이번 리뷰는 Cycle GAN입니다. Cycle GAN은 나온지도 꽤 된 논문이며, GAN과 관련된 논문들에서 정말 많이 사용되는 방법론이기 때문에 정리된 글들도 많지만 단순히 글만 읽는 것이 아닌 직접 리뷰를 작성하면 더 많은 지식을 얻을 수 있기에 이번에 리뷰로 작성하게 되었습니다.
pix2pix
CycleGAN에 들어가기 앞서, pix2pix에 대해서 가볍게 정리하고 넘어가겠습니다. 먼저 pix2pix는 아래 그림과 같이 GAN을 이용하여 영상을 다른 영상으로(예를 들어 흑백 영상을 컬러 영상으로, 또는 segmentation 영상을 실제 영상으로) 바꾸는 방법론입니다.
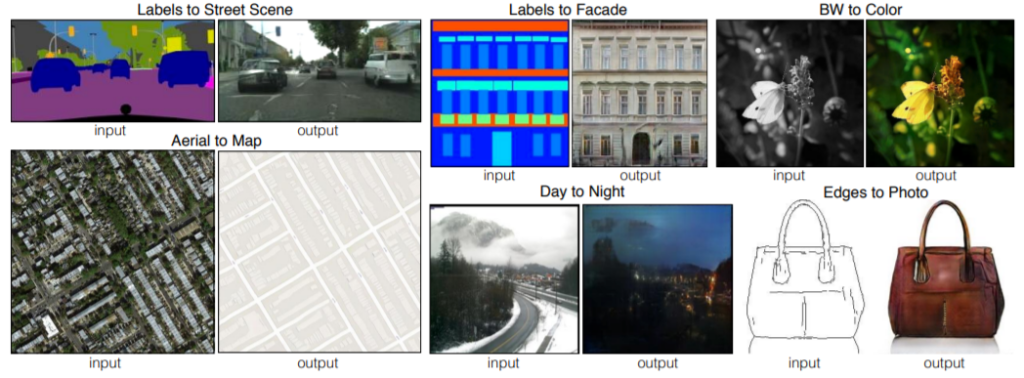
여기서 가장 중요한 점은 GAN을 이용했다는 것입니다. 일단 GAN을 빼고 생각해봅시다. 가장 나이브한 방법은 입력영상과 우리가 바꾸고자 하는 출력영상의 pixel들끼리의 차이를 최소화하는 것이겠죠?

하지만 이러한 L1 loss만을 사용하는 것은 바람직한 방법이 아닙니다. 그림2를 살펴보시다시피, L1 loss만을 이용한 결과값은 무언가 그럴듯하게 만들어진 듯 싶지만, 영상이 블러하기에 사람이 봤을 때 이 영상은 가짜 영상이구나 라는 것을 확실하게 알 수 있죠.
그 이유는 실제 정답 영상은 하나의 단일 정답이 있는 것이 아니라 정말 다양한 색상과 texture를 가질 수 있지만, L1 loss는 단순히 평균값만을 제공하기 때문에 영상이 블러해지는 현상들이 일어나게 됩니다.
여기서 GAN을 사용하게 되는 이유가 나타나게 됩니다. Network가 만들어낸 가짜 영상이 사람 눈으로 볼 때 뚜렷하게 구분이 가능하다면, 모델도 가짜 영상을 뚜렷하게 구분할 수 있지 않을까? 라는 생각을 할 수 있겠죠.
그래서 pix2pix는 GAN을 사용하게 됩니다. 하지만 이러한 GAN loss도 역시 아쉬운 점이 존재합니다. GAN을 통해서 만든 fake image는 충분히 사실적이고 실제 영상같이 만들어내지만, Generator와 Discriminator가 서로 경쟁하며 학습하기 때문에 실제 GT같은 영상을 만드는 것보다는 Discriminator를 속이기 위한 영상을 만들려고 할 수도 있습니다.
그렇기 때문에 실제 GT와 유사한 영상을 만들 수 있게끔 하기 위해 pix2pix는 GAN loss에 이전 L1 loss를 합쳐서 사용하였으며, 이를 통해 훨씬 샤프하고 GT와 유사한 출력 영상이 만들어지게 됩니다.
CycleGAN
그럼 이제 CycleGAN에 대해서 알아봅시다. 일단 pix2pix에 경우 GAN을 이용하여 Colorization, lable2real 등 정말 매력적인 결과들을 도출해냈습니다. 하지만 우리가 하고 싶은 작업이 반 고흐, 모네와 같은 유명화가의 그림을 실제 그림처럼 만들고 싶다면 어떻게 해야할까요?
