논문소개
이번에 리뷰하게된 논문은 3D object detection에 관한 논문입니다. 3D Object detection은 자율주행, 로보틱스에서 많이 사용되며 2D와 비교하면 상당히 난이도가 있는편입니다. 이때 난이도라고하면 학습난이도, 코딩난이도, 데이터셋 제작 등등 모두를 포함합니다. 자료또한 별로 없는 편인데 해당논문은 코드를 공개하고 있습니다. 해당 코드는 SECOND 베이스로 제작이 되었다는데 SECOND에 대해서도 조만간 리뷰를 해볼까 생각중입니다. CVPR 2019 페이퍼인점으로 보면 상당히 완성도가 있는 논문이라고 생각합니다.
3D 데이터셋으로 유명한 KITTI 데이터셋을 사용하였고 속도, 정확도 측면에서 좋은 성능을 보였습니다.
여기까지 논문에 대한 기본적인 소개를 마치었습니다. 해당논문이 어떠한 점에서 읽을 가치가 있는지에 대한 소개를 먼저 해보았습니다. 이제 본격적으로 논문에대한 리뷰를 시작해보겠습니다.
일부러 논문과 같은 소제목으로 구성하였습니다. 따라서 이해 안가시거나 좀 더 디테일하게 알아보고 싶으신 분들은 논문의 해당 소제목을 살펴보시면 도움이 되실겁니다.
Abstract
라이다 기술이 발달하면서 포인트 클라우드를 이용한 object detection에 대한 연구가 활발히 진행되고 있습니다. 먼저 포인트 클라우드는 정보량이 상당히 방대하기 때문에 inference타임과 accuracy의 trade-off 관계를 잘 생각해야 합니다.
포인트 클라우드 정보를 이용하여 object detection을 하기위해서는 encoder를 설계해야합니다. Encoder는 포인트클라우드 raw data를 알맞은 형태로 가공 해주는 역할을 합니다. 최근 방법론들중에는 크게 2가지 종류의 encoder들이 있습니다.
- Fixed encoders
- Encoders that are learned from data
첫 째인0 fixed encoder의 경우 속도가 빠르나 정확도 측면에서는 떨어집니다. 두 번째의 경우 정확도는 좋으나 속도가 떨어지는 경향을 띕니다.
해당 논문에서는 PointPillars라는 novel encoder를 제안합니다. 이는 기존에 존재하던 방법론인 PointNets를 최적화한 방법론입니다. 여기서 최적화란 표현은 vertical columns(pillars)로 구성된 point clouds의 representation을 말합니다.
Encoded feature는 2D convolutional detection architecture와 같이 쓰일 수 있습니다.
Introduction
서울과 같은 도심지에서 무인이동체 (드론, 자율주행차)등을 활용하는 것은 기술적으로 많은 어려움점들이 있습니다. 그러한 것들중 한개가 움직이는 object들을 검출하는 것 입니다. 이 때, object들은 경우에 따라서 보행자, 자전거, 차량들 등이 될 수 있습니다. Object들을 실시간으로 검출하는 것은 쉬운일이 아닙니다. 먼저 무슨 센서를 사용할지 정해야하고, 어떠한 방법론을 사용할지 정해야합니다. 그리고 정확도, 추론속도 등을 고려해야합니다.
다들 아시다시피 Object detection을 위해 라이다 센서를 가장 많이 사용합니다. 현대 과학에서 라이다가 가장 좋은 성능을 보인다는 것은 반박할 여지가 없기 때문입니다. 라이다센서는 물체와 물체간의 거리를 측정합니다. 빛이 반사되어 다시 돌아올 때 까지의 시간을 측정하는데 거리가 가까운 경우에는 몇 나노초밖에 되지 않습니다. 과거에도 라이다센서는 존재했지만 정밀하지 못해서 보통 비행기에서 측량을 하는 등 거리가 먼 경우에만 사용했습니다. 그러나 라이다 센서 기술이 발전하며 자율주행 차량에서도 사용을 할 수 있게 되었습니다.
