해당 방법은 Multisepctral Pedestrian Detection Datasets들이 하나의 bounding box를 사용하여 예측함으로써 다른 장비를 통하여 촬영된 multi-modal간 어긋난 현상을 추가적인 모듈을 통해 정렬함으로써 성능을 향상시킨 방법론 입니다.
Intro

2 stage 방법론 중, 특히 Region Proposals Network(RPN, faster R-CNN에서 제안됨)을 사용하는 방법들은 Figure 1-(a)와 같이 bounding box의 ground truth가 어긋난 상태에서는 예민한 영향을 받을 수 있다고 주장합니다.
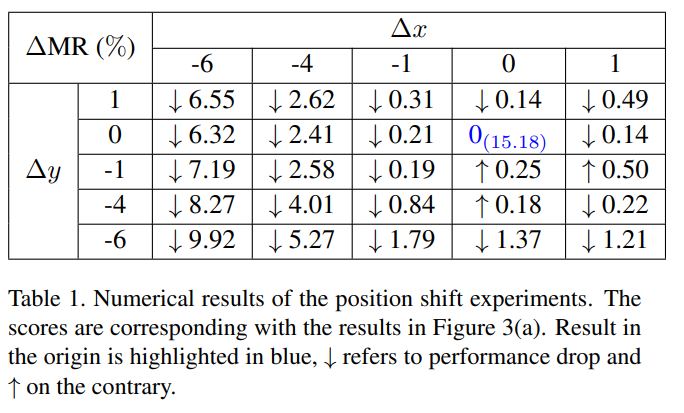
위의 실험 결과(Table 1, Thermal 영상은 그대로 둔 상태에서 RGB 영상을 이동시키면서 나온 성능(MR)의 차) 통해서 multi-modal간 bbox position shift problem이 만드는 성능의 영향을 보여줍니다. 저자는 position shift가 커질 수록 성능에 큰 영향이 커지기 때문에 여기서 모티브를 얻어 Aligned Region – Convolution Neural Network(AR-CNN)를 제안했다고 합니다.
해당 논문에서 기여한 바는 아래와 같습니다.
- Multi-modal간 bbox position shift problem을 해결하기 위한 Region Feature Alignment(RFA)와 position shift problem에보다 강인하게 하기위한 학습 전략인 RoI jitter를 제안했습니다.
- AR-CNN을 실현하기 위해서 각 multi-modal에서 새로 annotation을 진행한 KAIST-Paired annotation을 만들었으며, 공개함으로써 커뮤니티에 기여하였습니다.
- 2019년 Multispectral Pedestrian Detection에서 SOTA( KAIST, CVC-14 )를 달성하였습니다.
Method
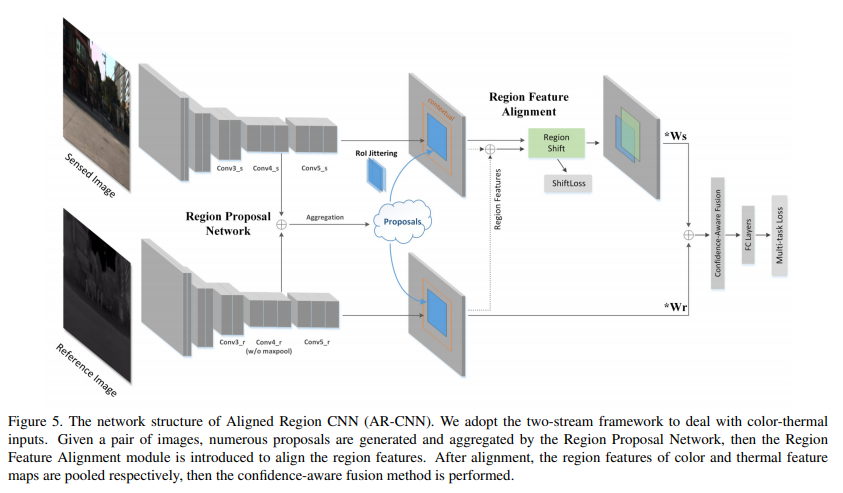
AR-CNN은 faster R-CNN에서 영감을 얻어 만들어진 “Multispectral Deep Neural Networks for Pedestrian Detection”의 late fusion에 RFA 모듈을 추가한 방법론 입니다.
기본적인 파이프라인을 설명하자면 아래와 같습니다.
- ImageNet으로 pre-trained VGG를 각 RGB, Thermal에 독립적으로 backbone model로 사용을 합니다.
- 각 multi-modal의 conv4 – feature를 concatenate 한 후, RPN에 넣어줌으로써 class score(object/no-object, binary classification)와 bbox의 위치(cx, cy, w, h)를 획득합니다.