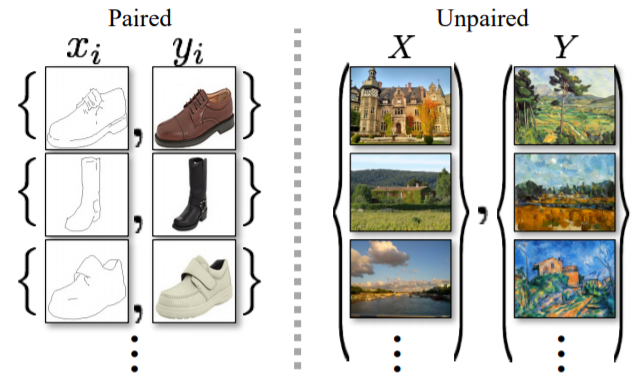
pix2pix의 경우 모델을 학습하기 위해서는 그림3의 왼쪽과 같이 반드시 input과 그에 대응되는 output이 존재해야만 합니다. 모네의 그림은 구글에 검색하면 구할 수 있지만, 모네가 그림을 그렸던 그 곳의 환경을 촬영한 사진은 우리가 구할 수 없죠.
이러한 input과 그에 대응되는 output data가 없는 상황을 해결하고자 CycleGAN이 탄생하게 됩니다. CycleGAN은 input과 output이 서로 다른, 즉 unpaired dataset을 가지고 학습할 수 있습니다.
그렇다면 CycleGAN의 loss는 어떻게 이루어질까요? 먼저 이전에 알아보았던 pix2pix는 L1 loss와 GAN loss를 사용한다고 했습니다.
CycleGAN 역시 GAN loss는 그대로 사용할 수는 있습니다. 하지만 GAN loss만을 사용하게 되면 Generator는 입력 그림이 어떤 그림인지는 신경도 쓰지 않은 채, GT로 사용된 사진처럼 만들려고만 하고 Discriminator는 그림인게 사진처럼 만들어졌으니 OK 하고 넘어갈 것입니다. 즉 해당 그림과 동일한 구조를 가지는 사진을 만들려고는 하지 않는 것이죠.
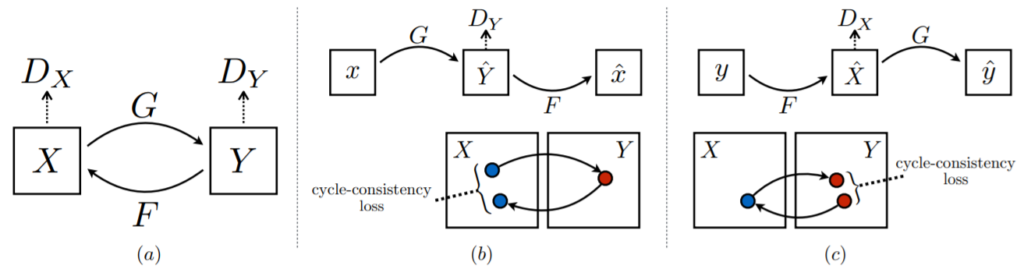
그래서 CycleGAN은 이러한 문제를 보완하고자, “Generator로 만든 fake image(Y ~= G(x))를 다시 입력 영상(X ~= F(G(X)))으로 만들 수 있어야만 한다.” 라는 제약 조건을 만들었습니다.
그림4 (a)처럼 G를 통해 만든 Y를 다시 F를 통해 X로 되돌려 놓을 수 있어야 한다는 것입니다. 이를 통해 위에서 언급한, Generator가 입력 영상을 고려하지 않은 채, GT처럼 만들려고만 하는 문제를 해결한 것이죠.
그리고 자세히 살펴보면, 그림4.(b)와 같이 G generator는 X를 Y로 바꾸는 것을 학습하고 이 만든 G(X)를 다시 F generator를 통해 X로 만드는 것을 학습하는 것과 그림4.(C)처럼 F generator로 Y를 X로 바꾸고, 이 F(Y)를 G를 통해 X로 바꾸게끔 학습하는 것이 결과적으로는 동일한 방법입니다.
즉 두 방법은 순서의 차이이지 결국 같은 과정으로 학습을 하는 것이기 때문에 CycleGAN에서는 이 두 방식의 학습과정에서 생기는 loss term을 모두 사용합니다.
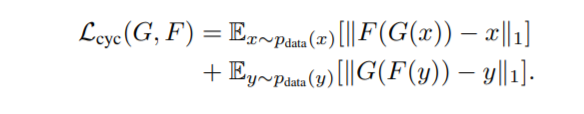
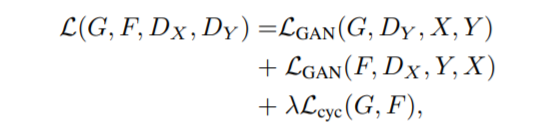
위에 수식을 보시면, L_{cyc}가 바로 G와 F가 각각 만든 fake image를 다시 F와 G를 적용시켜 input 영상으로 되돌렸을 때 차이가 크게 나서는 안된다는 loss term을 의미하며, L_{GAN}은 우리가 흔히 아는 GAN loss를 의미합니다.

