현존하는 Image to Image translation 기법들은 2개의 도메인에 대해서는 아주 잘 작동하지만, 2개 이상의 도메인에 적용할 때는, 적용하거나 확장하기에 상당히 제한적입니다.
그 이유는 모든 도메인 쌍마다 독립적으로 모델들(Generator & Discriminator)들이 존재해야하기에, 도메인이 늘어나면 늘어날수록 Generator 등의 모델들도 많아 지기 때문이죠.

간단한 예시를 먼저 알아보겠습니다. Image to Image Translation work중 유명한 CycleGAN에서 실험으로 했던 것들은 주로 segmentation label을 실제 영상으로 변환하거나, 흑백 영상을 컬러 영상으로 변환하거나, 말을 얼룩말로 변환하는 등 2개의 도메인 사이에서 변환하는 Task를 수행하였습니다.

하지만 사람의 얼굴을 바꾸는 task에서는 어떨까요? 물론 CycleGAN도 사람의 얼굴을 바꾸는 task를 잘 수행합니다. 하지만 사람의 성별뿐만 아니라, 나이, 머리색깔, 피부톤, 감정의 정도 등 수많은 특징들 수행하기 위해서는 각 도메인들끼리에 대한 모델들이 독립적으로 필요합니다.
그래서 도메인이 늘어나면 늘어날수록, 모델도 동시에 늘어나게 되며 이는 사람이 해당 task를 수행하기 위한 핸들링 작업 및 학습에 사용되는 자원이 많이 필요하게 되죠.
이러한 문제를 해결하기 위해 StarGAN이 제안되었으며, StarGAN은 오직 하나의 모델만으로 multi domain에 대한 문제를 해결할 수 있습니다.
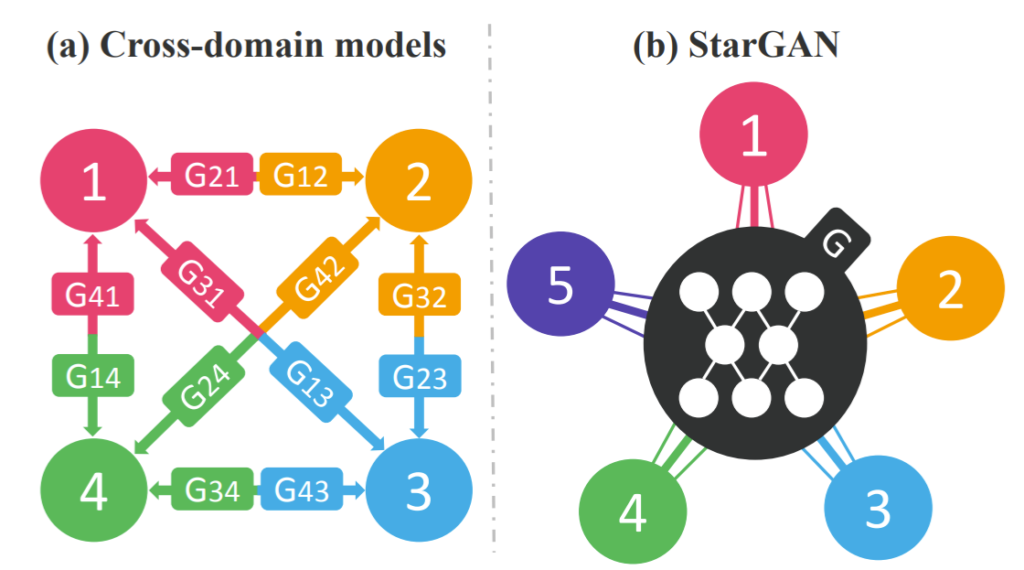
그림3을 보시다시피, 기존 cross-domain model의 경우 4개의 다중 도메인을 학습시키기 위해서는 4*3=12 개의 generator가 존재합니다. 이러한 구조는 각 도메인쌍 끼리만 학습하기 때문에, 얼굴의 형태와 같이 모든 도메인에서 나타나는 Global feature들에 대해서는 효율적으로 학습하지 못하게 됩니다.
하지만 StarGAN의 경우 하나의 generator을 이용하여 다중 도메인으로의 mapping을 학습하게 되는데, 방식은 다음과 같습니다.
