
2020년 4월 저는 CVPR에 나온 Anchor Free 방식으로 당시 Pedestrian Detection 네트워크인 CSP를 소개한적 있습니다.
그로부터 9개월 뒤인 오늘 제가 소개할 논문은 CSP를 Multispectral Pedestrian Detection에 적용한 논문인 ‘ Anchor-free Small-scale Multispectral Pedestrian Detection ‘ 입니다………………………..
먼저 해당 논문에서 소개하는 Contribution은 크게 다음과 같습니다.
- CSPNet Architecture를 기반으로 다양한 Fusion을 분석하였습니다.
- 새롭고 혁신적인 Multispectral data를 위한 data agumentation 기법을 제안 및 소개하고 있습니다.
- 현재 사용되고 있는 3가지 버전의 annotation에 대해서 분석 및 비교합니다. (3가지는 Original, MSDS-RCNN, AR-CNN)
- Reasonable 세팅 및 ALL 세팅 모두에서 State of the Art를 기록합니다.
먼저 본 논문에서 사용한 CSP에 대해서 궁금하신 분들은 아래 리뷰를 참고하시면 됩니다.
해당 논문에서는 기존에 Multipsectral Pedestrian Detection이 Anchor based 방법론(Faster RCNN, SSD)기반으로 만들어진것과는 다르게 Anchor Free 방식인 CSP를 이용해서 Multispectral Pedestrian Detection을 수행하였습니다.
여기서 잠깐..! 처음 딥러닝 기반 Multispectral Pedestrian Detection이 제안된 ” Multispectral Deep Neural Networks for Pedestrian Detection ” 논문을 아시나요 ..?
해당 논문은 처음 딥러닝 기반으로 Multispectral Pedestrian Detection을 제안하였고, 다음 그림과 같이 실제 어디서 RGB와 Thermal 데이터를 Fusion 할때 성능이 가장 좋은지 실험을 통해서 제안해 현재까지도 이 분야에서 많이 인용되고 있습니다.
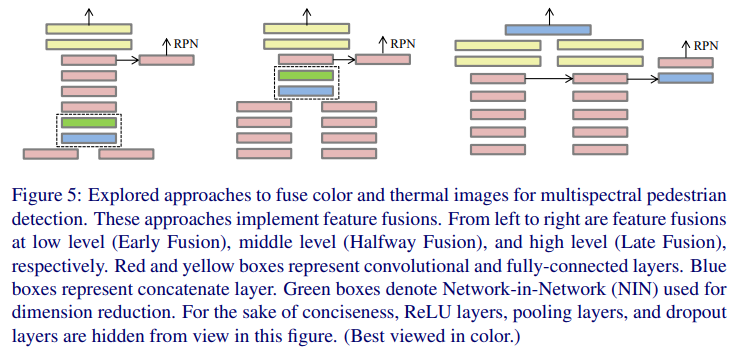
자 그럼 다시 본론으로 돌아와서 .. 제가 오늘 리뷰하는 논문도 Anchor free의 방식인 CSPNet를 이용해 처음으로 Multispectral Dataset를 학습하였습니다. 따라서 본 논문에서도 어떻게 Fusion을 해야하는지에 대해서 다양한 방법과 결과를 리포팅합니다.