라이다 센서는 기본적으로 레이저 스캐너를 이용합니다. 라이다로 측정한 depth에 대한 결과값들을 point clouds라고 합니다. 일반적으로 라이다센서를 이용한 로보틱스에서의 파이프라인은 bottom-up 방식입니다. 예를들어 배경을 제거하고, clustering하고, classification하는 식으로 단계적으로 수행합니다.
컴퓨터비전과 딥러닝의 발달에 따라 포인트 클라우드를 어떠한 방식을로 처리할지에 대한 연구가 많이 이루어져 왔습니다. 이를 얘기하기전에 먼저 3D데이터인 포인트클라우드와 2D 이미지 사이에는 어떠한 차이점들이 있는지 알아야합니다.
- 포인트 클라우드는 2D이미지 보다 sparse합니다.
- 포인트 클라우드는 3D, 이미지는 2D로 차원이 다릅니다.
이와같은 차이점때문에 이미지를 다루는 방식으로 convolutional pipeline을 구성할 수 없습니다.
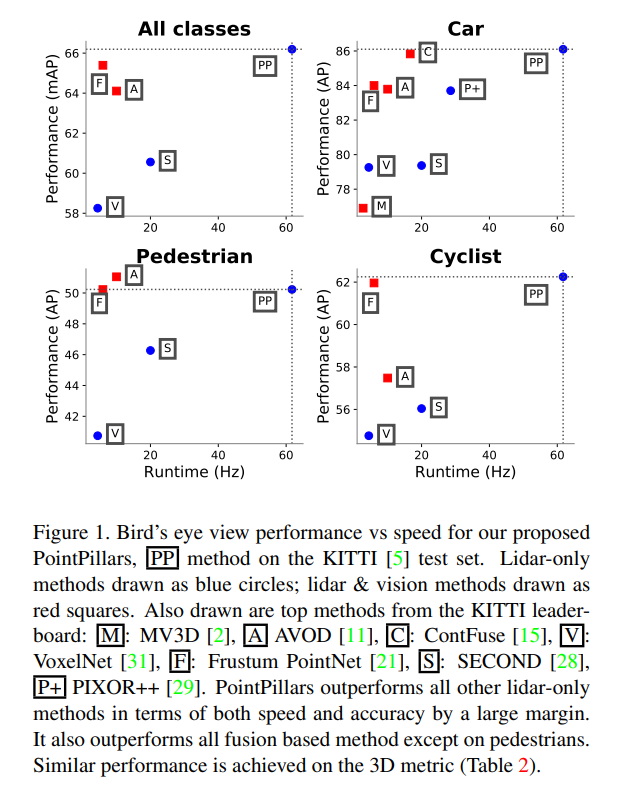
이를 해결하기 위한 가장 나이브한 생각은 3D convolution을 구성하는 것 입니다. 실제로도 과거 work들은 3D convolution을 구성하는게 많았습니다. 그러나 최신 방법들은 Bird’ s eye view를 이용하느 경향이 있습니다. Bird’s eye view를 사용하면 스케일 변화와 occlusion에 좀더 강인할 수 있기 때문입니다. Figure 1은 Bird`s eye view에서 저자가 제안하는 PP(Point pillars)가 얼마나 좋은 정확도와 속도를 가졌는지 보여주는 지표입니다.
그러나 Bi rd’s eye view는 extremely sparse하다는 단점이 있습니다. 어찌보면 당연한 이야기입니다. sparse한 포인트 클라우드를 위에서 바라보는 birds eye view는 당연히 sparse할 수 밖에 없습니다. 이러한 특성때문에 bird’s eye view를 곧 바로 CNN에 적용하면 효율적이지 못합니다. 즉, 적절한 가공이 필요합니다.