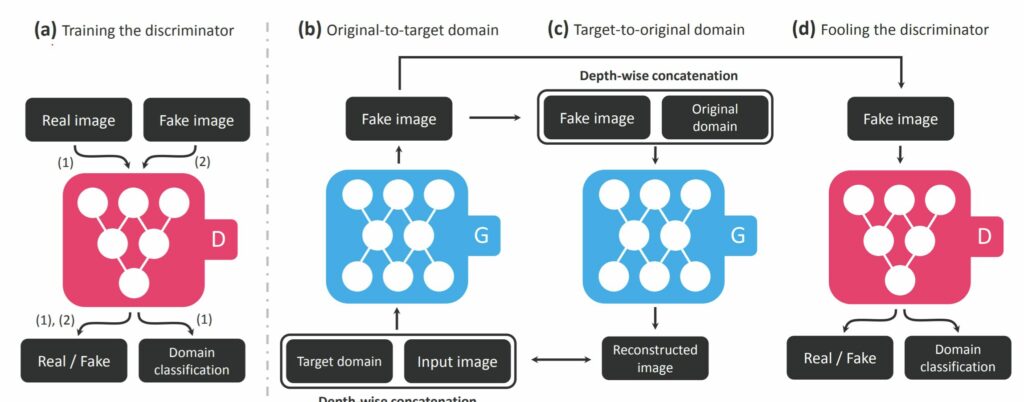
흑발에서 금발로 바꾸는 것과 같이 고정된 도메인 사이에서 학습하는 것 대신, StarGAN은 입력으로 양쪽 도메인의 영상과 정보들을 사용합니다. 그리고 연관있는 도메인 영상으로 mapping하는 것을 학습합니다.
도메인 정보는 이진 또는 one-hot vector로 이루어진 label이며, 학습하는 동안 랜덤하게 목표 도메인의 label을 생성하고, 모델이 입력 영상을 목표 도메인으로 유연하게 변환할 수 있도록 학습하게 됩니다.
그 다음 test 단에서 사용자가 임의로 domain label을 어떻게 주느냐에 따라서 우리가 원하는 도메인(target domain)으로의 변환이 이루어지게 됩니다.
StarGAN Network
Adversarial Loss
Adversarial Loss는 GAN의 가장 일반적인 loss이기 때문에 간략하게 설명하거 넘어가겠습니다.
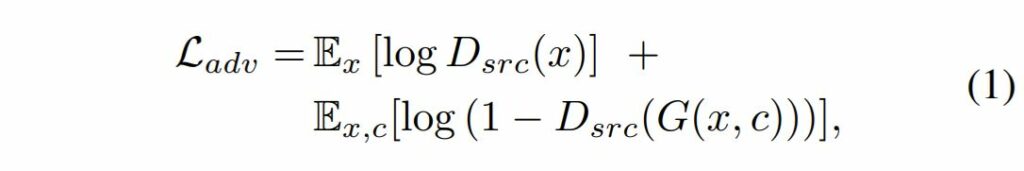
수식1은 adversarial loss를 나타낸 것이며, Generator는 입력 영상 x에 대하여 target domain과 최대한 유사한 영상을 만드는 것이 목표이며, D는 G가 만들어낸 가짜 영상 G(x)를 진짜 영상과 구분하도록 학습합니다.
여기서 기존 GAN loss와 다른 점이 있다면, target domain label인 c가 G의 입력으로 같이 들어간다는 점이겠네요.
Domain Classification Loss
주어진 입력 x와 목표 도메인 label c에 대하여 우리의 목표는 x를 c에 해당하는 도메인 속 영상 y로 변환시키는 것입니다. 이를 위해 StarGAN은 D의 제일 끝에 보조적인 분류기를 추가했습니다.이 분류기는 도메인 분류 loss를 나타내며, D와 G 모두를 최적화합니다.
해당 object loss를 2개의 텀으로 분리시킬 수 있습니다. 먼저 하나는 D를 최적화하는데 사용하는 실제 영상의 도메인 분류 loss와, G를 최적화하는데 사용되는 가짜 영상의 도메인 분류 loss로 말이죠.
