논문 리뷰전 간략소개 및 서베이
안녕하세요. 이번주차 x-review 주제는 DeepPose 입니다. Human Pose Estimation(HPS) 쪽에 대한 리뷰는 처음이네요. 최근 다양한 분야의 논문을 리뷰하고 있는데 아무래도 말이 통할 정도는 알고 있어야 된다고 생각해서 입니다.
해당 논문의 핵심 기여는 HPS 에 DNN을 이용하였다는 점에 있습니다. 그래서 논문 제목도 DeepPose로 DNN을 썼다는 점을 강조하고 있습니다. 2014년도에 나온 논문인 만큼 최근에 나온 방법론들에 비하면 성능이 떨어질테지만, 해당 분야 리뷰가 처음인 만큼 일단 베이스라인으로 잡았습니다.
그렇다면 과연 어떻게 DNN으로 HPS 을 하였을까요? 그전에 HPS 에 대해 좀 더 알아봅시다.
배경적 지식이 전무했던 상황에서 해당 논문을 읽은게 한 2주쯤 전이었습니다. 읽다보니 이해가 안가서 어떠한 task인지 감을 잡기위해 survey논문부터 시작했습니다. (survey논문은 디테일한 내용을 이해하기 힘들단 단점이 있으나 흐름을 파악하기엔 도움이 됐던거 같습니다.)
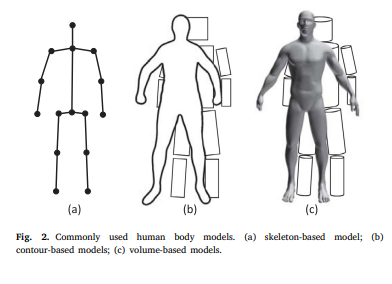
survey논문에 있던 사진중 일부입니다. 위의 그림은 HPS 이 어떤 task인지 직관적으로 보여줍니다. (a)은 skeleton 방식으로 각각의 joint(관절)들을 점으로 나타냅니다. (b)는 사람을 2D 평면에 투영하여 나타냅니다. 마지막으로 (c)는 3D로 나타냅니다. 이렇듯 같은 HPS 은 크게 3가지 분류로 나뉩니다. 그중에서 이번에 리뷰할 논문인 DeepPose는 Skeleton 방식에 해당됩니다.
위에서 3가지 종류의 HPS 을 소개 했습니다. 3가지로 구분되는 HPS 은 Regression-based와 detection-based로 세분화 됩니다. 그중에서도 DeepPose는 regression-based입니다.
DeepPose에서는 AlexNet기반의 DNN architecture를 사용합니다. 그 이유는 해당 논문이 발표된 시점인 2014년에 AlexNet(2012년도 발표)이 simple하면서도 좋은 성능을 내는 백본으로 알려졌기 때문입니다. 최근 방법론들에선 Backbone을 Hourglass를 사용하는게 많네요.
그렇다면 해당 논문이 DNN기반 regression-based 기법을 확론하기 전에는 어땠을까요?
정답은… 전통적인 방법으로 Part-based를 사용했습니다. 각각의 feature를 통해 body part를 찾고 조합하는 방식으로 human body modeling을 했습니다. 이러한 방식을 단순한 DNN 모델을 통한 regression 문제로 해결한게 DeepPose의 장점입니다.
최근 논문들에서등 background 정보를 활용한다거나, segmentation, sequence한 데이터의 정보를 활용하는등 occlusion에 대해 좀 더 robust한 방법들이 많은거 같네요. (좀 더 자세한 내용은 위에 달아둔 서베이 논문 링크를 확인해보세요. ) 하지만 이번 리뷰에서 다루게될 DeepPose는 나이브하게 DNN 만을 이용하여 각 joint들의 coordinates를 regression문제로 해결 하였습니다.
