1. 해당 논문을 다루게된 배경
이번주에 Multi-view Geometry를 공부하며 카메라와 월드좌표계 사이의 관계에 대해서 학습했습니다. 그러다보니 자연스럽게 Depth Estimation 까지 공부가 확장되었습니다. Stereo camera의 경우 Multi-view Geometry를 이해하면 어렵지 않게 이해가 되었지만, mono인 경우에는 depth를 어떻게 추정할까에 대한 호기심이 생겼습니다.
해당 논문의 제목은 Unsupervised Monocular Depth Estimation with Left-Right Consistency 으로 Monocular Depth Estimation을 쳤을때 인용수가 1300정도로 제일 먼저 노출이 되었습니다. 그래서 정한 논문입니다. 후속 연구들도 꽤나 많은거 같더라구요. 본격적인 논문 리뷰에 앞서 Multi-view Geometry에 대한 언급을 조금 하고 시작할까 합니다.
2. Multi-view Geometry
컴퓨터 비전을 전공하는 사람들에게 있어서 카메라 좌표계의 대한 이해는 필수적입니다. 그러나 선형대수, 외적, 내적 등 수학적인 개념이 많이 나와 학습하기 좀 난해한 주제입니다. 그래도 최근에는 잘 정리되어있는 자료가 많아서 학습을 하기에 좀 더 수월했습니다. 또한 연구실 인원들중 일부가 이미 사전에 학습했던 개념이라 좀 더 삽질?하는 과정을 줄이고 빠르게 학습을 할 수 있었다고 생각합니다.
아래 정리한 링크들은 향후에 Multi-view Geometry를 공부하게될 후배 연구원들이나 이미 학습했지만 내용을 까먹은 분들을 위한 future reference입니다. 저 또한 나중에 리마인드하는 느낌으로 살펴볼 생각입니다. 만약 훗날 들어올 후배연구원님들이 이글을 읽고 있다면 이 글에서 언급하는 순서대로 훑어 보시길 권장드립니다. 처음엔 이해가 안가더라도 가벼운 마음으로 여러번 반복해서 읽다보면 퍼즐들이 맞춰지며 이해가 가는 순간이 올겁니다!
2-1 다크프로그래머 블로그
컴퓨터비전을 전공하시는 분들은 다들 한번쯤은 들어봤을 블로그입니다. 국문으로 정리된 자료중에서 가장 퀄리티가 좋다고 생각하여 읽어보았습니다. 아래 순서는 제가 학습한 순서이자 추천드리는 순서입니다.
- 카메라 캘리브레이션
- 카메라 왜곡 보정
- [영상 Geometry #1] 좌표계
- [영상 Geometry #2] Homogeneous Coordinates
- [영상 Geometry #3] 2D 변환 (Transformations)
- [영상 Geometry #4] Homography 보완
- [영상 Geometry #5] 3D 변환
- [영상 Geometry #6] 이미지 투영(Imaging Geometry)
- [영상 Geometry #7] Epipolar Geometry
- 3D 좌표계 변환 방법 (예: 월드좌표계 – 카메라 좌표계)
2-2 한동대학교 비전강의
- MVG #1 Homogeneous Coordinate 2D Transform
- MVG #2 Image Features
- MVG #3 Homography Estimation Synthetic View
- MVG #4 Camera Model Calibration
- MVG #5 Epipolar Geometry
- MVG #6 3D Reconstruction
2-3 RCV 연구실 X-review (신정민 연구원)
- Multiple View Geometry-Projective Geometry and Transformations of 2D
- Multiview Geometry(Homogeneous~Homography)
- Multiview Geometry(Pseudo Inverse ~ RANSAC)
- Multi View Geometry study_2
- 연구실 세미나 영상 (내부 세미나 이므로 링크는 비공개)
2-4 기타
- 서재규 교수님 영상이해 수업
- Multi-view Geometry 책
Multi-view Geometry 책은 해당 분야에서의 바이블 같은 존재입니다. 엄청나게 자세히 친절하게 설명되어있지만, 원서이고, 내용이 너무많아서 진입장벽이 큽니다. 2-1~2-3에서 어느정도 배경지식을 쌓고 좀 더 디테일하게 이해하고 싶으신 분들은 해당 원서를 참고하시면 좋을거같습니다.
서재규 교수님 수업은 해당 책에서 핵심부분만을 쉽게 가르칩니다. 해당 분야를 공부하고 싶으신 분들은 수강하시는 것을 추천드립니다.
