본 논문은 Do these Models Really Capture Temporal Information? 라는 질문에 관한 논문이다. 보통 모델이 깊어질수록 낮은 수준의 정보는 점점 사라진다.
아래 그림1은 원본 비디오 (a)와 video를 입력으로 받는 C3D모델의 pool5 feature를 시각화한 이미지(b)이다. 그림1에서 확인할 수 있듯이 (b)의 펀치볼의 움직임 정보를 어느정도 잃었다. 그렇다면 과연 모델은 motion을 보고있는 것일까?
논문은 이를 위해 video로 학습된 모델이 테스트시 한프래임으로 심하게 샘플링된 video에 대해서 classification하면서, 모델이 실제로 motion을 보는지 확인했다고 한다. 즉, 성능의 하락이 정말 (1) motion의 부족때문인지, 아니라면 샘플링을 통해 (2-1)변경된 시간분포와, (2-2) 매우 중요한 프레임을 제거했기 때문인지를 판별하였다.

실험을 위해 motion을 추가하는 Temporal Generator와 Frame Selector 두 framework를 제안한다. 과도하게 샘플링한 Test data에 Temporal Generator와 Frame Selector 를 사용하여 ablation study를 통해 샘플링 후 성능이 낮아지는 이유가 정말 motion의 부족때문인지를 분석하였다.
사용한 Temporal Generator와 Frame Selector 의 정보는 다음과 같다.
1) Temporal Generator & Frame Selector
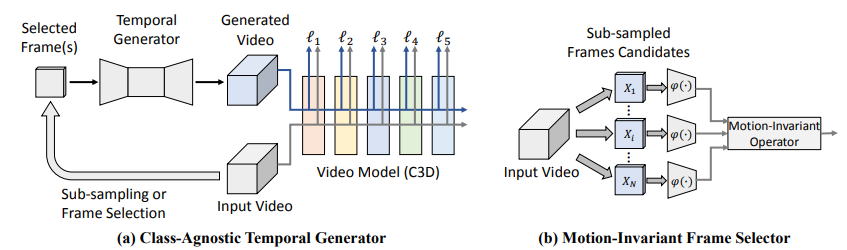
(a)는 cycleGAN을 이용한 video clip Generator이다. video에서 4개의 selected frame이 주어졌을 때 16개의 video clip을 생성하는 모델로, cycleGAN의 장점을 살려 label이 필요없다는 장점이 있다.
(b)는 frame selector 모델로 2가지(Max Response, Oracle)를 이용한다.
먼저. Max Response 는 φ 함수를 이용하여 비디오 V의 프레임들 {xi}를 입력하였을 때 그 응답 i 중 top k개를 선택하는 모델이다 . ({ii}= φ (xi))
(φ 는 predefine 하거나 학습할 수 있다고 한다)
다음으로, Oracle은 Max Response와 같이 valid한 selector는 아니다. 이유는 cheat를 하기때문이다. 즉, video의 class를 미리 알고있을때만 사용가능하다. class를 아는 상태에서 frame selection을 진행하는 것이다. 이는 frame selector의 효과를 측정하기 위해 Upper bound로 사용된다.
2) 실험결과
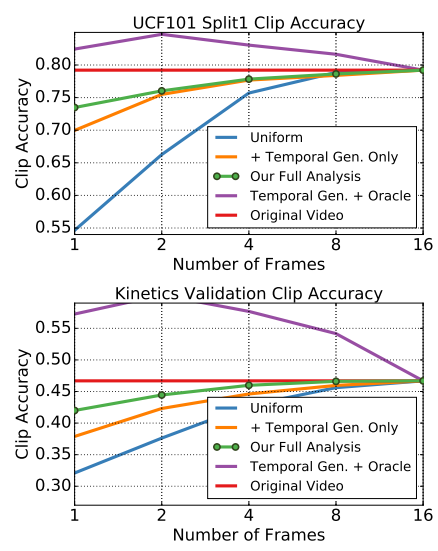
실험은 UCF101데이터셋과 Kinetics data로 진행했으며, 실험은 C3D모델을 이용하였다. Uniform을 base line으로 하고, 초록색은 Temoral GAN + Max Response 라고 한다. Original Video는 참조를 위한 성능이며, Temporal Gen + Oracle 이 상한선의 성능을 보이고있다. 우선 Frame selection이 중요하다는 것은 Oracle selector의 성능으로 확인되었다.
과도한 sampling에 저하된 성능에서 초록색 라인이 상한선에 가장 가깝다. 제안하는 모델이 추가적인 video information과 model의 finetuning없이 높은 성능을 보이고 있다. 이때, Kinetics로 pretrain된 C3D모델이 더 motion에 의존하고 있으며(1frame 이용시 baseline에 비해 UCF101보다 더 많이 하락함) frame selection process에 더 의존적이라 분석하였다.

[ Temporal Generator ] motion을 사용하는 class와 사용하지 않는 class
위 그림2에서 보면 JuggleBall , PushUps과 같이 motion이 중요한 video와 WalkWithDog과 같이 motion이 중요하지 않은 데이터가 있다고 분석한다. 위 그림에서 초록 박스가 sampling으로 선택된 frame이며, Temp. Gen.은 선택된 frame 을 입력으로하여 Temporal Generator 로 생성한 영상이다. 논문에서 그림2의 생성된 이미지를 보며 WalkWithDog 과 같은 class는 생성된 이미지가 정적이며, JuggleBall과 같은 이미지는 모델을 헷갈리게 할 수 있도록 생성되었다고 분석한다.

그림3은 temporal generator 가 동작에 특성에 따라도 잘 동작함을 보인다. 즉, JuggleBall이나 crowdSurfing같은 큰 동작은 움직임이 예상되는 물체의 주변을 크게 환각시켜 모델을 속이고, Yawning이나 PlayFlute과 같은 동작은 미묘하게 action을 생성하는 것을 보인다.