적절한 가공을 위해 주로 사용하는 방법은 partitioning 하는 것 입니다. 예를들어 10 x 10 cm의 일정한 gird cell을 가지게끔 나눌 수 있습니다. 그리고 hand crafted feature encoding method를 각각의 gird cell안에 있는 points들에 적용합니다. 그러나 이러한 방식은 일반화된게 아니기 때문에 새로운 데이터가 들어왔을때 다시 일일히 작업해야하는 번거로움이 있습니다. 이를 해결하기 위해 나왔던 방법이 VoxelNet입니다. VoxelNet은 hand-crafted 과정을 생략하고 첫번째로 end-to-end로 만들었다는 점에서 큰 의미를 갖습니다.
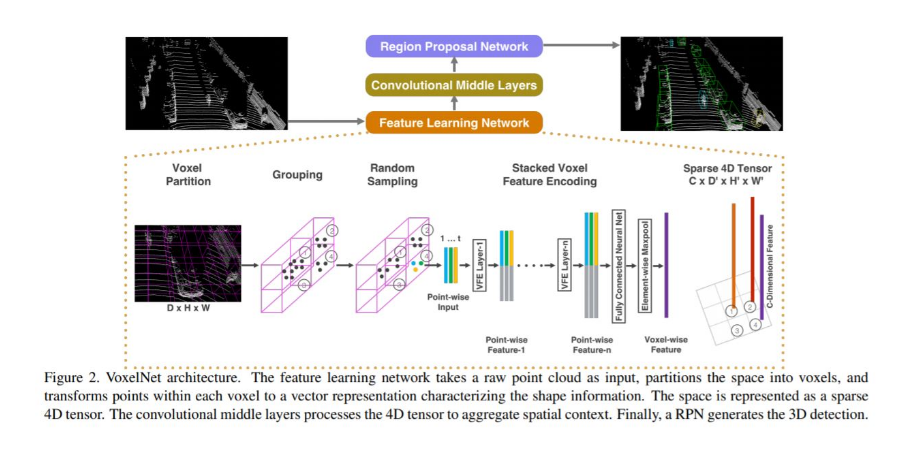
VoxelNet을 설명하기위해 이미지를 가지고 왔습니다. VoxelNet에서는 포인트클라우드 공간을 voxel단위로 나눕니다. 이후 3D convolutional middle layer를 통해 vertical axis를 consolidate합니다. 그런 다음 최종적으로 2D convolutional detection architecture가 적용됩니다. VoxelNet을 정확하게 이해한건 아니라 조만간 읽어본 후 리뷰하겠습니다.(읽을 논문이 참 많네요)
VoxelNet은 정확도가 높은편이지만 real time으로 inference하기에는 너무 느립니다. 그래서 최근(2019년)에는 SECOND라는 방법론이 나왔습니다. SECOND는 VoxelNet의 느린 inference time을 끌어올린 방법론입니다. 그러나 여전히 3D convolution을 사용하기 때문에 해당 부분이 bottleneck으로 남습니다.
해당 논문에서는 위에서 언급한 단점들을 해결한 PointPillars를 제시합니다. 우선 VoxelNet과 마찬가지로 end-to-end 이고, 3D convolution을 사용하지 않음으로써 bottleneck이 생기지않아 속도가 빠릅니다.
PointPillars는 독자적인 encoder를 사용합니다. 해당 encoder는 3D object의 bounding boxes를 예측하기위해 feature를 pillars단위로 학습합니다. 이때 pillars라는 개념이 좀 생소할 수 있는데 vertical columns를 pillars라는 용어로 사용하였습니다. 어찌됐든 partitioning하는 방법을 사용하여 포인트 클라우드를 나누었단 점에서 기본적인 컨셉은 VoxelNet과 비슷한거 같습니다.
