
- Motivation
Semantic label map으로 부터 실제 영상을 만드는 image to image translation (i2i) 방법론들이 visualization 위해서 많은 연구가 진행 되어 왔다. 대표적으로 GAN을 이용한 pix2pix가 나쁘지 않은 성능을 보이며 혁신을 이끌었다. 하지만 pix2pix를 비롯해 기존 방법론은 low resolution 에서만 동작하기 때문에 4k까지 보는 요즘 시대에 매우 뒤떨어진 영상을 생성했다. 이 논문에선는 2048*1024로 high resolution에 영상을 생성할 수 있는 방법론을 pix2pix 기반으로 제안한다.
high resolution 으로 영상을 생성할때 생성되는 영상의 detail을 살리기 위해서 다음과 같은 방법론들을 적용했다.
- Coarse-to-fine generator : Sub network 를 이용해 high resolution의 디테일을 보완
- Multi-scale discriminators : 판단자인 Discriminator 가 Multiscale 에서 판단하여 보다 scale 에 강인하도록 설계
- Using Instance Maps : 생성되는 영상속 물체들의 바운더리를 명확하게 해서 물체의 디테일을 살리기 위해 Instance map의 Edge를 사용
2. Pipeline
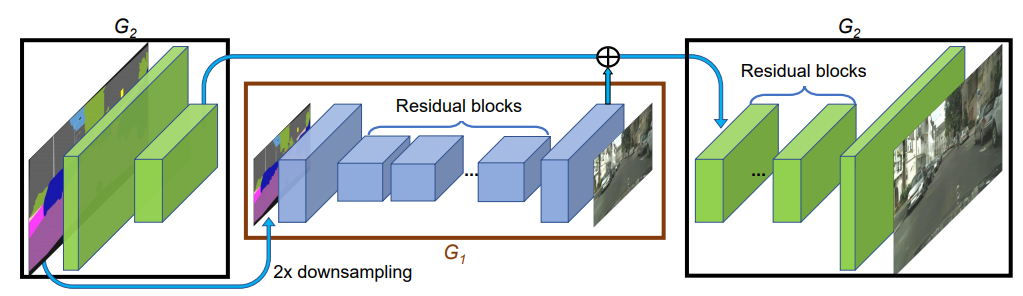
- Coarse-to-fine generator
모델이 high resolution에도 디테일한 영상을 추출할 수 있도록 보다 작을 resolution의 모델을 먼저 학습시키고 그 모델의 아웃풋을 바탕으로 high resolution 모델에 영향을 준다. 그림 2 와 같이 low resolution의 결과가 G2에 영향을 줘서 보다 퀄리티 있는 영상을 추출 할 수 있게 설계하였다.
3. Loss
3.1 Multi-scale discriminators
Scale에 보다 강인하도록 하기 위해서 Discriminator에 multi scale 을 적용하였다.
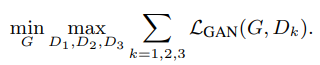
식은 기존 GAN의 Discriminator와 동일하며 단순히 모델에서 나오는 중간 conv 들을 discriminator로 판단해서 작은 물체와 큰 물체와 같이 스케일에 따른 디테일들이 살아 나도록 학습 했다.
4. Using Instance Maps
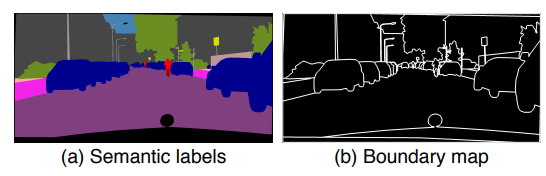
[그림 3] Instance map 활용
scale 이 커지면서 물체와 배경간의 구분이 명확하지 않아 물체의 디테일이 뭉게지는 문제가 발생한다고 한다. 이를 막기 위해서 그림 3 (b) 와 같이 boundary를 입력영상과 합쳐서 물체의 경계를 확실하게 알려주어서 성능을 향상 시켰다고 한다.
비록 이 pix2pixhd 의 본래 목적이 Semantic label로 부터 실제 영상을 만드는 거여서 Boundary map이 필요한 걸까 싶지만 그림 4와 같이 boundary map 이 포함 되서 학습이 됨으로써 성능이 향상 된 것을 볼 수 있다.

5. Result
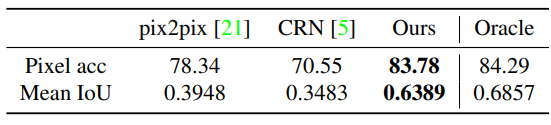
표 1을 각 I2I 방법론을 가지고 생성된 영상으로 Semantic segmatation 을 했을떄 의 성능을 보면 그냥 실제 영상과 비교했을때 거의 차이 없는 성능을 보이는 것을 볼 수 있다. 이로써 보다 물체들의 디테일을 살려 다른 테스크에 적용했을때 실제 영상과 거의 차이 없는 결과를 보이는 것을 알 수 있다.
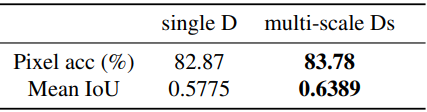
Multi scale Discriminator를 적용했을때 보다 좋은 결과를 나타 내는 것을 표 2를 통해서 알 수 있다.

그림 5를 통해서 제안된 방법론이 당시 I2I 의 SOTA 방법론 보다 더운 좋은 디테일로 영상을 생성하는것 을 볼 수 있다.
제안된 각 방법론에 대한 ablation study의 정량적 결과는 없을까요?