
이 논문은 사람의 시각 인식 세포가 Fast motion과 Slow motion에 동시에 반응하는 것에서 영감을 얻게된 논문입니다.
주로 어떤 사람이 걷다가 속도를 올려 뛰게 된다해도 그 장면은 “사람”이라는 범주에 항상 포함될 것이고, 손을 흔들고 있어도 흔드는 속도와 관계없이 “손”이라고 인식될 것입니다. 이러한 경우를 봤을 때, 의미론에서 인식은 한 장면의 물체가 연속된 장면의 행동보다 중요시 되어지며 이를 “slow” 라는 단어로 표현할 수 있습니다.
반면에 걷기, 뛰기, 박수치기와 같은 상황들은 행동이 빨라지면서 다른 행동으로 인식될 수 있습니다. 이처럼 동작을 인식할 때는 연속된 장면의 행동이 중요시 되어지며 이를 “fast”라는 단어로 표현할 수 있습니다.
앞선 예시에 영감을 얻어 본 논문의 저자는 효율적인 video model 을 위해 Slow pathway와 Fast pathway가 동시에 설계된 SlowFast network를 제안하였습니다. SlowFast network 에서 Slow pathway는 시간 축으로 Fast pathway에 비해 frame을 비교적 적게 추출하여 사용하기 때문에 각 frame 내의 공간 정보나 의미에 대해 집중하여 연산합니다. 그리고 Fast pathway의 경우 많은 frame을 입력으로 넣어 가벼운 구조로 연산되고, 연산된 정보를 Slow pathway에 전달해주는 구조입니다. 또한, Fast pathway는 이 논문 이전 video model들이 optical flow를 사용해 동작에 대한 정보를 얻었던 것을 대체한다고 볼 수 있습니다.
1. SlowFast
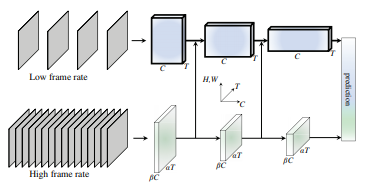
1.1 Slow pathway
Slow pathway는 C3D나 I3D와 같이 어떤 3D Convolution network든 사용가능하며, 입력 프레임에서 시간 축에 대해 넓은 간격을 나타내는 변수인 \tau를 갖게 됩니다. 이 변수를 통해 만약 원래 fps가 T x \tau인 video가 있다면 매 초 T개의 frame이 선택됩니다. 실험적으로 30-fps video 기준, \tau 값은 16으로 T는 2가 되었다고 합니다.
1.2 Fast pathway
Fast pathway에는 세가지 특징이 존재합니다. 첫번째는 좀 더 많은 frame을 입력으로 가지는 것이며, 이는 시간 축으로의 간격에 대한 변수가 \tau/\alpha, \alpha>1로 더 좁게 나타납니다. \alpha는 두 subnet가 서로 다른 시간 속도에서 작동하며, 각각을 인스턴스화하여 서로 다른 작업을 하도록 촉진시킨다는 것을 명시하게 됩니다. 이 값은 실험적으로 8로 사용되었다고 합니다.
두번째는 높은 입력 frame rate가 계속 유지된다는 것입니다. Classification을 위해 global pooling layer를 거치기 전까지 시간 축으로 어떤 downsampling도 하지 않기 때문에 매 layer 마다 시간 축으로 입력 frame의 개수인 \alphaT 가 유지됩니다.
세번째는 layer마다의 channel 수가 Slow pathway에 비해 적어 가볍다는 것입니다. 이는 영장류의 시각 세포에서 색이나 공간 정보를 활용하지 않고 fast motion을 인식하는 M-cell의 비율이 20% 정도라는 근거에 기반하여, 공간 정보 모델링 능력은 약하나 동작에 대한 정보 모델링 능력은 강하도록 trade-off 관계 속에서 설계되었습니다. 해당 구조는 frame의 색 정보를 제거하거나 입력 frame의 해상도를 낮춘 상황에서의 실험에서도 좋은 성능을 보여 앞선 근거로 설계된 가벼운 구조가 효율적임을 확인하였다고 합니다.
1.3 Lateral connections
앞서 설명한 Slow pathway와 Fast pathway는 분류를 위해 융합되지만 마지막에 융합된다면 서로 다른 표현으로 인해 융합에 어려움이 존재하게 됩니다. 이를 해결하기위해 주로 object detection 분야에서 서로 다른 해상도의 feature를 융합할 때 사용하는 lateral connection 기법을 사용하게 됩니다. 이는 Slow pathway와 Fast pathway의 매 layer 마다 적용되며, 융합시 서로 시간 축으로의 길이가 다르기에 변환을 하게 됩니다. 변환 후, Fast pathway에서 Slow pathway로의 단방향 융합을 하게 되며 이는 실험적으로 양방향 융합과 비슷한 결과를 내었다고 합니다.
