
영상변환 분야는 다른 두 도메인의 사진을 서로 변환하는 것을 목표로 연구가 진행 되고 있다. 하지만 다른 두 도메인을 가지고 딥러닝 모델을 학습하는데에는 큰 두가지 문제가 있다. 첫번째는 두 도메인에 페어가 맞는 데이터 셋이 부족하다. 즉 고양이를 강아지로 변환 시키는 모델을 만들고 싶은데 고양이 1 를 변환 시켰을때 나와야하는 강이지 1 페어가 존재하지 않는 다는 문제점이다. 딥러닝은 일반적으로 페어가 맞는 데이터셋을 기반으로 학습을 진행해왔기 떄문에 이 문제는 연구를 함에 있어서 매우 큰 문제로 대두 되었다. 두번째 문제는 첫번째와 유사한 문제점인데, 페어가 맞는 데이터가 없다보니 어떤 변환이 올바른 변환인지 모를 정도로 다양한 결과 가 나온다는 것이다. 그림 1 에 Cat->Dog 를 예로 들면 고양이1을 강아지로 변환하고 싶을 때 고양이 1로 부터 변환된 강아지가 말라뷰트일지 허스키일지 진돗개일디 알 수 없이 변환될 가능성이 다양하다는 것이다 .
영상변환 분야의 두가지 문제점을 해결하기 위해서 본 논문에서는 unpaired data 없이 disentangled 한 다양한 영상을 생성하기 위한 방식을 제시한다.
.
- Pipeline
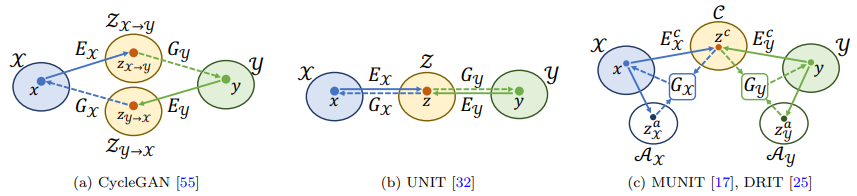
본 논문은 두 가지 영상 공간을 영상변환 시 사용하는 것을 제안한다. 그림 2 (c)에서 제안된 두가지 영상 공간을 볼 수 있다. 이를 설명하자면, 제안한 두공간 중 첫번쨰는 Domain Invariant한 공간이다. 이는 두 두메인이 공유하는 공간으로 두 두메인의 공통적인 특징을 encode해 저장한다. 그리고 두번째 공간은 Domain – specific 한 정보를 encode한다.
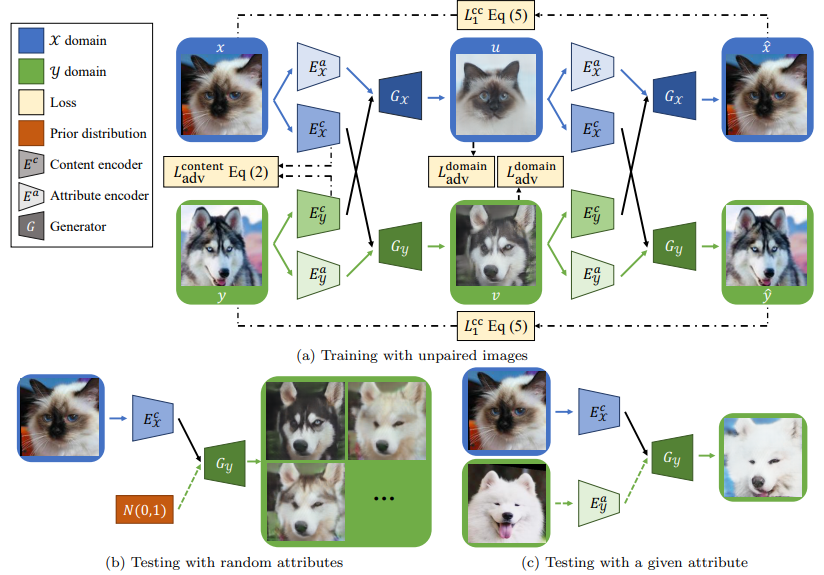
보다 쉬운 이해를 위해 그림 3의 Train 부분을 보면서 설명을 하자면, 고양이를 두 encoder의 입력으로 해 두가지(Domain Invariant, Domain Specific) feature를 생성한다. 그리고 unpaired 한 강이지 사진도 동일하게 진행한다. 그 후 고양이의 Domain Invariant feature와 강아지의 Domain Specific feature를 합치고 Generate하면 고양이 영상이 생성된다. 이를 강아지도 동일하게 한다. 이것을 통해서 Domain Invariant feature는 영상의 전체적인 형태나 모습 담고 있고 Domain Specific feature는 도메인의 특징을 담고 있는 것을 알 수 있다. 학습 시에는 설명한 것과 같이 pipeline이 동작하고, test inference시 에는 그림 3(b)와 (c) 같이 진행할 수 있다.