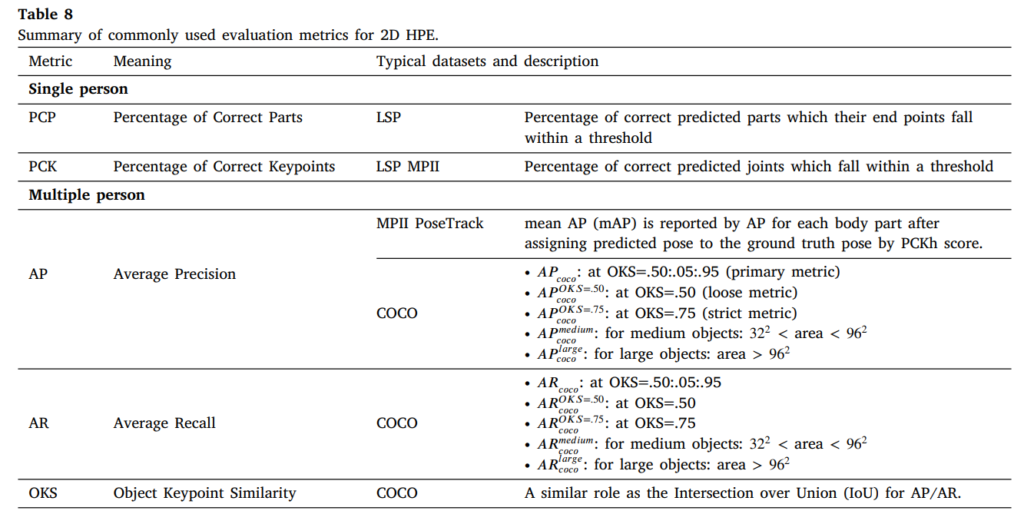
위 사진은 서베이 논문에서 가져온 2D HPS 관련 metric입니다. 참고하시면 좋을거같아서 가져왔습니다.
결과론적으로 HPS은 엄청난 발전을 이루어 왔습니다. Model 자체의 성능도 오르고, 방법론적인 면에서도 많은 진보를 했습니다. 그러나 여전히 occlusion이 너무 심하거나, crowded people, real-life application을 위한 computation time 등이 해결해야할 과제로 남습니다.
이정도 내용으로 HPS에 대한 전반적인 소개를 마친거 같습니다. (서베이논문 내용 간단요약) 그렇다면 이제 본격적으로 DeepPose 논문에 대해서 다루어 보겠습니다.
논문 내용
Deepose는 인용횟수가 1890회에 달하는 꽤나 영향력있는 논문입니다. 위에서 언급했듯이 DNN기반 모델을 이용하여 Human pose estimation(HPS)을 하였다는데 의미가 있습니다. 또한 당시에 SOTA를 달성했습니다.
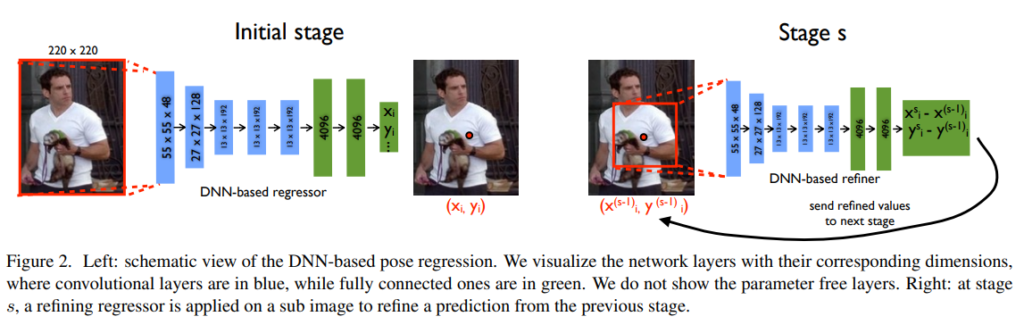
학습이 어떻게 진행되는지, LOSS는 어떻게 설계하였는지 등등을 이야기 하기전에 우선 파이프라인을 살펴봅시다.
위의 그림은 전체적인 파이프라인입니다. 크게 Initial stage와 Stage s로 나뉘어져 있는 것을 볼 수 있습니다. 우선 각각의 stage에 대해서 천천히 알아가봅시다.
Initial Stage
Initial stage에서는 각 k개의 관절에 대한 x, y 좌표를 구합니다. 이때의 x, y 좌표는 이미지 좌표계의 절대좌표입니다. 이와 같은 내용을 논문에서는 아래와같이 notation 했습니다.
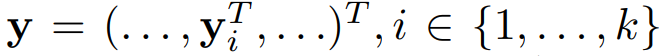
y는 결과값으로 x, y를 정보를 가지고있는 벡터입니다. 이때 y는 관절의 개수인 k 개 만큼 존재하며 k번째 관절은 y_k 로 notation 하겠습니다.