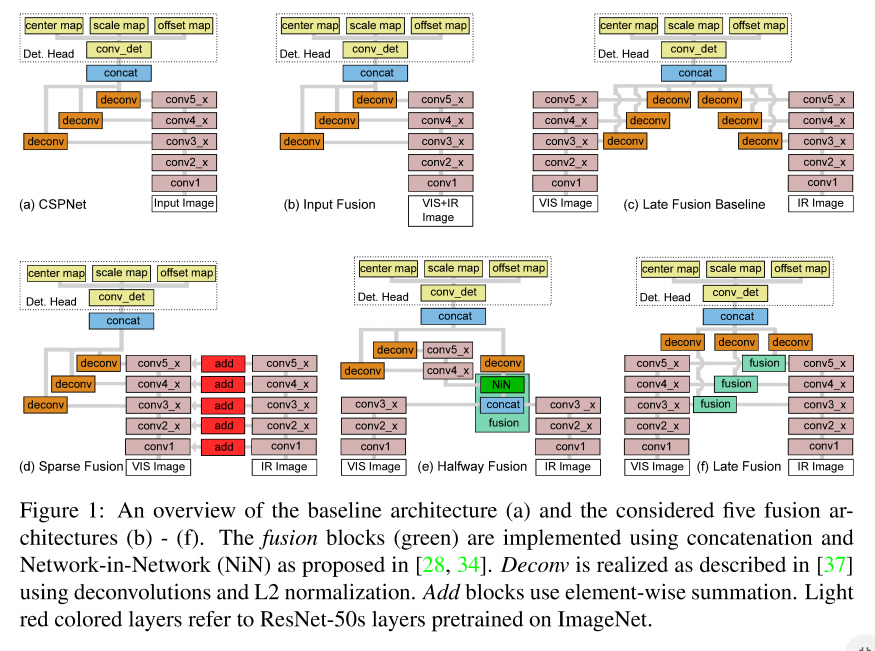
크게 Input Fusion, Late Fusion Baseline, Sparse Fusion, Halfway Fusion, Late Fusion 으로 나뉠 수 있으며 각각은 다음과 같습니다.
Input Fusion : 해당 방법은 RGB와 Thermal을 Channel wise로 Fusion 하는 방법입니다. (논문에서는 두개를 channel wise로 합치면 6채널이 된다는데 아마다 Thermal을 그냥 복제해서 3채널로 만든것 같습니다.) 위 그림에서 (b)에 해당합니다.
Late Fusion Baseline : 해당 방법은 RGB, Thermal 각각에 대해서 Feature Extractor를 수행할 투타워를 만들고, 마지막에 concat으로 feature map을 합치는 방법입니다. 위 그림에서 (c)에 해당합니다.
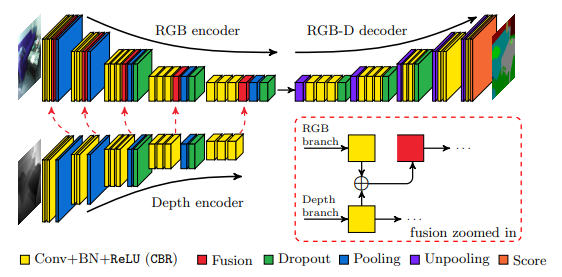
Sparse Fusion : 해당 방법은 FuseNet 에서 제안한 방법으로 FuseNet에서는 Unet을 베이스로 RGB와 D를 합쳤다면, 저자들은 RGB와 Thermal을 합쳤다고 합니다. 밑에 그림은 FuseNet에서 가져온 아키텍처 그림입니다.
(Proposed) Halfway Fusion : 앞서 설명한 딥러닝 기반의 Multispectral Pedestrian Detection을 처음 수행한 논문에서와 같이 본 연구에서도 중간의 피처를 합치는 Halfway Fusion을 수행합니다. (다만 네트워크 베이스가 다르기때문에 앞에 Proposed가 붙습니다) 본 논문에서는 conv3에서 RGB와 Thermal의 Feature를 추출해 Fusion을 수행했다고 합니다. 위의 그림의 (e)와 같습니다.
(Propsoed) Late Fusion : 해당 방법론은 Halfway Fusion과 처음 설명한 Late Fusion의 방법을 결합한 새로운 Late Fusion 입니다. Halfway와 같은 방법으로 conv 3, conv4, conv5 에서 feature map을 추출하고 이를 업샘플링(deconv)하여 마지막에 concat으로 합치는 방법입니다.
본 논문에서는 앞서 설명한 내용과 같이 Anchor Free 인 CSP 아키텍처에서 Multispectral 데이터를 다루기 위해서 다양한 Fusion 방식을 설계하고 실험을 수행하는 동시에 Data Agumentation 방법들도 제안하고 있습니다.