2. Loss
1 에서 설명한 pipeline을 학습하기 위한 loss들은 다음과 같다. 그림 3 에 표시된 용어들을 그대로 사용하며 설명을 할 것 이다.
2.1 Disentangle Content and Attribute Representations
Domain Invarint feature를 생성하는 Ec 는 도메인에 따라서 Ecx 와 Ecy 두개가 사용된다. Ecx와 Ecy는 맨 마지막 layer를 공유하여 두 네트뭐크의 아웃풋이 유사하도록 한다. 하지만 네트워크를 공유하는 것 만으로는 원하는만큼 두 네트워크의 output 이 유사해지지 않으므로 Discriminator를 이용해서 두 네트워크의 output이 유사해지도록 학습을 한다. 즉 Ecx와 Ecy 두 네트워크의 아웃풋 중에 어떤 것이 X를 입력으로 했고 어떤 것을 Y를 입력으로 했는지 맞추는 Discriminator를 사용해서 output을 유사하도록 loss를 구성한다. loss 식은 아래 식 1 과 같다.
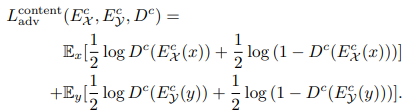
2.2 Cross-cycle Consistency Loss
CycleGAN과 같이 Network의 Recontruct성능을 올리기 위해 A->B로 변환된 B를 다시 A로 되돌려 실제 A랑 비교하는 Loss를 사용한다. 식은 아래 식 2 와 같다.
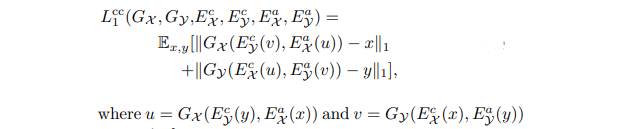
2.3 Other Loss Functions
2.3.1. Domain adversarial loss
생성된 두 영상이 생성된 영상인지 아니면 실제 영상인지 판단하기 위한 Discriminator loss 또한 사용했다.
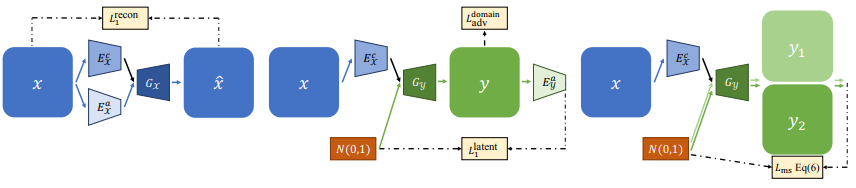
2.3.2 Self reconstruction loss
X로 부터 생성되는 Ec와 Ea는 합치면 당연히 X로 Recontruction이 제대로 되야 이 pipeline이 잘 동작하는 것이니 이 것을 위한 loss도 추가적으로 사용했다. 그림 4의 맨 왼쪽 과 같이 x로 부터 생성된 x*을 x와 L1 로 비교해서 loss를 구하는 것이다.
2.3.3 Latent regression loss
영상을 생성할때 입력으로 넣은 Specific feature와 생성된 영상으로 부터 얻는 Specific feature가 동일할 수 있도록 두개를 L1 으로 비교한다. 요기서 입력으로 넣는 Specific feature는 Gaussian 정규분포를 사용했다. 그림 4의 가운데를 통해 어떠한 것들이 Loss로 계산 되는 지 알 수 있다.
3. Results

그림 5를 보면 DRIT++이 처음에 말했던 문제인 다양한 Output을 잘 생성하고 있는 것을 확인할 수 있다.

다른 방법론들과 비교를 했을때 DRIT++이 보다 다양한 output을 보이는 것을 알 수 있다.
이 외에도 정량적 평과와 다른 정성적 평가가 있으나 그것은 세미나에서 설명하도록 하겠다.
Disentangle 과 Entangle 의 차이를 설명해주실 수 있을까요?