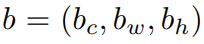
다음으로 바운딩박스에대한 notation을 얘기해봅시다. 왼쪽 부터 순서대로 centre, width, height를 의미합니다.
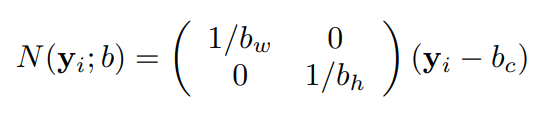
CNN모델에 태우기전 normalize를 해줍니다. 수식을 보면 관절의 좌표에서 바운딩박스의 센터값을 뺀 후 x좌표는 width로 나누고, y좌표는 height로 나눈것을 알 수 있습니다. 이로써 우리는 x, y좌표를 포함하고있는 y_i를 바운딩박스에 맞춰 normalize했습니다. 이러한 과정을 거치면 y_i값은 0~1 사이의 값이 나옵니다.
N함수는 관절의 정보를 담고있는 y_i값과 바운딩박스의 정보를 담고있는 b를 인풋으로 받아 normalize된 y_i값을 아웃풋으로 뱉는 함수라고 생각하시면 됩니다.
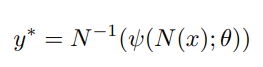
자꾸 식이 나오는데… 알고보면 어려운 식은 아닙니다.
위에서 바운딩박스를 이용하여 x, y를 normalize했습니다. 그리고 그 함수가 N이었습니다. 최종적으로 나온 결과값을 다시 de-normalize해주는 과정입니다. 이때 psi는 CNN모델 함수이고, 세타는 파라미터들 입니다. 이때의 결과값은 관절마다 2개의 좌표정보가 있기에 2k개가 될것입니다.
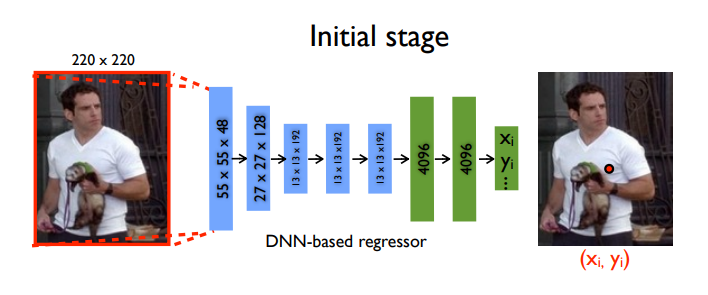
initial stage만 확대해보았습니다. 지금 여태까지 한 얘기들은 모두 initial stage에 관한 얘기였습니다. 이제 그림을 보며 앞에서 했던 내용을 다시 이해해봅시다.
해당 논문에서는 이미지 사이즈를 220*220으로 fix했습니다. 5개의 conv layer와 2개의 FC 레이어로 구성되어있고 최종적인 output은 2k개가 나옵니다. 현재 그림에서는 2048개의 관절에 대한 절대 이미지 좌표계에서의 x,y좌표 쌍들을 구한셈입니다. 여기까지가 initial stage입니다.
Stage s
위에서 Initial stage를 거쳐 나온 output은 k개의 관절좌표에대한 x, y 정보였습니다. 이제 이 정보들을 활용하여 s개의 stage를 더 거칩니다. 이러한 방식을 Cascade 방식이라고 합니다.
앞에서 initial stage를 Stage 1으로 notation하겠습니다. 그리고 s번째 stage는 stage s라고 표기하겠습니다.
Stage 1에서와 stage s에서는 같은 네트워크 구조를 사용합니다. 다만 새로운 바운딩박스를 그리는데 차이점이 있습니다.
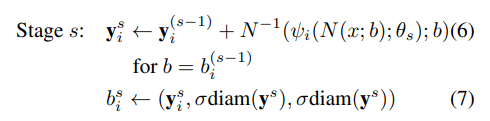
위의 수식은 stage s에 관한 수식입니다. Stage 1에서 이미 사용했던 수식이 반복해서 나옵니다. s에 2를 넣어서 생각해보면 이해가 더 잘됩니다. y2는 y1 + y1을 네트워크에 넣은 결과값을 de-normalize한 값입니다. 이 때 바운딩박스의 크기는 y의 diameter과 scale factor인 sigma에 의해 결정됩니다.