++ RPN은 faster R-CNN의 방법을 그대로 가져가며 loss도 동일하게 사용합니다. - Thermal는 변경 없이 그대로 두고, RGB에서만 RFA 모듈(아래에서 설명)에 삽입합니다. RFA 모듈을 통해 mutil-modal간 shift 정도를 예측하고, 예측된 RGB의 bbox의 위치를 수정합니다.
++ RFA 모듈 이전에 예측된 RGB의 bbox를 RoI jitter를 통해 변화를 줌으로써 RFA 모듈의 과/소적합을 방지합니다. - RGB는 수정된 위치로 feature map을 추출(RoI pooling)합니다.
- 4의 결과를 반영하기 위해 새롭게 re-weighting 합니다. 그를 위해 Confidence-Aware Fusion(아래에서 설명)을 진행하여, object에 대한 최종적인 class score를 추정합니다.
++Thermal는 RFA 없이 RPN에서 예측한 정보를 이용하여 RoI pooling을 진행합니다.
Region Feature Alignment(RFA)
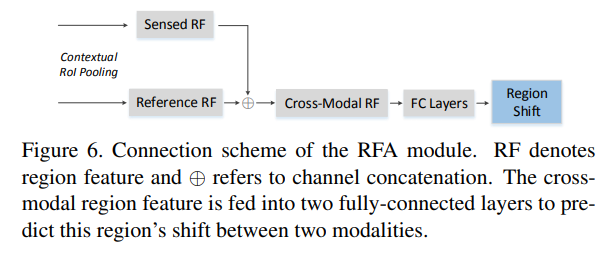
논문에서 새롭게 제안하는 부분은 RFA만 봐도 무방하다고 생각합니다.
해당 부분도 RPN의 bbox의 position regression 부분에 ground truth를 자신들이 새롭게 만든 KAIST-paired annotation(RGB, Thermal에서 다시 annotation을 진행함)을 사용합니다.
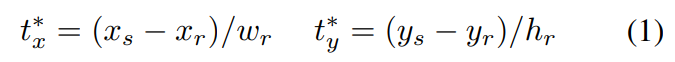
{x,y}_s, {x,y}_r는 KAIST-paired annotation에서 얻은 s:RGB, r:Thermal의 bbox입니다. 수식 1을 통해 RGB와 Thermal의 bbox의 shift 정도를 GT로 사용합니다.
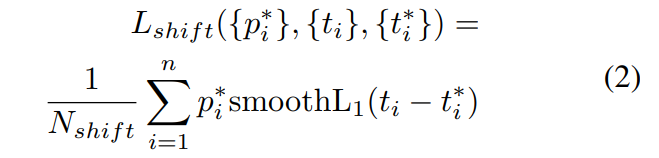
그 후, RPN으로 통해 추측된 bbox 정보를 수식 1을 통해 얻은 t_i를 smoothL1을 이용하여 shift 정도에 대해 예측을 하도록 학습 시킵니다. (++class GT : p^(*)_(i), pedestrian = 1, background = 0)
위의 방법을 통해 RFA는 예측한 RGB의 bbox의 shift 정도를 예측하고 bbox를 다시 변경함으로써 정렬된 위치에서 RoI Pooling을 진행합니다.
RoI Jitter Strategy
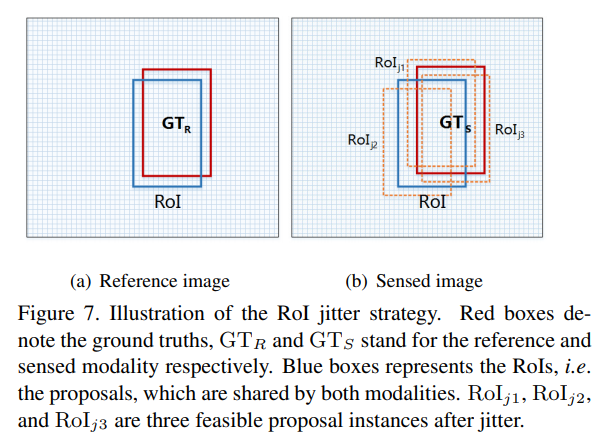
RFA 모듈에서 과/소적합을 방지하기 위한 학습 전략으로 제안된 학습 방안 입니다.
해당 방법은 RPN으로부터 예측된 bbox를 랜덤하게 나온 t를 역으로 수식 1 풀어줍니다. 그럼으로써 다양한 분포를 가진 bbox를 RFA 모듈에서 학습하도록 도와줍니다.
