어갑니다. 벡터장 텐서에서는 3D 에서의 자세추정을 위한 keypoint 를 가리키고있는 벡터장의 정보가 들어갑니다. 이 둘 텐서 모두 당연히 loss를 설계하고 이를 최적화시켜서 학습됩니다.