Random Erasing : 해당 방법은 ” Random Erasing Data Augmentation “에서 소개된 방법으로 실제 Object에서 사각형의 모형으로 일부분을 지울경우 모델이 더욱 일반화 되면서 성능을 향상시키는 방법입니다. 본 논문에서도 이를 Multispectral data에 적용하였으며, RGB와 Thermal 동일한 위치를 지우는 방식으로 구현했다고 합니다. 컨셉의 이해를 돕기위해 Random Erasing Data Augmentation 논문에서 아래 그림을 발췌하였습니다.

Proposed Random Masking : 해당 방법은 새로운 방법으로 Random Erasing을 좀 더 발전시킨 방법으로 해당 방법론을 RGB와 Thermal의 랜덤으로 적용하는 방법론 입니다. 50%의 확률로 RGB나 Thermal의 이미지 전체를 0으로 만드는 방법이라고 합니다. (이거 저희가 제안한 FTT랑 완전히 동일한 컨셉이네요)
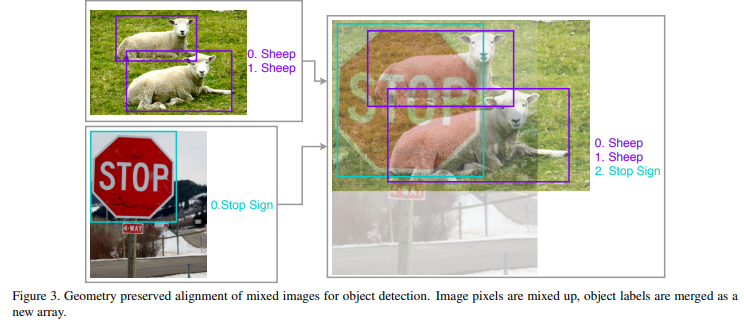
Noise Augmentations : 서로다른 특성을 같는 RGB와 Thermal의 이미지를 섞는 방법입니다. 해당 방법은 ” Bag of Freebies for Training Object Detection Neural Networks ” 에서 제안됐습니다. 이해를 돕기위해 해당 논문에서 사용한 그림을 발췌하였습니다.
자 앞서 설명한 Fusion 방법과 Data Agumentation을 종합하여 실험을 수행하였습니다. 일단 가장먼저 해당 논문에서는 KAIST Multispectral Dataset의 Annotation이 3가지 버전이 있기 때문에 각 버전에 따른 성능을 분석하였습니다.
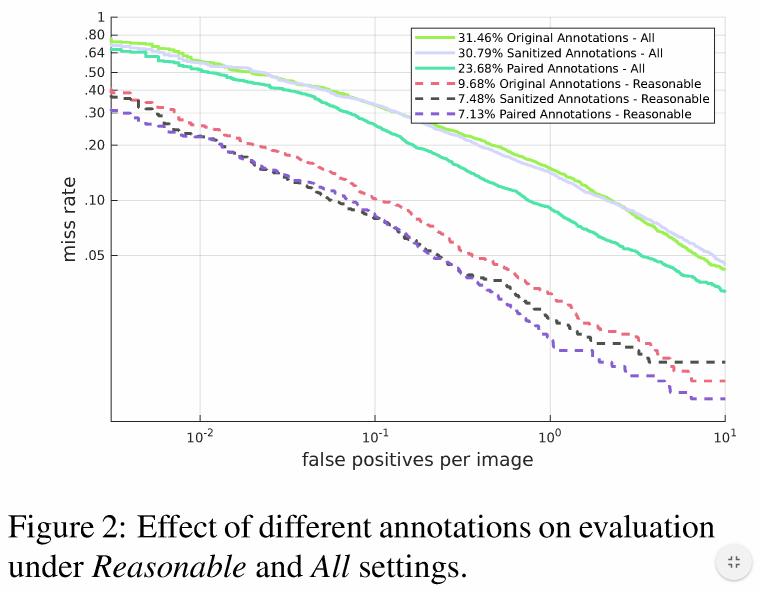
3가지 버전의 Annotation을 비교하였을때 MSDS-RCNN에서 제공하는 Santized Annotation이 가장 좋은 성능을 나타냈는데 이러한 이유로 저자는 해당 Annotation이 small-sclae, heavily occluded를 정확하게 포함하고 있기 때문이라고 합니다. 하지만 저자는 형평성과 하나의 Modality에 오버피팅 되는 것을 피하기 위해서 paired Annotation을 사용했다고 합니다. 이 Paired Annotation을 기준으로 앞서 제안한 방법(Fusion, Data Agumentation)을 적용하여 실험을 수행합니다.