마지막으로 참고하시면 좋을만한 사진자료들을 첨부합니다.
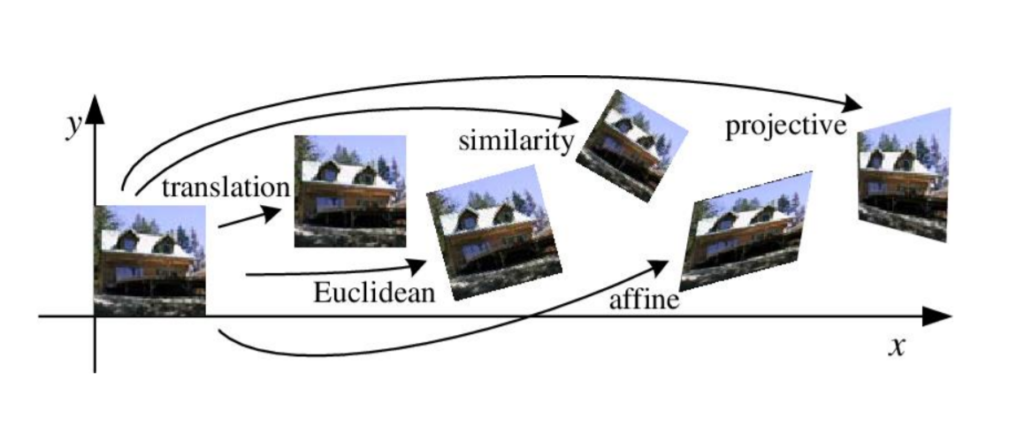
해당 사진은 각 변환들이 어떠한 의미를 가지고 있는지 직관적으로 잘 보여주는 예시라고 생각합니다.
3. Unsupervised Monocular Depth Estimation with Left-Right Consistency 논문
3-1 논문 배경지식
해당 논문을 시작점으로 잡았지만, depth estimation을 처음 공부해보는지라 조금 어려웠습니다. 그래서 monodepth에 대한 자료들을 찾아보고 모르는 용어들을 익히며 어느정도의 배경지식을 쌓은 상태에서 해당 논문을 읽었습니다.
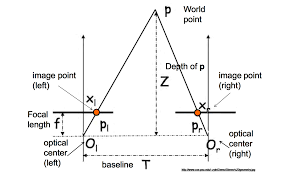
mono depth를 다루기 전에 stereo인 경우를 생각해봅시다. 위의 그림에서 삼각형 P, P_l, P_r과 삼각형 P, O_l, O_r은 AA 닮음 입니다. 이때 우리는 baseline, focal length, disparity, 를 구하면 비례식을 세워 depth정보를 알 수 있습니다. 이 내용은 위에서 언급한 Multi-view Geometry를 이해하면 어렵지 않게 이해할 수 있습니다.
그런데???? Mono 카메라일 경우에는 어떤식으로 depth를 추정할까요?

일단 원리를 파악하기전에 depth map을 구한 결과물을 먼저 가지고 왔습니다. 위의 영상을 보시면 거리가 먼 물체는 어두운색으로 가까이 있는 물체는 밝은색으로 표현이 되었습니다.
여기서 문제가 stereo 카메라는 left image와 right image를 통해서 disparity를 구할 수 있었지만, mono에서는 어떤식으로 구하느냐입니다.
Mono 카메라를 이용한 depth estimation에서는 한개의 이미지를 네트워크에 넣어 2개의 disparity를 뽑아냅니다. 이때 reconstruction loss를 사용하여 뽑아낸 disparity가 GT에 가까운 값으로 학습을 합니다.
해당 논문에서는 GT데이터를 쓰지않고 unsupervised로 monodepth를 뽑아내는 방법을 제안합니다.
3-2 논문 소개
이론적인 내용을 다루기에 앞서 전체적인 흐름을 먼저 소개할까 합니다. 흐름을 알아야 이론적인 내용을 다룰때도 이해하는데 도움이 될거라고 생각하기 때문입니다.
Vision 기반의 depth estimation, 즉 거리정보를 예측하기 위해서는 2개 이상의 이미지가 필요합니다. 다양한 방법이 있지만, 대표적으로 스테레오 카메라를 이용, 각각의 다른 viewpoint에서 본 여러장의 사진을 이용하는 방법등이 있습니다.