Confidence-Aware Fusion
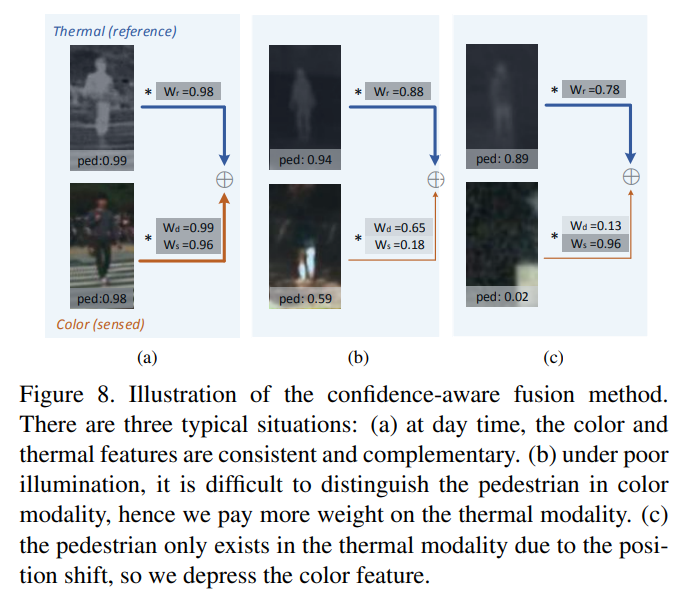
Confidence-Aware Fusion는 RFB을 통해 새로 추정된 bbox로 다시 re-weighting 하기 위해서 적용됩니다.
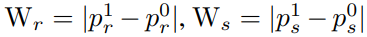
위의 수식으로 RGB와 Thermal의 confidence weight를 구합니다. (p^1 : 보행자일 확률, p^0 : 배경일 확률, 어디서 얻은 확률인지 나오지는 않아 작성하지 못했습니다. 코드 레벨에서 확인이 필요할 듯….)
그럼 다음 feature map에 각 modality에 곱해줍니다.
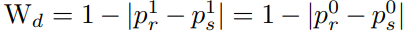
추가로 한 modality에서 보행자가 검출되지 않은 경우, 예를 들어 어두운 상황에서 RGB에서는 보이지 않고 Thermal에서만 보이는 경우를 대비하여 위의 수식을 추가로 RGB에 곱해줍니다. 그 후 두 modality feature map을 합한 후, FC layer에 태워 최종적인 class score를 얻습니다.
++ loss는 faster R-CNN과 동일하게 cross-entropy loss를 사용하며, 보행자 검출이기 때문에 binary cross-entropy loss를 사용합니다.
최종적인 Loss 식은 아래와 같습니다.
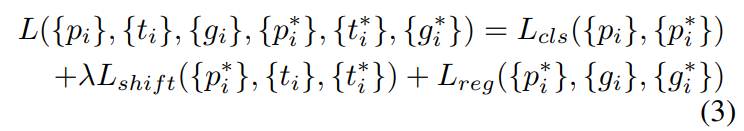
Experiments
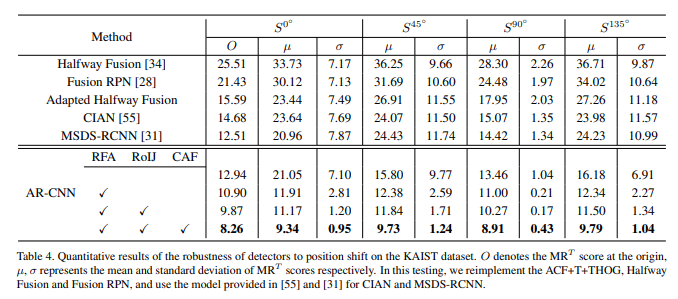
S^{0도, 45도, 90도, 135도}는 RGB 영상을 해당 각도로 이동 시킨 후, 진행한 성능 평가 지표입니다. 다른 방법론에 비해 position shift problem에 강인함을 볼 수 있습니다.
좋은 리뷰 감사합니다. 개인적으로 저도 해당 논문을 읽었을때 기존방법으로 Thermal이미지를 고정하고 RGB를 shift하면서 성능평가할때와 AR-CNN으로 평가할때 성능차이없이 align이 잘 이뤄짐을 나타낸 그림과 설명이 없어 아쉽네요
글의 맨 앞부분 “하나의 bounding box를 사용하여 예측함으로써” 해당부분에서 하나의 bounding box를 사용한다는 이해가 안가네요. 데이터셋을 annotation할 때 RGB와 Thermal 영역에서 같은 위치에 bounding box를 그렸단 얘긴가요? annotation할때 RGB와 Thermal 각각 진행하는지 아니면 mapping한 상태로 1개의 bounding box만을 그리는지가 궁금합니다.
한개만 그린다면 alignment가 안 맞는 이유는 mapping을 정확히 할 수 없기 때문으로 이해하면 되나요?
구두 설명