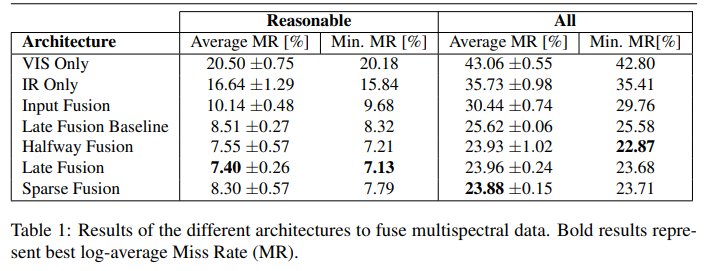
실험결과 본인들이 제안한 Late Fusion(conv3,conv4,conv5에서 feature를 합치고 그걸 deconv로 업샘플링하여 마지막에 합치는 방법)이 가장 좋은 성능을 나타냈다고 합니다. 다음으로는 Agumentation에 따른 성능을 실험합니다.
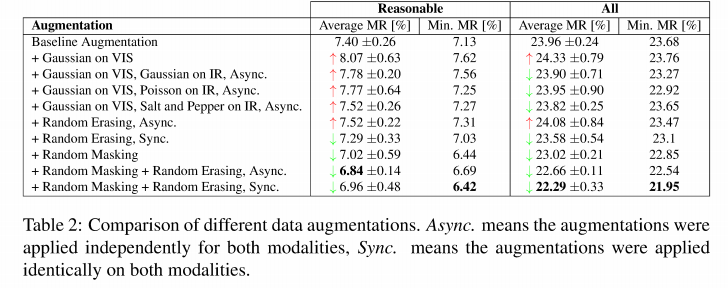
네 그렇습니다 FTT와 동일한 내용인 Random Masking을 사용할때 좋은 성능이 나타났습니다. 이때 Async와 Sync의 차이는 Data agumentation을 독립적으로 적용하면 Async 동시에 적용하면 Sync 입니다.
종합적으로 최종 성능은 다음과 같다고 합니다.
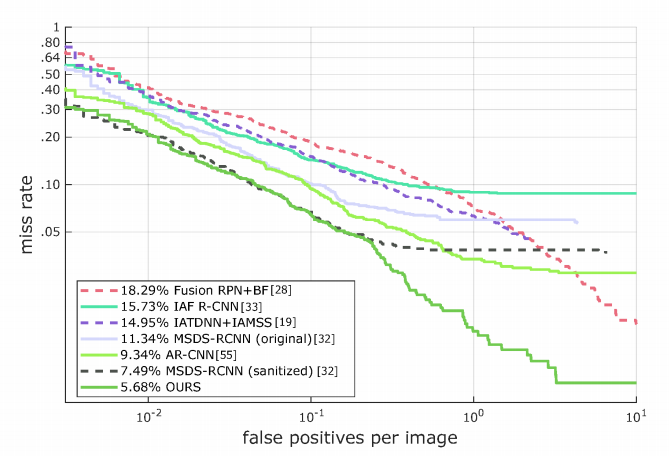
많은 논문들이 성능을 리포팅한 Reasonable에서도 가뿐히 Sota를 달성하였고, (아마 Human baselin이 3퍼였던것 같은데…) 이건 너무 쉬우니 전체 테스트 데이터셋에서의 성능도 Sota를 달성합니다.