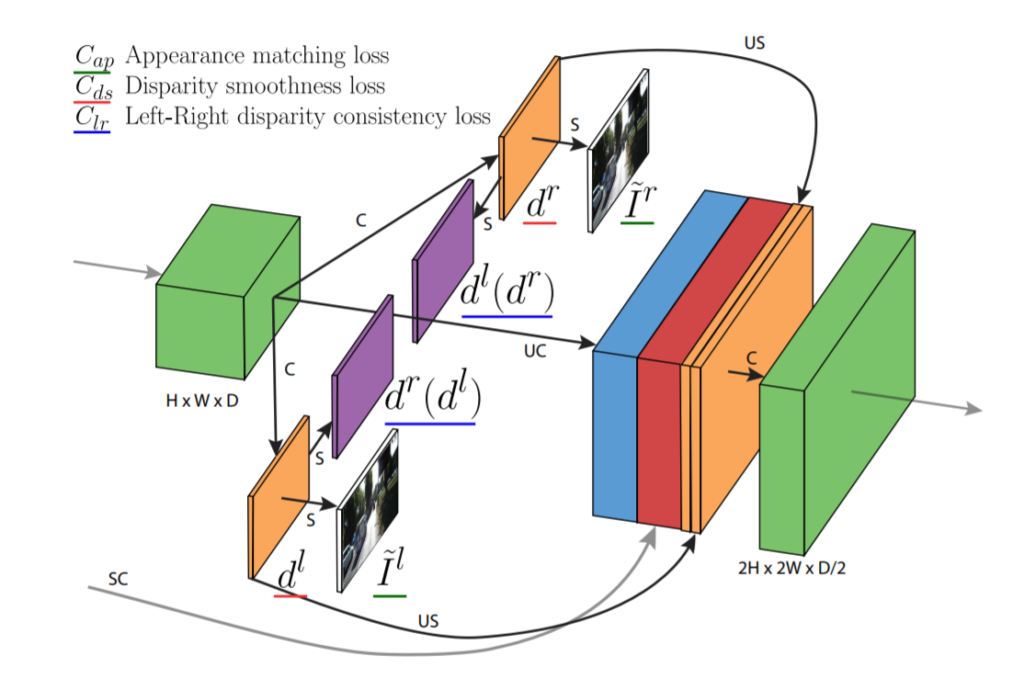
위의 그림은 논문에서 제안하는 네트워크의 구조입니다. 한개의 이미지(left)가 들어가서 CNN을 통과한 후 left disparity, right disparity를 얻습니다. 이후 얻은 right disparity와 left image를 이용하여 right image를 얻습니다. 얻은 right image와 left disparity를 이용하여 left image를 얻습니다.
이 과정을 거치면 실제 left 이미지와 만들어진 left, right 이미지, 2개의 disparity가 있을것 입니다. 이들과의 관계를 이용하여 학습을 진행합니다. 학습하는 과정에 대해서는 아래에서 좀 더 자세히 다루겠습니다.
LOSS
학습하는 과정에서 loss는 총 3개Appearance matching loss(AP loss), Disparity smoothness loss(DS loss), Left-right disparity consistency loss(LR loss)를 사용했습니다. 밑에서는 abbreviated된 notation으로 언급하겠습니다.
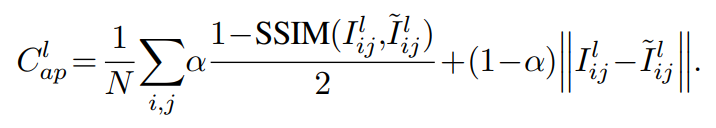
먼저, AP loss입니다. 학습과정에서 네트워크는 이미지로부터 다른 이미지를 만들어내는 방법을 학습합니다. 그때 만들어진 이미지들에 대한 loos 항 이라고 생각하시면 됩니다. 이때 SSIM은 이미지의 품질을 측정하는 방법으로 해당링크에 자세히 설명되어 있습니다.
실제 left image와 이를 모델에 통과시켜 얻은 2개의 disparity를 이용하면 left & right image를 얻을 수 있습니다. 이를 비교하기 위해 SSIM을 사용한 것 입니다. 즉, 기존이미지와 reconstructed된 이미지 와의 차이를 줄여나가는 방향으로 학습을 시키기 위해 추가한 loss입니다.
