SMART논문을 보다가 보게 된 논문이다. 논문을 소개하기 전에 SMART에서 나온 Attention and Relation models에 대해 소개하겠다. (SMART는 지난번 리뷰한 논문으로 링크는 다음과 같다)
1. Attention
attention의 개념은 neural network 는 바람직한 output을 위해 다른 sample들이 어떻게 관계가 되는지를 배운다는 특징에 근거한다. 첫 attention은 action과 gaze의 joint learning 에서 사용되었고, attention은 video에서 봐야하는 부분에 강조를 주는 mask를 생성할 때 사용된다. 다음은 attention 관련 모델 예시이다.
- LRCN (2016)
- Non-local Network (2018)
- relation-net (2018)
- relation attention (2019) -> 이 논문이 해당 페이지에서 소개하는 논문이다!
SMART에서 소개하길 본 논문은 facial expression recognition(FER)을 위한 frame attention networks(FAN)이며 이는 제목에서도 알 수 있다.
본 논문은 다음의 두 가지 모듈로 이루어진다.
- feature embedding module
- frame attention module
- self-attention weight
- relation attention weight
이때 feature embedding module은 face images를 feature vector로 임베딩하는 모듈이고, frame attention module은 attention wight로 self-attention weight, relation attention weight 두가지로 나뉜다.
n개의 프래임을 갖는 비디오를 V라 할떄, 그 프레임을 {I_1,…I_n}, embedding module을 통해 생성된 feature를 {f_1, … ,f_n}이라 할 때, FAN은 feature를 FC layer를 통과시킨 후 sigmoid를 통과시켜 self attention weights α_i를 구한다. α_i = σ(f_i, q0 ) (q0는 FC layer의 파라미터)
이렇게 구한 self attention weight를 통해 global representation f’_v는 아래와 같이 구한다.
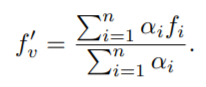
이후, 이를 이용하여 relation-attention weights를 구하는 식은 아래와 같다. (이와같은 수식을 도출하는데 있어서는 다음의 레퍼런스가 달려있다. ) global feature를 이용한다는 점에서 어느정도 non-local block 과 유사점이 있다고 느꼈다 (상단 링크와 같은 링크)
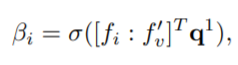
위의 식으로 relation-attention weights를 구한 이후, 이를 통해 구하는 최종 compact feature는 다음과 같다.
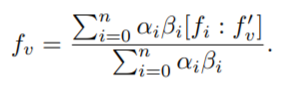
위의 feature를 통해 예측 (happy, sad ..etc)을 진행한다. 위에서 설명한 모델의 아키택쳐는 아래와 같으며 최종 feature인 f_v로 video의 감정분석을 한다.
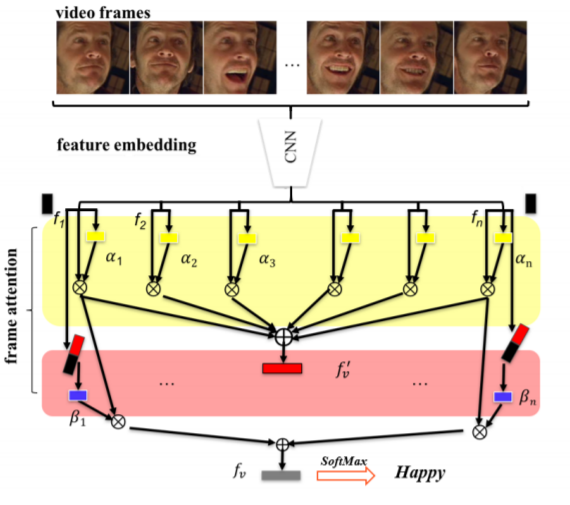
결론으로는 AFEW와 CK+ 데이터셋에 대해 당시의 state-of-art를 달성했다고 한다.
code is available
리뷰 잘읽었습니다.
읽으면서 몇 가지 궁금한 점이 생겼습니다.
1. feature embedding module
비디오 영상을 하나의 global feature로 임베딩하는 부분도 중요하다고 생각합니다. 하지만 리뷰에서 해당 내용이 없어 이해를 하는데 어려움이 있었습니다.
그림을 토대로 이해한 바로는 공유된 CNN 모델에 각 프레임을 넣어 줌으로써 feature를 생성합니다. 해당 feature들을 FC – sigmoid에 넣어 self attention weights를 구하여 CNN으로부터 얻은 feature들을 attention weight sum을 진행 함으로써 global representation 얻는다 로 이해했습니다.
만약에 틀린 부분이 있다면 해당 방법에 대한 참고 논문이나 추가적인 설명 부탁드립니다.
2. Loss
각 attention의 방향성을 정할 Loss도 중요해 보이는데, 어떤 loss로 학습이 되는지 설명 부탁드립니다.
3. output
최종적으로 softmax로 감정이 예측이 되는 것 같습니다. 그럼 마지막 feature는 class 갯수에 맞춰 나와야 한다고 생각합니다. 근데 리뷰 상 수식으로는 최종 feature가 어떻게 클래스 갯수에 맞게 나오는지 모르겠습니다.
혹시 compact feature에 FC layer가 추가로 붙는 형식인가요?
1. feature embedding module
넵 어느정도 맞습니다. global feature를 표현하는 데 있어서 (feature embedding module + frame attention module) 두 모듈을 이용하며 이미지를 feature embedding module 로 feature 표현 후, attention module을 통하여 global feature를 생성합니다.
2. Loss
end-to-end framework로 attention network를 위한 Loss가 따로 있지는 않으며, global feature를 통해 진행되는 classification Loss로 업데이트 됩니다. 즉, 분류 성능이 좋아지는 방향으로 학습합니다.
3. output
넵 맞습니다. 표현된 global feature에 fc layer를 통해 예측을 진행합니다.