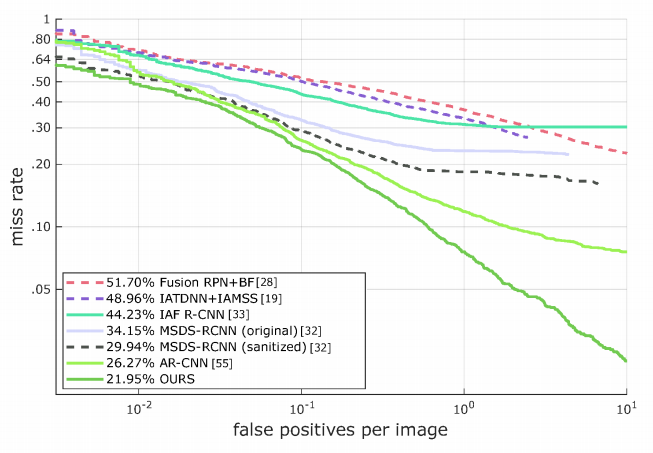
그리고 전체 데이터셋에 대해서 실제 GT Annotation에서 나타난 Pedestrian 크기에 따른 성능도 분석하였습니다.
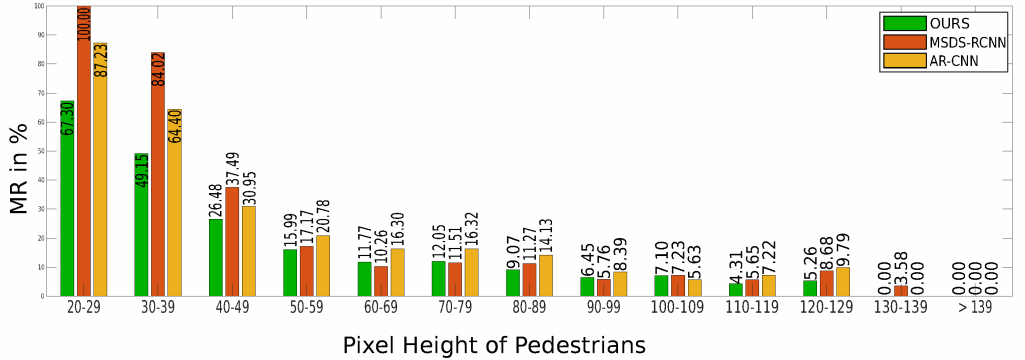
작은 Pedestrian Detection(크기가 작다는건 멀리있다고 생각할수도 있겠죠?)에 대해서도 앞서 제안된 방법론들보다 좋은 성능을 나타냈습니다. (평가지표는 Miss rate 이므로 낮을수록 좋습니다)
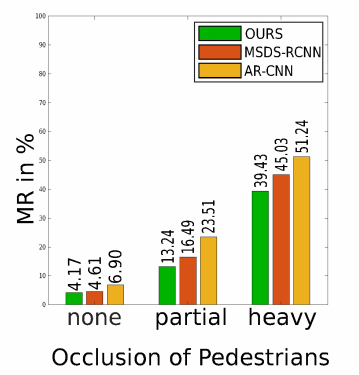
Occlusion에 대해서도 다른 방법론들과 비교해 가장 좋은 성능을 나타냈습니다.
정성적인 결과를 보면 다음과 같습니다.

따라서 본인들의 방법은 압도적이라고 설명하며 논문은 마무리 됩니다.
나만의 결론
나는 왜 4월에 CSP를 리뷰하면서 Multispectral 데이터셋에 이를 적용해 빠르게 결과를 뽑지 않았을까 하는 후회와 더불어 역시 내 생각은(3개의 다른 Annotation이 존재하니 이를 비교하자!)은 이미 실현됐구나 라는 깨달음 그리고 KASIT 데이터셋에서 성능은 이미 휴먼 베이스라인과 비슷해졌으니 성능을 높이는것 이외에 다른 컨셉(하나가 고장나도 강인하게 Fusion할 수 있는 방법..?)으로 고민을 해야겠다고 생각했습니다. 더불어 해당 논문은 20년 8월에 나왔는데… 제가 논문 서베이가 정말 부족했구나 라는 반성도 하게 됐습니다.