이러한 pillars단위의 학습이 갖는 장점은 fixed encoder에 비해 포인트 클라우드의 모든 정보를 활용할 수 있습니다. 또한, voxel단위로 나누는 것에 비해 binning of vertical direction을 손으로 tune할 필요가 없습니다. 이와 더불어 pillars를 사용할 경우 주요 연산들이 모두 2D convolution으로 구성되어 GPU를 이용한 병렬 연산에 매우 효율적입니다. 마지막으로 hand-tuning이 필요없는 end-to-end 방식이므로 다양한 lidar scan 혹은 radar point clouds 까지도 쉽게 활용할 수 있습니다.
PointPillars network는 KITTI dataset에서 평가를 진행하였습니다. KITTI 셋은 Bird’s eye view 혹은 3D 형태로 자동차, 보행자, 싸이클리스트를 포함하고 있습니다. Bir d ‘s eye view와 3D 포인트클라우드 모두에서 속도, mAP가 좋게 나왔습니다. 이에 대해서는 뒤에서 마저 리포팅 하겠습니다.
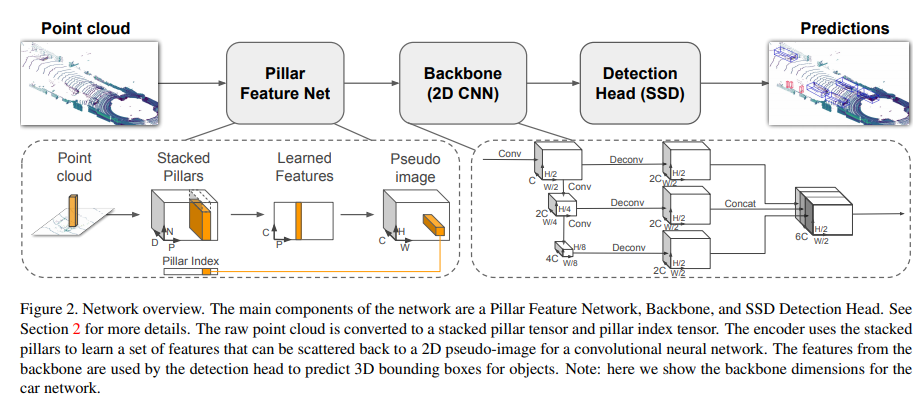
PointPillars에 대한 전체적인 파이프라인 입니다. 3D Object Detection에는 PointNet과 그를 voxel단위에 적용한 VoxelNet을 기반으로 한 연구들이 많습니다. 해당 논문에서 제안한 PointPillars 역시 위의 논문들을 기반으로 하였습니다. VoxelNet에서는 end-to-end 방식과 높은 정확도를 달성하였지만, 3D convolution layer 가 bottelneck으로 작용하며 inference time이 너무 높았습니다. 이에 real-time으로 적용하기에는 무리가 있었습니다. 이 후 연구들인 Frustum PointNet과 SECOND역시도 3D convolution이 여전히 bottleneck으로 자리잡았습니다. 이에 PointPillars 저자는 2D convolution만을 사용한 end-to-end 방식의 network를 제안했습니다. 주요 contribution은 아래와 같습니다.
- We propose a novel point cloud encoder and network, PointPillars, that operates on the point cloud to enable end-to-end training of a 3D object detection network.
- We show how all computations on pillars can be posed as dense 2D convolutions which enables inference at 62 Hz; a factor of 2-4 times faster than other methods.
- We conduct experiments on the KITTI dataset and demonstrate state of the art results on cars, pedestrians, and cyclists on both BEV and 3D benchmarks.
- We conduct several ablation studies to examine the key factors that enable a strong detection performance.
사실 위의 4가지 내용은 위의 글에서 다 설명한 내용과 오버랩되는 내용입니다.
PointPillars Network
PointPillars Network는 포인트클라우드를 인풋으로 받고 3D box를 예측합니다. 이러한 과정은 총 3개의 단계로 구성됩니다.