그림5는 위에서 설명한 loss들이 각각 어떠한 역할을 하고 있는지를 보여주는 그림입니다. 먼저 GAN loss만을 사용하게 될 경우, 얼핏 보았을 때는 입력 영상을 출력 영상의 도메인으로 잘 바꿔주는 것처럼 보입니다.
하지만 1열의 3행(GAN alone)과 3열의 3행을 비교해 보았을 때, 입력 영상은 서로 다른 장면이지만, 동일한 출력 영상을 만들게 되는 현상이 발생합니다.
즉 GAN loss만 사용하게 되면 input 영상이 어떻게 구성되었는지 간에 그냥 GT 영상처럼만 만드려는 문제를 명확히 보이는 셈이죠.
하지만 CycleGAN의 모든 loss term을 사용하게 될 경우, 최대한 input 영상의 구조를 고려하면서 GT 도메인과 유사하게 영상을 만들게 됩니다.

그림6은 input 영상에 따른 output 영상과 그 output 영상을 다시 input 영상으로 reconstruct한 것입니다. 변환된 영상을 다시 input 영상스럽게 잘 만드는 것을 확인할 수 있으며, 이 컨셉이 unpaired dataset에서도 Image translation이 가능하다는 것을 잘 보여주고 있습니다.

그림7은 identity loss의 효과를 보여주는 결과입니다. identity loss란 무엇이냐면, input 영상과 output 영상에 단순히 L1 loss를 적용한 것입니다.
리뷰 초반에 pix2pix에서 GAN loss에 L1 loss를 같이 사용한 이유에 대해 설명했다시피, CycleGAN에서의 GAN loss가 만들어내는 결과값이 GT Image와 멀어질 수 있으므로 이를 보완해주고자 predict과 GT가 너무 달라지지 않게끔 L1 loss를 추가하는 것이죠.
이러한 identity loss를 적용하지 않았을 경우 그림7 3행 1열과 3행 2열처럼 input은 노을진 그림이지만 출력은 이미 해가 진 밤 시간대 사진이 나오게 됩니다.
반면 identity loss 적용 시에 input과 동일한 시간대의 결과로 출력될 수 있었던 것이구요.
CycleGAN은 너무나 유명한 논문이기에 정량적 결과와 이를 비교하는 내용들은 따로 추가하지는 않았습니다. 이상 리뷰 끝.
판별자를 속이는쪽으로 학습하는게 아닌 GT랑 비슷한 쪽으로 학습시키기위해 L1 loss를 추가한게 핵심이군요! 좋은리뷰 감사합니다.
이 CycleGAN을 처음에 읽었을떄 가장 이해가 안가기도 하고 읽은지 오래돼서 기억이 잘 안나는 부분이 그Unpaired 한 상황에도 Generator Adversarial loss를 적요할 수 있었던 부분인데요. GT가 없는 상황에서 어떻게 생성된 영상을 비교할 수 있었는지에 대해서 설명 부탁드립니다. 사실 Cycle Loss 부분은 직관적으로 이해가 쉬웠지만 질문드린 부분이 잘 이해가 안됐었고 이해를 하고 생각해보니 이게 있어야 Unpaired 한 상황을 해결 하는 것이라 굉장히 중요한 부분이라 생각하는데 뭔가 빠진 것 같아서 질문 남깁니다.
안녕하세요 정민님 좋은 리뷰 감사합니다.
CycleGAN이 Unpaired Dataset의 상황에서도 학습할 수 있고 그 과정은 주어진 입력 이미지를 원하는 출력 도메인으로 변환한 후, 해당 출력 이미지를 다시 원래 입력 도메인으로 되돌리는 과정을 통해 학습하는 것으로 이해를 하였습니다. 하지만 아직 Gan에 대한 이해가 부족하여 몇 가지 의문이 생겼는데 먼저 Gan Loss에는 생성자 손실(Generator Loss) , 판별자 손실 (Discriminator Loss)이 있고 생성자는 판별자를 속이는 것을 목표로 하고 판별자의 목적은 실제와 가짜를 올바르게 구별하는 것으로 알고 있습니다. 근데 생성자가 판별자를 더 많이 속이도록 노력하고, 판별자가 더 효과적으로 진짜와 가짜를 구별하도록 학습한다고 하면 손실을 줄이기가 쉽지 않을 것 같은데 실제로 이런 문제가 발생하나요?