SSD논문을 리뷰 배경
안녕하세요 이번주차는 Object detection의 방법론중 유명한 SSD에 대해서 리뷰하겠습니다. 아마 이번주부터는 Object detection 관련 논문들을 많이 리뷰할거 같습니다. 해당 논문이 object detection에 발을 딛기에 상당히 좋다고 생각합니다. 그 이유는 우선 워낙 유명한 방법론이기 때문에 구글링하면 질좋은 리뷰들이 많습니다. 또한 SSD를 기반으로 만들어진 모델들이 많습니다. 그리고 튜토리얼 코드도 공개된게 많습니다.
논문을 읽기에 앞서 해당 유튜브영상을 봤습니다. SSD에 관해 리뷰한 영상인데 한글로 되어있습니다. 항상 느끼는게 떠먹여주는 자료가 있으면 최대한 활용하는게 좋다고 생각합니다. 그래서 일단 블로그와 유튜브영상으로 기본을 잡은 상태로 튜토리얼코드를 돌려보고 논문을 읽어서 디테일함을 채워가는 식으로 학습목표를 잡았습니다.
구글링을 조금만 해도 많은 자료가 나왔지만, 대표적으로 여기에 설명이 잘 되어있었습니다. SSD가 어느정도로 유명한 논문인지 체감이 되었습니다.
튜토리얼 코드 결과

튜토리얼 코드는 세미나에서 언급했듯이 위와같은 문제점들을 제외하고는 잘 작동하였습니다. 혹시라도 튜토리얼코드를 돌려보고 싶으신 분들을 위해 사진을 첨부하였습니다.
이후 서버에서 돌렸던 튜토리얼 코드를 코랩환경에서 돌려보았습니다. 그 과정중 생긴 문제점들은 다음과 같습니다.
- create_data_lists.py 파일을 실행하면 이미지경로가 저장된 json 파일들이
만들어지나 실행이 안되는듯함 (서버에서 10초면 되는데 코랩에선 30분넘
게 돌려도 무반응이길래 꺼버렸음)
→ 서버에서 json파일 만들어온 후 경로를 코랩 환경에 맞게 바꾸어
준 후 업로드하여 해결 - 코랩 노트북에서 !cd 로 경로를 바꿔도 !pwd하면 경로가 계속 초기화되어
있음, 코랩내의 터미널로 실행하면 랙이 심함
→ !cd /content/drive/MyDrive/SSD_tutorial/ && python train.py 이
런식으로 py파일 실행하여 해결
데이터셋은 공유된 구글드라이브 폴더를 사용하였고, 동일한 코드를 일반코랩과 코랩pro버전에서 돌려보았습니다. 그 결과 일반코랩에선 배치사이즈4에서 out of memory가 떴고, 코랩프로버전에선 배치사이즈8로도 잘 돌아갔습니다. 속도적인면에서도 프로코랩이 2.15배정도 더 빨랐습니다.
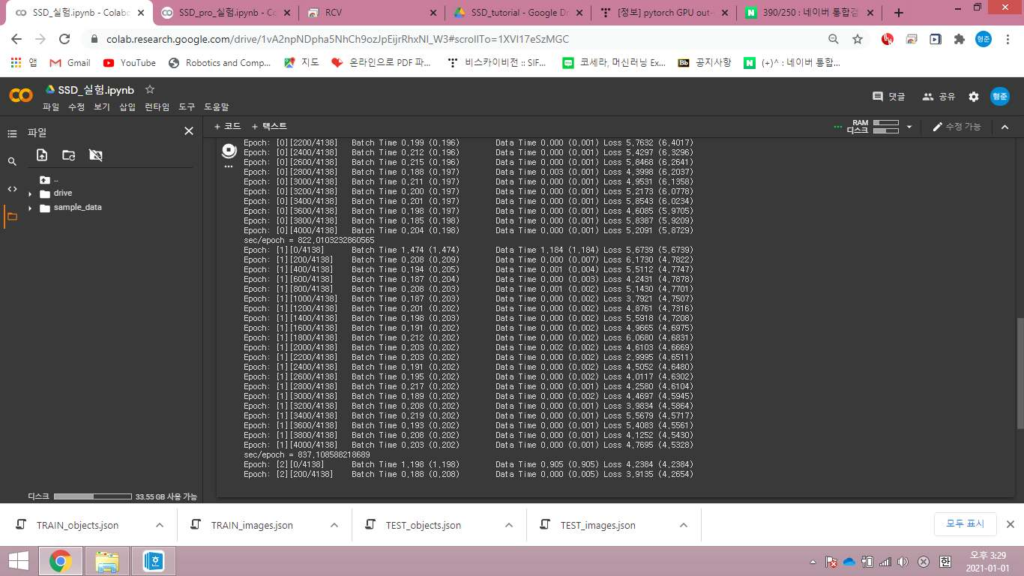
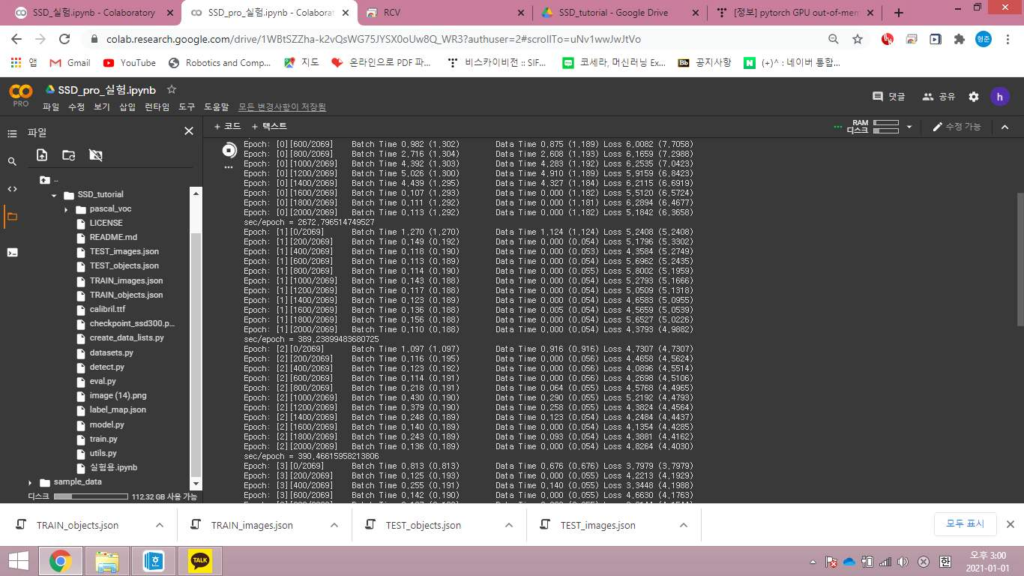
Default 세팅으로 학습시키는데 일반코랩에서는 약 55시간 내외, 프로코랩에서는 24시간 내외가 소요될것으로 추정됩니다.