이러한 과정을 s번 반복하며 좀 더 좋은 결과를 얻어냅니다. Stage 1만을 이용하여 구한 결과는 전체 이미지에 대한 정보를 얻지만, stage가 늘어날 수록 좀 더 human에 focusing된 정보를 얻을 수 있기 때문입니다.
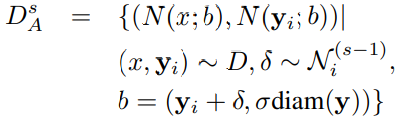
해당 부분은 CNN기반 방법은 large capacity를 가지기 때문에 multiple normalization을 적용하였다고 소개하는 부분입니다. S번째 stage에서 s-1번째의 결과값만을 사용하지 않고, simulated predictions를 만들었습니다. Normal distribution과 k개의 (y^(s-1)-y)를 이용하여 구한 mean and variance를 사용하였습니다. 정확한 원리는 여러번 읽어봐도 이해가 잘안되네요… 어찌됐든 포인트는 Normal distribution, mean, variance를 이용하여 Simulated predictions를 만들었고, 단순 한 prediction값 뿐만이아닌 simulated prediction값을 사용하였다는데 있습니다.
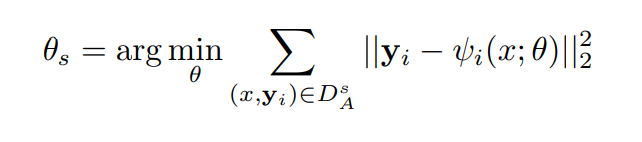
Loss로는 L2거리를 사용하였습니다. psi는 위에서도 말했듯이 네트워크 함수입니다. 네트워크에 인풋과 파라미터를 넣어서 얻은 아웃풋을 GT에서 빼준 후 제곱한 L2 거리를 사용합니다.
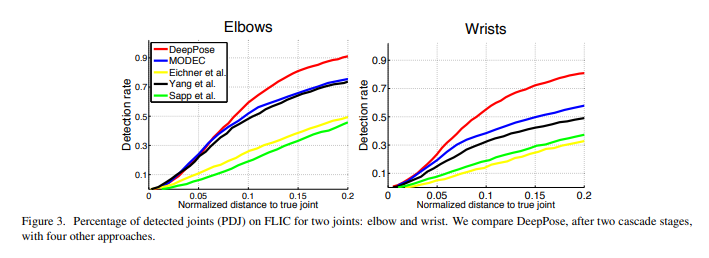
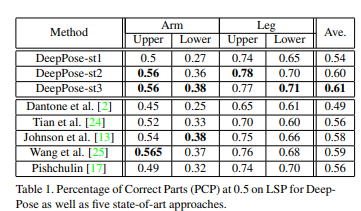
인공지능을 도입한 최초의 HPS로서, 기존의 방법론들 보다 좋은 성능을 내며 stage 2부터는 SOTA를 달성했습니다. 생각보다 margin이 크진 않네요.

정성적 평가입니다. Green이 GT이구요. stage가 증가함에따라서 좀 더 align이 잘 맞는걸 볼 수 있습니다.
이상 리뷰 마치겠습니다.
좋은 논문 발표 감사드립니다. 캡스톤에서 PoseNet을 사용한적 있어서 흥미롭게 봤습니다. 정해진 키포인트라고 하지만 결국 라벨링하는사람이 키포인트를 어떻게 설정하느냐에 따라서 굉장히 성능차이가 클것 같네요..
우선, 친절한 소개 감사합니다
Stage S에 대해서 initial stage의 결과를 수정하기 위함이면
initial stage의 경우 처음 x, y좌표는 어떻게 구하나요?
stage S의 수식 중 (6)과 initial stage 수식이 겹치지만, initial stage의 추가적인 수식이 없는 듯 하여 초기 x,y 좌표를 구하는 방식을 이해가 조금 어려운 것 같습니다.
추가적인 질문으로는 전통적인 방법인 part-based가 detection-based에 속하나요? detection-based와 Regression-based의 차이도 있다면 리뷰가 더 재미있을 것 같습니다
감사합니다