

다양한 길이를 가진 video 연구에서는 비용적인 측면을 고려해서 모든 프레임을 사용하여야 하는가에 대한 여러 연구들이 진행되어왔고, 최근 연구들은 연속된 프레임 간의 정보보다 특정 프레임 내의 영상정보가 더 중요하다고 결론을 내려왔습니다. 이러한 특정 프레임은 단순 하나의 프레임만으로 프레임 간의 변화에 강인하며 어떤 행동이나 사건에 대한 정보를 가장 많이 줄 수 있는 프레임으로 정의되어져 왔으며, 이를 motion-invariant한 프레임이라고도 부릅니다. 결국, video 연구에서 motion-invariant한 프레임을 뽑는 keyframe selection은 video 내의 모션으로 인해 블러가 포함된 프레임을 사용하지 않기에 성능 향상의 요인일뿐더러 연산 및 메모리와 같은 비용적인 측면에서도 큰 이점을 줄 수 있게 됩니다.
그러나, 이와 같은 keyframe selection에서는 motion-invariant가 어떤 것인지를 정의하기도 쉽지않으며 이에 대한 연구도 많지 않습니다. 저 또한 이러한 keyframe selection을 통해 video to video retrieval 문제를 해결하려했으나, 아직은 약한 내공으로 부딪혀보았으나 쉽지 않음을 깨닫게 되었고 한단계 낮춰 motion-invariant한 frame이 있을 확률이 있는 영역인 temporal segment를 찾아 video to video retrieval을 해결하는 것으로 문제를 재정의해 재도전하고 있습니다. 이를 위해 temporal segment 관련 논문을 찾아보던 중, TSN(Temporal Segmentation Network)이라는 논문이 이제까지 사용해왔던 몇몇 video 연구에서 프레임 추출과 학습을 위해 쓰여왔던 것과 어떤 식으로 쓰였는지는 알았지만 논문은 따로 읽은 적이 없어, 정독을 통해 저자에게서 영감을 얻을 수 있지 않을까 하는 마음에 해당 논문을 읽게 되었습니다.
1. Motivation
해당 논문이 제출된 해인 2016년도에 video 관련 연구인 action recognition 분야에서는 short-term motion에만 초점을 맞추고 있는 문제와 데이터 셋의 부족이라는 두가지 문제를 겪고 있었습니다. 분명히 motion을 long-term으로 보는 것이 직관적으로 좀 더 많은 정보를 이용할 수 있기에 이점이 있지만 연산 비용에 대한 문제가 있었고, 데이터 셋으로는 그 당시 action recognition을 위해 주로 사용되는 것이 UCF101과 HMDB51뿐이었습니다. 이러한 문제들을 해결하기 위해 저자는 1) long-range temporal 구조를 효율적으로 학습하는 video representation learning framework인 TSN과 이를 2)제한된 데이터를 이용하여 학습하는 방식에 초점을 맞춰 연구를 진행하였습니다.
2. Action Recognition with Temporal Segment Networks
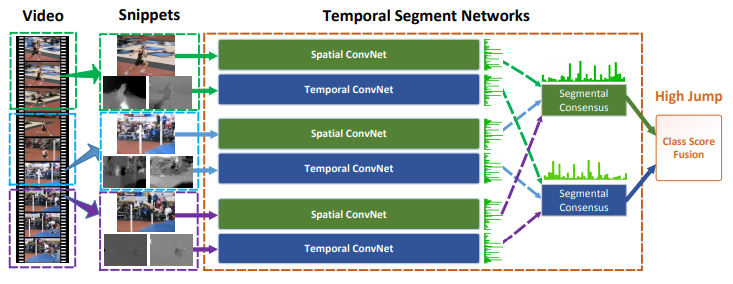
2.1 Temporal Segment Networks
이전에 short-term 영역만 보던 two-stream 방법론들은 스포츠와 같이 여러 동작으로 구성되어 long-term 영역을 활용했을 때 효과적인 행동들을 판단할 때 여러 손실들이 있었습니다.
TSN은 마찬가지로 이미지를 통해 spatial한 정보를 보는 convolution layer와 optical flow를 통해 temporal한 정보를 보는 convolution layer로 구성되어 two-stream 방법론이며, 다만 행동을 판단할 때 전체 video의 long-term 영역에서 sparse하게 snippet이라고 부르는 프레임과 이의 optical flow를 추출해 입력으로 사용하는 부분에서 차이가 있습니다.
추출하는 방법은 모든 video를 일정 간격으로 k개로 분할하는 것이며, 각 분할에서 하나씩 snippet을 뽑아 video-level의 prediction을 진행합니다. 그리고 k개의 prediction 값을 two-stream의 segmental consensus 모듈에 넣어 최종 class prediction 값을 선정하게 됩니다. Segmental consensus 모듈은 최댓값, 평균값, 가중평균값으로 실험시 사용했다고 합니다.