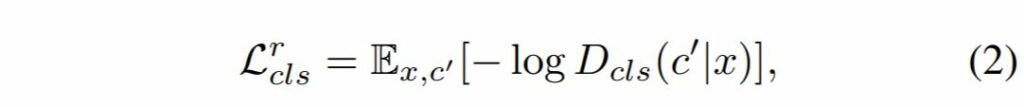
보다 자세하게는 수식 2와 같이 표현할 수 있는데, D_{cls}(c' |x) 는 D를 통해 계산된 도메인 label의 확률 분포를 나타냅니다.
해당 목적함수를 최소화함으로써, D는 실제 영상 x와 그것의 대응되는 원본 도메인 c’를 분류할 수 있게 됩니다.
반대로 가짜 영상에서의 도메인 분류 함수는 수식 3과 같습니다.
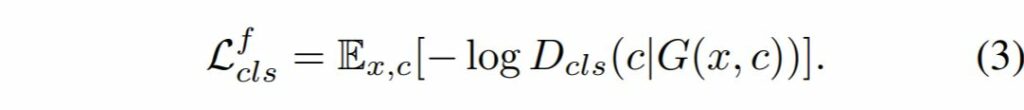
G는 목표 도메인 c로 분류되기 위한 영상들을 생성하기 위해서 수식 3과 같은 목적함수를 최소화하고자 학습할 것입니다.
Reconstruction Loss
Adversarial 과 classification loss를 최소화함으로써, G는 실제와 유사하며 목표 도메인과 상당히 유사한 영상들을 생성하게 됩니다.
하지만 위에 loss들(수식1~3)을 최소화하는 것은 입력 영상의 컨텐츠를 보존하면서 타겟 영상으로의 전환이 이루어진다고 보장할 수 없습니다. 반면에 입력 영상 중 도메인과 연관된 부분들만이 바뀌는 결과를 나타낼 수 있게됩니다.
이게 무슨 의미냐면, 지난번 제가 작성한 CycleGAN 리뷰에서도 설명드렸지만 대부분의 Image to Image translation은 unpaired한 데이터셋으로 학습하게 됩니다.
여기서 일반적인 GAN Loss(Adversarial Loss)만을 사용하게 되면, 출력 영상이 입력 영상의 어떠한 structure와 content를 표현하지 못하더라도 target domain의 texture나 content를 가지게 되면 Discriminator가 real과 fake를 구분하지 못하게 되는 것을 의미합니다.
보다 자세한 설명은 저가 지난번 작성한 CycleGAN x-review를 참고하시면 좋을 것 같습니다.
무튼 이러한 문제를 해결하기 위해서 StarGAN에서도 CycleGAN에서 사용한 cycle consistency loss를 사용했다고 합니다.
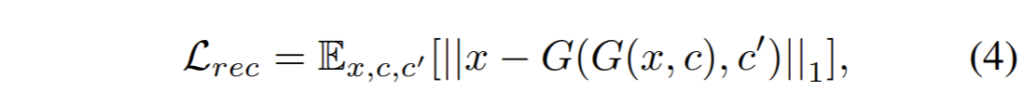
입력영상 x와 변환시키고자 하는 목표 도메인의 label c를 G를 통해 생성한 output 영상 G(x,c)를 다시 원본(x) 도메인 c’과 함께 G의 입력으로 한 것이 실제 원본 x와 동일해야한다~ 라는 개념의 reconstruction loss는 GAN loss가 입력 영상을 G에 태워 출력 영상으로 만들 때 완전히 새로운 영상으로 만들지 않고, 최대한 입력 영상의 form을 유지한체 만들도록 제약 조건을 추가한 것입니다.
Full Objective
최종적인 total loss는 수식 5~6과 같습니다.
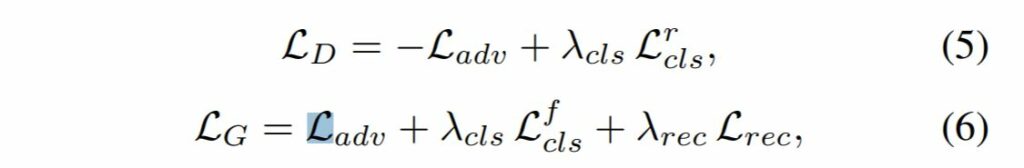
여기서 \lambda_{cls}, \lambda_{rec} 는 하이퍼 파라미터로, 도메인 분류와 reconstruction loss의 정도를 컨트롤하는 값이며 startGAN에서는 각각을 1과 10으로 지정했다고 합니다.