- Feature encoder network가 포인트 클라우드 데이터를 sparse한 pseudo-image로 변환
- 2D convolution backbone을 이용하여 pseudo-image를 high-level representation로 변환
- Detection head를 붙혀 3D box를 regression하고 class를 classificaiton
Pointcloud to Pseudo-Image
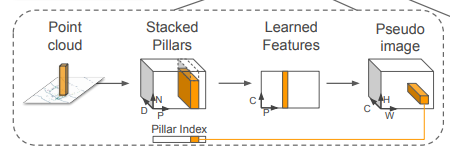
2D convolution을 적용하기 위해 먼저 Feature encoder network를 통해 포인트 클라우드 데이터를 sparse한 pseudo-image로 변환합니다.
필러내의 각 포인트들은 다음과 같은 정보를 가집니다.
- x, y, z (x, y, z 좌표값)
- x_c, y_c, z_c (pillar내 센터로부터의 거리)
- x_p, y_p (필러내 포인트들의 산술평균)
- r 반사도
즉 1,2,3,4 를 모두 합치면 9개의 dimension이 나옵니다. 이렇게 9개의 dim을 가지는 포인트를 l이라고 notation하고 augmented lidar point라고 칭하겠습니다.
각각의 pillar는 sparse하기 때문에 empty이거나 몇개의 point들만을 포함한 경우가 많습니다. 대략적으로 97% 정도의 sparsity를 갖습니다. 이러한 문제점은 각각의 pillar마다 point의 최소값N과 각 샘플마다의 non-empty pillar의 개수P를 설정함으로써 해결합니다. 이 정보들을 종합하면 dense tensor는 총 (D, P, N)의 정보를 가지게 됩니다. 이때 D는 위에서 말했던 dim에 관한 정보입니다. 이때 만약 sample이나 pillar에 너무 많은 데이터가 들어있어 tensor에 맞지 않으면 data가 랜덤하게 추출됩니다. 그와는 반대로 데이터가 너무 적게 들어있어 tensor를 구성 할 수 없으면 zero padding이 추가됩니다.
그 다음으로는 각각의 포인트마다 linear layer가 적용된 simplified된 버전의 PointNet을 사용합니다. 각각의 linear layer는 Batch-norm과 ReLU를 통해 (C, P, N )사이즈의 텐서를 만듭니다. 이후에는 chanel의 max값을 취해서 (C, P)형태의 텐서가 나옵니다. 이때 linear layer는 1×1 convolution의 형태로 나타낼 수 있습니다. 1×1 convolution을 사용하는 이유는 채널개수와 파라미터 개수를 조정하기 위함입니다. 이렇게 encoding을 마치면 feature는 기존의 pillar 위치에 흩뿌려지고 이는 (C,H,W)사이즈의 pseudo-image를 만듭니다.

Backbone
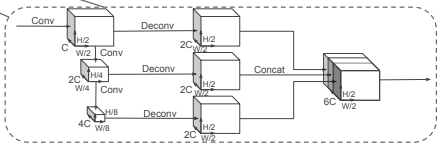
Backbone은 2개의 sub-network를 가집니다. 한개는 top-down network로 increasingly small spatial resolution에서의 feature를 만듭니다. 또 다른 sub-net은 이렇게 나온 top-down feature들을 upsampling과 concatenation을 합니다.
Upsampling할때 stride는 pseudo-image에 맞게 S_in, S_out으로 구성되며 upsampled feature에는 Batchnorm과 ReLU가 적용됩니다. 그리고 최종 output feature는 각각의 다른 stride로 생성된 feature들을 모두 concat해준 형태입니다.
Detection Head
해당 논문에서는 SSD를 detection head로 사용합니다. prior boxes를 그리고 해당 박스들과 GT박스와 비교하여 IoU를 구합니다. 이를 이용하여 hard negative mining 기법을 사용합니다. 즉, 모든 박스에대한 loss를 back propagation하는게 아닌 negative 값들을 계산에서 제외합니다.
