
1. FixMatch
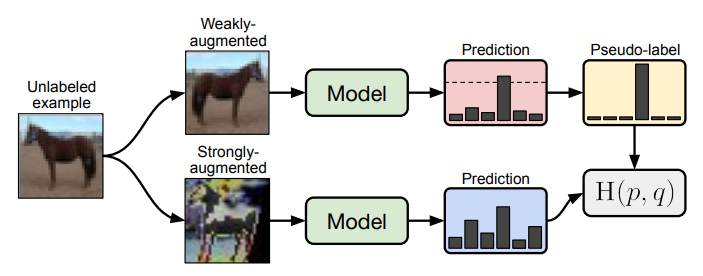
1.1 Background
최근 SSL 방법론 중 SOTA 모델에서는 Consistency regularization이라는 것이 중요하게 여겨지고 있습니다. Consistency regularization이란 이미지에 어떤 변환(augmentation)을 주어도 유사한 예측값을 출력해야한다는 가정하에 Unlabeled 이미지를 사용하는 것을 말합니다. 이를 달성하기 위한 Loss 는 식 (1)과 같습니다. 여기서 \mu B는 Unlabeled 데이터의 한 batch를 의미하며 p_m(y|\alpha(u_b)) 는 입력 \alpha(u_b)에 대한 예측값 확률분포, \alpha는 weak augmentation을 의미합니다. 식 (1)에서 \alpha 와 p_m은 각각 stochastic(=random)한 함수이기 때문에 서로 다른 것을 의미합니다.
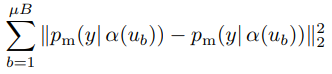
FixMatch에 사용되는 방법 중 나머지 하나인 Pseudo-labeling은 Unlabeled 데이터에서 모델이 스스로 인공적인 label을 만들고 사용하는 것을 말합니다. 좀 더 자세하게 말하자면 모델은 예측 내의 최대 확률이 사전 정해둔 임계값을 초과하는 경우에만 hard assign하여 사용하게 됩니다. 이처럼 일정 임계값을 초과하는 hard label만을 사용하는 것은 unlabeled 데이터들 중 entropy가 낮은 (confidence가 높은) 것만을 모델에 제공하기 때문에 결과적으로 모델의 entropy minimization에 기여하게 됩니다. 이러한 영향을 주는 Pseudo-labeling은 식 (2)와 같이 표현됩니다. \tau 는 hard assign을 결정하는 임계값, \hat{q_b}=argmax(q_b)를 의미합니다.
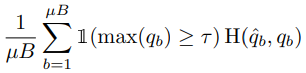
1.2 Algorithm
FixMatch의 Loss 함수는 두 가지로 구성됩니다. 하나는 Supervised loss l_s 이고 다른 하나는 Unsupervised loss l_u 입니다. l_s는 단순히 weak augmentation이 적용된 cross-entropy loss 이며 식 (3) 과 같습니다.
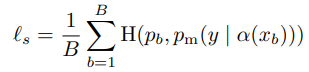
l_u 는 Pseudo-labeling이 적용되어 식 (4)와 같이 나타납니다. Pseudo-labeling을 적용하기 위해 unlabeled 이미지에 weak augmentation을 적용을 하게 되고 예측 값의 최대 확률 분포 값이 \tau 를 넘길 때 학습에 사용하게 됩니다. 이렇게 얻은 Pseudo-label과 unlabeled 이미지에 strong augmentation을 한 뒤 얻은 모델의 예측 값을 cross-entropy loss로 최소화시킵니다.
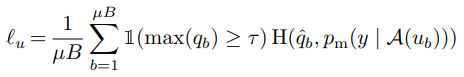
이 두 Loss 함수를 일정 weight를 주어 합쳐서 최종 Loss l_s+\lambda _u l_u로 사용합니다. 그리고 특이한 점을 해당 Loss를 구하는 알고리즘에 있습니다. FixMatch 방식은 우선 한 batch에서 적은 양의 label이 있는 데이터로 학습하여 l_s를 구하고 Unlabeled 데이터에 대해 Pseudo-labeling을 한 후 l_u 를 구해 weight sum 하게 됩니다. 이에 대한 pseudo code는 Fig 3에서 확인할 수 있습니다.

1.3 Augmentation in FixMatch
FixMatch에서는 weak와 strong, 두 가지의 augmentation을 사용한다고 앞서 설명하였습니다. Weak augmentation은 flip과 shift로 구성되어 있으며 flip은 랜덤하게 50% 확률로 작동하며 shift는 12.5%까지 수직과 수평으로 이동시키게 됩니다. Strong augmentation의 경우 AutoAugment의 두 가지 변형 방법이 포함되어있습니다. AutoAugment이란 label이 있는 데이터에 대해 Reinforce learning 방식으로 학습하는 방법론이며, 이를 Unlabeled 데이터에 사용하는 것은 부적절하게 됩니다. 그러므로 이의 변형으로 이미지에 왜곡을 주는 방식의 일종인 RandAugment와 CTAugment를 strong augmentation으로 사용하였습니다.