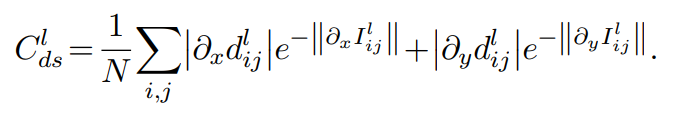
위의 식은 DS loss입니다. Loss항의 이름대로 Disparity를 smooth하게 만들어주는 loss입니다. x와 y에 대하여 편미분 하면 각 disparity의 gradient를 구할 수 있습니다. 해당 논문에서는 L1 정규화를 적용한 disparity의 gradient를 smooth하게 하기위해 DS loss항을 사용합니다. 여기서 exponential 항이 들어간 이유는 이미지에서의 edge를 고려하기 위함입니다. Edge에서의 depth의 gradient는 급격히 변할 것 입니다. 그렇기 때문에 이미지를 x와 y에 대하여 편미분한 exp항을 분모로 넣어서 edge영역에서 disparity의 gradient에 weight를 주는 것 입니다.
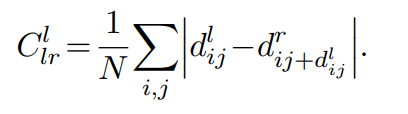
위의 그림은 LR loss 수식입니다. 좀 이해가 안가서 코드를 살펴보았습니다.

먼저 left, right에 대한 consistency를 구하고 합쳐주는 방식으로 코드가 짜여져 있었습니다. Consistency를 구하는 과정에서는 left or right disparity에 반대되는 estimated disparity를 빼주는 방식을 사용한거 같습니다.

각각의 loss는 weight들이 곱해진 후 합쳐집니다. loss의 scale을 맞추기 위한 작업인데 image_loss 에는 weight가 안곱해진 것을 보실 수 있습니다. 이는 아마 굳이 weight를 3개를 둘 필요 없이 뒤에 있는 2개의 weight들을 바꾸어주면 상대적인 imbalance를 해소할 수 있기 때문일 것입니다.
Post-processing
Disparity의 ramp를 만드는 stereo dis-occlusion을 줄이기위해 저자는 post-processing을 추가합니다. 테스트를 할때, 인풋 이미지를 I라고 해봅시다. 수평으로 flip된 이미지를 I`이라고하면 각 disparity map인 d와 d’을 구할 수 있습니다. Flip된 이미지로부터 얻은 disparity인 d’을 다시 flip 시키고 이를 d”라고 하겠습니다. 그럼 d”은 d와 allign이 맞아야 할 것 입니다. 이때, d” 에서의 disparity ramp는 occuluder의 오른쪽과 이미지의 오른쪽에 있습니다. d에서는 이와 반대입니다. Post-processing에선느 disparity ramp가 있는 영역을 최소화 시키고자 d와 d”의 disparity map을 combine하는 전략을 사용합니다.
그렇다면 이제 d, d” 각각의 disparity map을 combine한 방법을 설명 드리겠습니다. 합칠때 처음 5%는 d”의 왼쪽 영역을 할당하고, 마지막 5%는 d로부터 나온 disparity의 오른쪽 영역을 할당합니다. 이렇게 disparity를 처리하고 나면, accuracy가 향상되고 시각적인 요소에 영향을 덜 받습니다. 해당 post-processing에 대한 영향은 평가부분에서 pp(Post-processing) 로 표현하였습니다.
3-3 평가
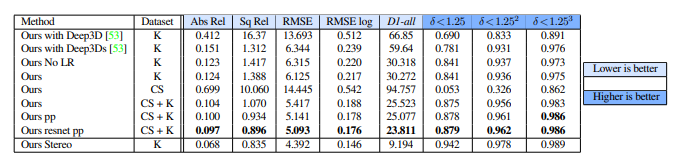
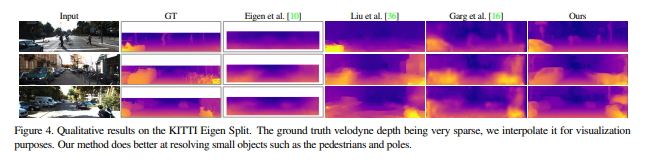

KITTI데이터셋에서 Mono 카메라 만으로도 좋은 결과가 나왔고, 이는 stereo 카메라에도 견줄만 합니다. 힘들게 GT데이터를 만들지 않고도 depth estimation을 할 수 있다는데 의의를 갖습니다.