Network
Pre-trained된 network를 사용하지 않고 모든 weight들을 uniform distribution방식으로 초기화 했습니다.
Encoder network는 64개의 output feature를 갖습니다. car, pedestrian, cylist의 backbone들은 stride를 제외하곤 같습니다. car에서의 stride S=2, cylist/pedestrian 에서의 S=1입니다. 각각의 network은 3개의 블락으로 구성되어집니다. Block1(S, 4, C), Block2(2S, 6, 2C), Block3(4S, 6, 4C) . 각각의 블락은 Up1(S, S, 2C), Up2(2S, S, 2C), Up3(4S, S, 2C)로 upsample됩니다. 그리고 concatenate된 후 6C로 합쳐져셔 detection head로 전달되게 됩니다.
Loss

Loss term은 위와 같이 정의됩니다. 이는 SECOND 논문에서 제안하는 loss와 같다고 하는데 좀 더 자세히 이해하고싶으신 분들은 해당논문을 찾아보는게 좋을거 같습니다.
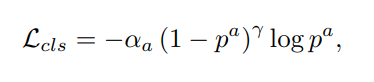
object classification에 대한 loss는 위와같은 focal loss를 사용합니다.
이때 알파와 감마의 값은 0.25, 2로 기존 페이퍼에서 제안하는 값을 그대로 사용했습니다.
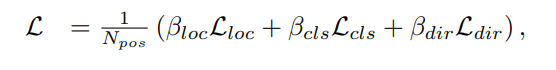
위의 loss텀들을 종합한 최종적 loss는 위와 같습니다. N_pos는 possitive anchor의 개수를 의미하고 베타들은 각각 상수입니다. Optimizer는 Adam을 사용했습니다. 좀 더 정확한 세팅값은 코드를 참고하면 될거 같습니다.
Experiment
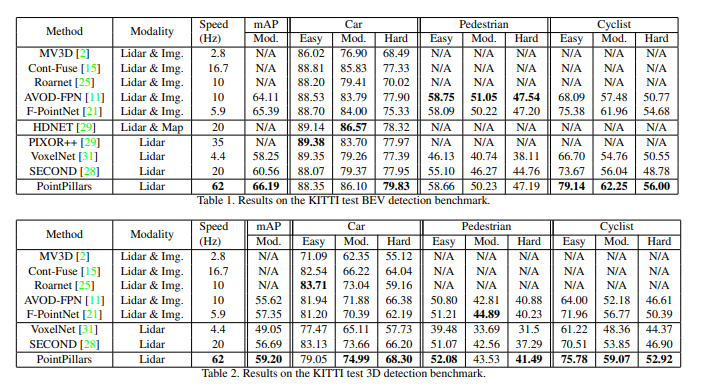

평가는 KITTI dataset에서 진행하였고, 속도, 정확도면에서 SOTA를 달성했습니다.
Augmentation은 KITTI dataset에서 매우 중요합니다. 먼저 모든 클래스에 대해 GT 3D box의 정보와 그 안에 들어가는 point들의 정보가 담긴 lookup table을 만듭니다.
성능이 좋음에도 빠른 이유는 encoding 하는 과정에 있습니다. 위에서 언급했듯 3D convolution을 제거했기 때문입니다. 그 후 GT를 각 클래스별로 랜덤하게 뽑아온 후 그를 현재 포인트클라우드에 위치시킵니다. 그리고 모든 GT box를 개별적으로 augmentation 해줍니다. 이때는 rotation, translation이 적용됩니다. 이 후엔 random mirroring flip과 scaling등이 적용됩니다. 자세한건 코드를 봐야할거 같습니다.