2.2 Learning Temporal Segment Networks
Convolution layer는 Batch Normalization이 포함된 Inception Network를 사용하였으며, 이 당시 입력으로는 이미지와 optical flow를 넣는 것이 일반적이었으나 본 논문에서는 이외에도 RGB difference와 warped optical flow field라는 것 또한 입력으로 실험하였습니다. RGB difference는 연속된 프레임 상에서의 변화를 의미하며, warped optical flow field는 연속된 프레임에서 카메라의 이동 정보를 homography 계산하여 카메라 이동 정보를 없애 video 내 물체의 행동에 좀 더 집중시킨 optical flow를 의미합니다.
그리고 학습 시, 데이터가 많지 않은 action recognition 특성 상 overfitting을 막기 위해서 Cross Modality Pretraining, Regularization Techniques, Data Augmentation을 진행하였습니다.
Cross Modality Pretraining은 크기가 작은 데이터 셋에서 Pretrained 파라미터를 사용하는 것이 효율적이라는 생각으로부터 시작하여, 이미지가 입력으로 들어가는 Spatial convolution layer 의 파라미터로 optical flow의 Temporal convolution layer의 pretrained 파라미터로 사용하는 것을 의미합니다. 단순히 Spatial convolution의 첫번째 convolution의 파라미터를 채널 별로 평균내고 이를 optical flow의 입력 채널만큼 복사해서 사용하는 것입니다.
Regularization Techniques은 첫번째 Batch Normalization layer를 제외하고 모든 layer의 mean과 variance를 freeze 시키는 partial BN과 global pooling layer 이후에 추가된 dropout으로 구성되어있습니다. Batch Normalization은 학습 수렴 속도 향상에 도움을 주나, 양이 적은 데이터 셋에 대해서는 overfitting을 야기할 수 있기 때문에 freeze를 시키며, 첫번째 layer에서는 RGB pretrain 파라미터로 초기화 되어 이를 optical flow에 맞춰 조정이 필요하기에 freeze 시키지 않았다고 합니다.
Data Augmentation 으로는 기존 사용하던 random cropping과 horizontal flip에 이어 corner cropping과 scale jittering을 추가하였습니다. Corner cropping은 모델이 암묵적으로 이미지의 중심부만 보게 하지 않도록 corner 부분과 중심 부분을 번갈아가며 사용하는 방식이며, scale jittering은 256, 224, 192, 168 중 랜덤한 크기로 crop한 뒤 224 크기로 resize하는 방식을 의미합니다.
3. Experiments
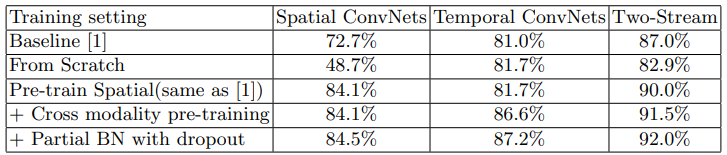
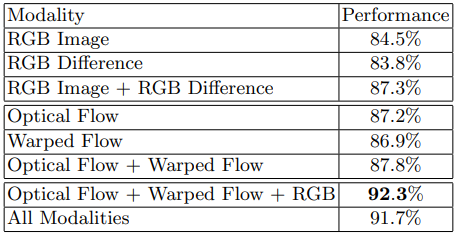

Table 1은 앞서 TSN을 학습시킬 때, overfitting을 막기 위해 도입한 방법들과 모델 각 stream의 ablation study이며, Table 2는 입력으로 RGB Difference 혹은 Warped flow를 추가하였을 때 ablation study 입니다. 그리고 Table 3은 Segmental Consensus 모듈에 대한 ablation study 결과 입니다.
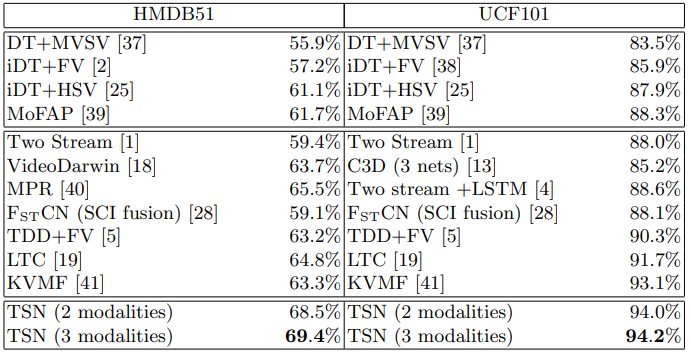
Table 4는 당시 SOTA들과의 비교 결과 입니다. C3D나 LSTM보다 좋은 성능을 보인 것이 눈여겨볼 점입니다.
본 논문에서 제안한 방법론은 아쉽게도 segment를 어떤 기준을 통해 동적으로 나눈 것이 아닌 일정한 길이로 나누는 정적 분할이라고 봐도 될 것 같습니다. 이러한 이유로, 당시에는 분명 SOTA의 성능을 내었고 현재 몇몇 방법론 들에서도 이 논문의 학습 방식이나 분할 방식을 차용하고 있을만큼 좋은 방법론인 것은 분명하나 결국 video를 나눠주는 값인 K는 하이퍼 파라미터이며 프레임 내의 정보를 활용한 분할이 아닌 일정 길이로 동일하게 나누는 분할이기 때문에 제가 하고자하는 연구와는 거리가 있는 방법론인 듯합니다.
4. Reference
[1] https://arxiv.org/pdf/1608.00859.pdf