1.4 Instantiations
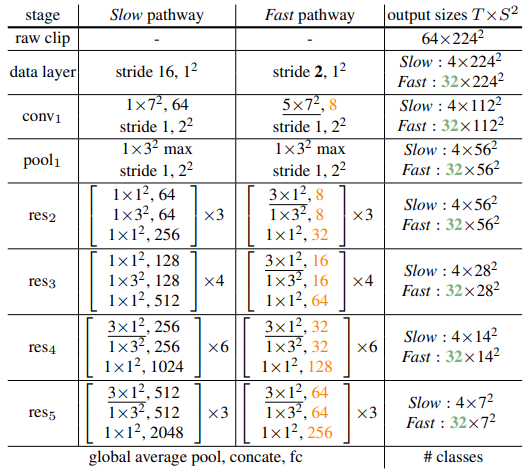
이번 절은 위와 같은 일반적인 아이디어를 서로 다른 backbone에 적용했을 때 디테일에 대해 설명합니다. Table 1에서는 3D ResNet을 사용했을 때의 예시를 나타내며 {T×S^{2}} 에서 T는 시간 축의 길이, S는 각각 frame 해상도의 높이와 너비의 곱을 의미합니다.
- Slow pathway
3D ResNet을 backbone으로 사용할 시 총 64 frame 중 \tau=16으로 두어 4개를 입력 frame으로 선택하며, 시간 축의 간격이 넓기 때문에 3D convolution 시, 시간 축으로는 downsampling 하지 않는다고 합니다. 또한, C3D와 I3D에서와 달리 시간 축 방향의 kernel 크기가 2이상인 3D convolution(Non-degenerate temporal convolution)을 res4, res5 layer에서만 이를 사용하고 이외의 앞단에서는 2D convolution과 같이 연산이 진행합니다. 이는 만약 객체가 빠르게 움직이고 있고 시간 축에서의 frame 간 간격이 넓다면 frame 내의 공간적인 receptive field가 충분히 크지 않는 한, 시간 축에서 receptive field는 각 frame 간의 상관관계를 나타내지 못하기 때문에 frame 내의 공간적인 receptive field가 넓어지는 뒷 단의 layer에만 앞서 설명한 Non-degenerate temporal convolution 을 적용하였다고 합니다.
- Fast pathway
Non-degenerate temporal convolution 을 매 layer 마다 적용하였으며 시간 축으로 downsampling 없이 설계하였다고 합니다.
- Lateral connections
\alpha는 8, \beta는 1/8일 때 Slow pathway feature의 크기는 {T×S^{2} , C}로 표현되고, Fast pathway feature의 크기는 {\alpha T×S^{2}, \beta C}로 표현됩니다. 이러한 feature들을 Fast pathway에서 Slow pathway방향으로 융합하는 것이 Lateral connection의 목표이며 이를 위해 Fast pathway feature에 다음과 같이 세 가지의 변환을 실험하였다고합니다.
- Time-to-channel (TtoC): {\alpha T×S^{2}, \beta C}를 { T×S^{2}, \alpha \beta C}로 transpose해 변환시키는 방식이며 \alpha개의 frame이 한 frame의 channel이 되는 것을 의미합니다.
- Time-strided sampling (T-sample): 매 \alpha개의 frame 중 하나를 샘플링 해 {\alpha T×S^{2}, \beta C}를 {T×S^{2}, \beta C} 로 바꾸는 변환 입니다.
- Time-strided convolution (T-conv): 시간 축으로 stride가 \alpha이고 kernel 크기가 5x1^{2}, 출력 값의 channel이 2\beta C인 3D convolution으로 시간 축의 길이를 맞추는 변환입니다.
2. Experiments
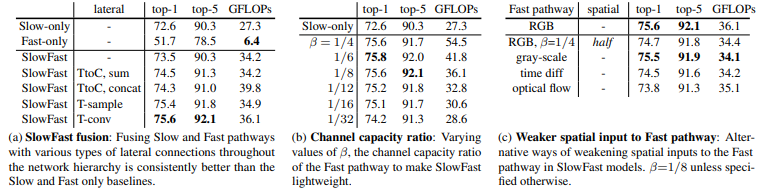
Table 2는 Fast pathway를 설계하는 과정에서 얻은 실험 결과입니다.
Table 2-(a)에서는 Slow pathway와 Fast pathway를 융합해서 사용하는 것이 가장 좋은 성능을 보이는 것을 알 수 있으며 Fast pathway에서 Slow pathway로 융합하는 세가지 방법중 T-conv가 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
Table 2-(b)는 fusion을 위해 각 pathway의 feature 크기를 나타낼 때 사용한 \beta 값에 대한 실험 결과입니다.
Table 2-(c)는 Fast pathway에 각 frame 내의 공간적인 정보나 색 정보는 크게 영향을 미치지 못하는 것을 뒷받침해주는 실험입니다.
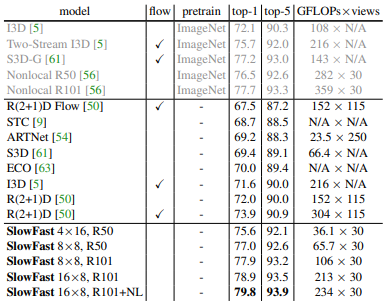
Table 3은 Kinetics-400 데이터 셋에서 논문 게재 당시 SOTA의 성능을 뛰어넘은 것을 나타내며 Non-local block을 추가하였을 때 가장 좋은 성능을 보이는 것을 확인 할 수 있습니다. 이뿐만 아니라 같은 video action recognition 데이터 셋인 Kinetics-600, Charades에서도 SOTA를 달성하였으며, AVA의 action detection 분야에서도 SOTA를 달성하였습니다.
3. Reference
[1] https://arxiv.org/pdf/1812.03982.pdf