Experiments

그림5의 정성적 결과를 살펴보면, cross domain model 기반 방법론들은 1열, 2열, 3열, 4열과 같이 2개의 도메인에서 잘 작동하는 것을 보입니다. 하지만 그 외에 도메인이 3개 이상이 되는 순간부터는 점차 결과가 좋지 못한 모습을 보이죠.
하지만 StarGAN의 경우에는 하나의 Generator를 사용함으로써, 모든 도메인의 공통적인 global feature를 잘 학습하여 여러 domain에서도 우수한 성능을 보이고 있습니다.
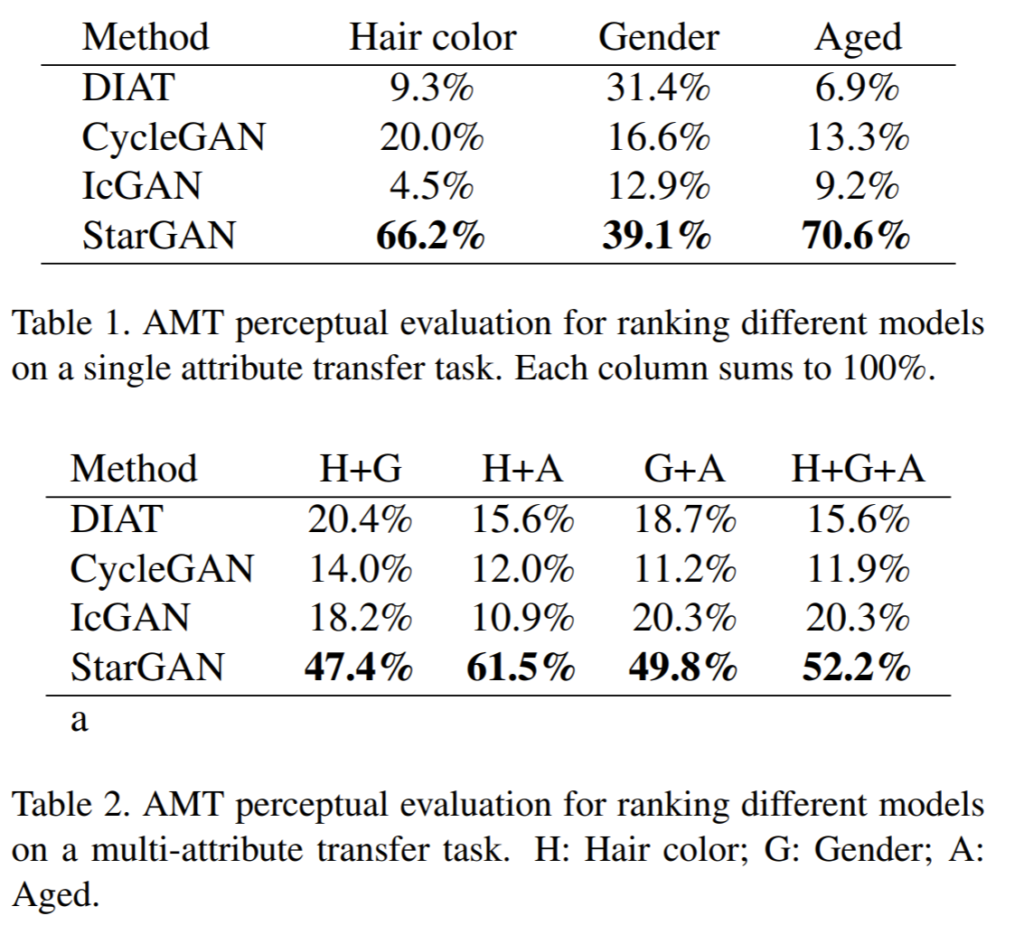
정량적 결과는 다른 모델들과 StartGAN으로 통한 결과를 사람들에게 가장 자연스러운 영상이 무엇인지 voting하는 방식으로 평가되었으며 여기서 StarGAN이 제일 좋은 결과를 도출해냈습니다.
혹시 실험중에 다양한 도로씬 데이터셋에 대한 변환 같은 것은 없었나요…? 있었으면 좋겠네요,….하하하하