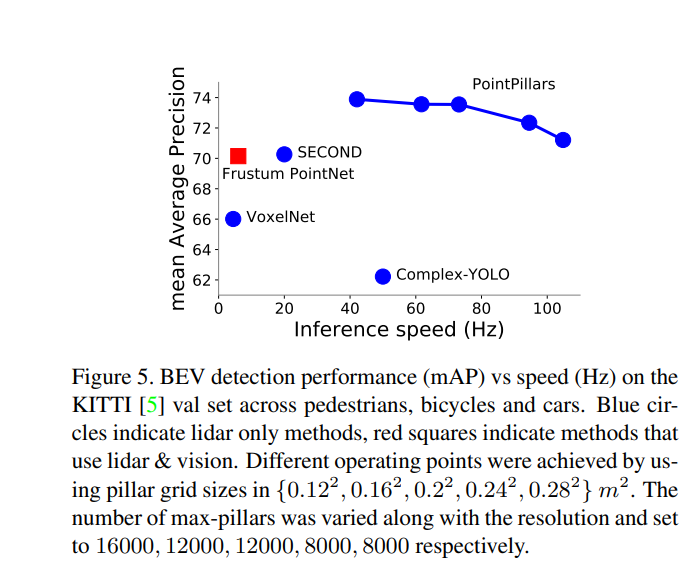
Figure5에서는 PointPillars의 inference speed와 mAP 를 보여줍니다. 둘은 trade-off 관계에 있음에도 PointPillars에서 둘 다 상당히 좋은 결과를 보입니다.
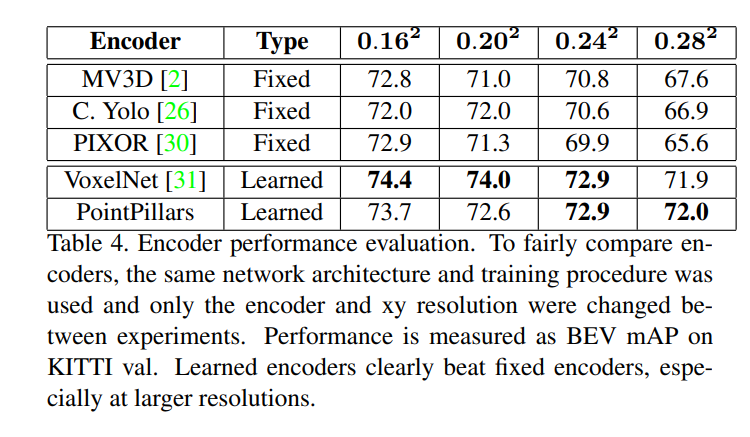
위의 자료는 fixed encoder 보다 좋은 성능을 보였음을 보여줍니다.
이렇게 리뷰를 마치겠습니다.
좀 더 정확한 이해를 위해 VoxelNet하고 PointNet, SECOND를 읽어봐야겠습니다.
좋은 리뷰 감사합니다!
point를 birds eye view로 사용한다는 것은 3D를 2D로 눌러서 사용한다는 건가요? 신기합니다
글에서 나오는 vertical columns와 pillar의 개념이 조금 어렵네요..
pillar는 voxel 표현의 grid같은 개념일까요..?
제가 이해한선에서 답변 해드리겠습니다. bird`s eye view로 사용하는것은 VoxelNet에서도 등장한 개념입니다. PointPillars net의 주요 contribution은 bird`’s eye view를 사용한 것이 아닌 pillar단위로 나눈 novel한 encoder를 설계한 것과 3D convolution을 제거하여 inference speed를 키웠음에 있습니다.
BEV는 성능평가를 위해 사용되었습니다. pillar는 voxel처럼 grid로 나눈것이 맞습니다. 나눈 모양이 pillar(기둥) 같이 생겨서 이름이 그렇게 붙은거 같습니다.
lidar point로 pseudo image를 만들고 여기서 3D object detection을 하는 것으로 이해하였는데, pseudo image 를 만드는 과정에서 실제 데이터 셋 내의 2d image는 사용되나요?
pseudo image를 만드는 과정에서는 라이다 데이터만을 사용합니다.