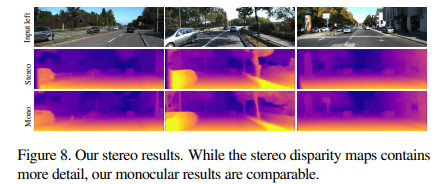
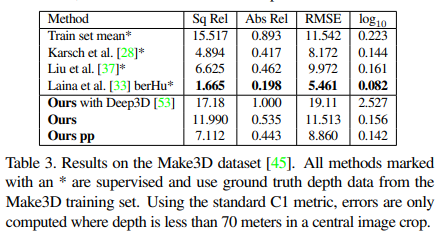
그러나 stereo이미지로 실험을 했을때, 모든 평가 매트릭에서 더 좋은 성능이 나왔다고 합니다. 그래도 mono를 사용해도 comparable 했다고 한데 의의를 두고 있습니다.
논문 저자는 해당 연구를 video로 확장하고 pixel 단위의 depth estimation이 아닌 모든 occupancy에서의 depth를 estimation하는 그런 연구를 해보고 싶다고 합니다.
3-4 Implemetation
음… 모르는 부분이 있을 때 위의 깃허브를 참고했었는데 오피셜이 아닌가보네요.
여기가 오피셜 코드가 공개되어있는 깃 인거 같습니다.
Implementation까지 해보진 못하고 논문을 읽다가 이해가 안되는 부분은 코드를 조금 살펴보았습니다.
이상으로 리뷰 마치겠습니다.
리뷰 잘 읽었습니다.
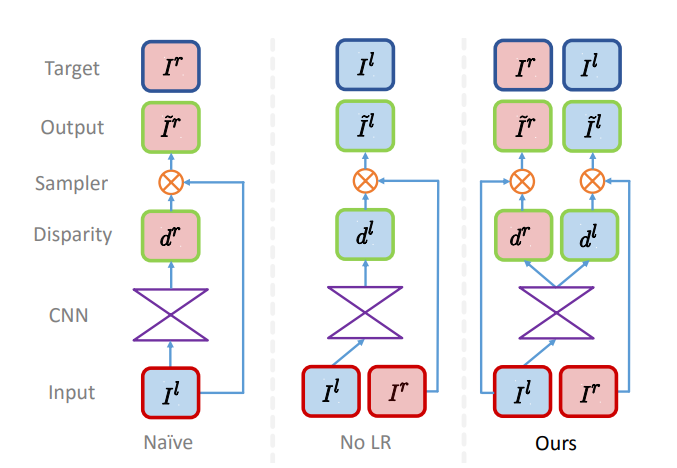
리뷰 내용 중 mono depth의 pipelien을 나타낸 그림이 있는데, Ours 뿐만 아니라 나이브와 No LR의 pipeline도 같이 있더군요. 리뷰에는 mono depth piepline에 대한 설명만 있고, 해당 방법론들이 어떤 방식이며 이들의 문제점이 무엇인지에 대한 내용은 없는 것 같은데 혹시 설명해주실 수 있을까요?
Naive는 left image를 cnn 모델에 태운 후 right image와 align이 맞는 disparity를 만듭니다. 하지만 우리가 원하는 정보는 left image와 align이 맞는 disparity이기 때문에 right image로 부터 추가적으로 sampling을 해야합니다.
그리고 중간의 No LR은 left image와 align이 맞는 disparity를 구하나 left right consistency를 고려하지 않은 파이프라인입니다. left image만을 cnn모델에 넣어서 disparity를 구하고 그를 이용하여 right image까지 구합니다. 그리고 그렇게 구한 right image를 사용하여 left image를 구하는 방향으로 학습을 합니다.
Post processing 부분이 잘 이해가 안됩니다.
혹시 관련된 figure는 없나요? 그리고 disparity ramp가 의미하는 바가 무엇인가요?
++ 혹시 논문에 SSIM에 2를 나눠주는 이유가 적혀져 있나요? SSIM을 이용하는 loss들은 전부 2로 나눠주는데 이유가 궁금하네요
figure 자료는 논문에는 없었습니다. disparity ramp는 ramp function 과 비슷하게 확 바뀌는 구간이라고 이해했습니다.
논문에서 SSIM을 2개로 나눠주는 이유는 이미지의 품질을 비교하기 위함입니다.
Post-processing하는 과정에서 앞의 5%하고 뒤의 5% 을 combine하는 방법만 언급을했는데 중앙값들은 left와 right의 평균값을 사용한다고 합니다.