주말내내 학습시킨결과 코랩일반버전에서는 GPU사용시간을 초과해서 도중에 학습이 중단되었습니다. 프로버전에서는 180에포크정도 까지 돌다가 학습이 멈췄습니다. (런타임끊김 방지로 해결 가능할 것으로 보입니다.)
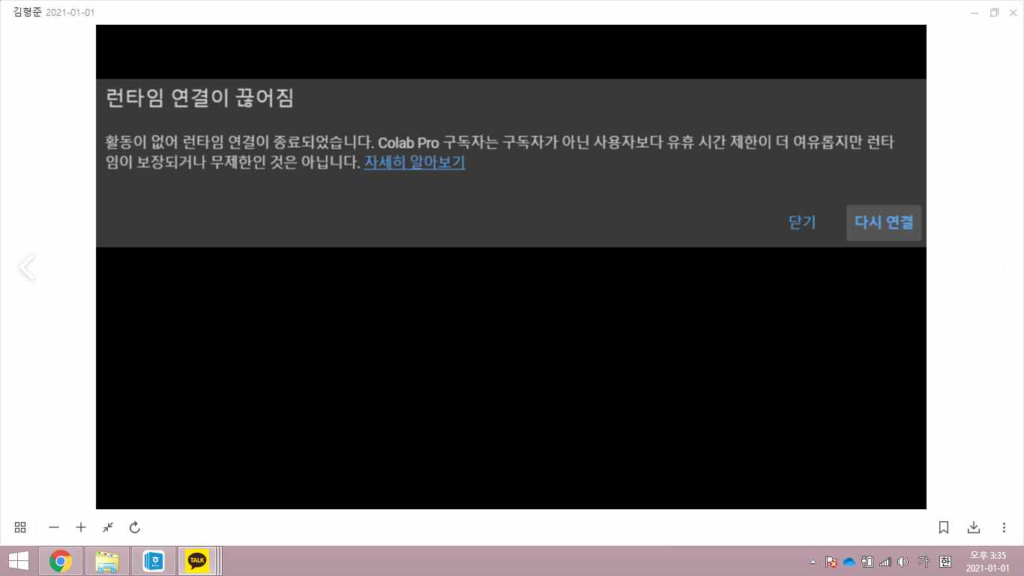
해당사진은 코랩프로도 런타임이 끊기기는 한다는 것을 보여줍니다. 확실히 일반코랩보단 그 주기가 더 길었습니다.
Object detection과 SSD
Object detection이란 classification과 localization을 동시에 하는 것을 의미합니다. 이미지가 있으면 물체가 어딨는지를 나타내는 bounding box를 찾고 해당 bounding box 내에 있는 물체의 라벨을 classification문제로 찾습니다.
이런 Object detection은 아래와같이 두가지로 나눠지게 됩니다.
- One-stage
- Two stage(many stage)
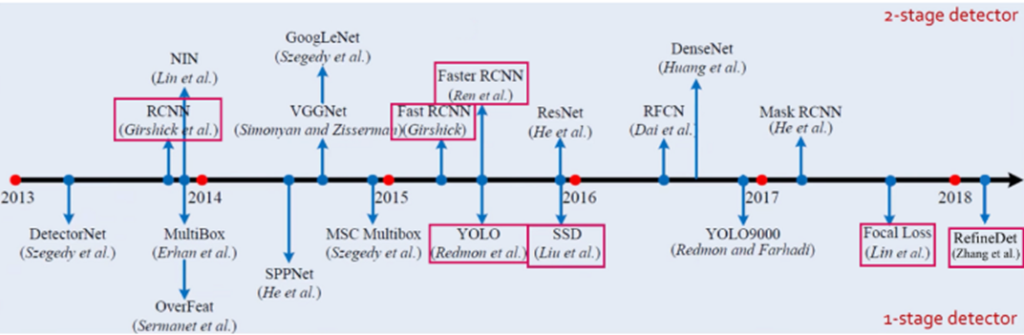
그중에서도 SSD는 대표적인 1 stage detector입니다. 또다른 대표적인 one stage detector는 YOLO가 있습니다. 대부분의 1 stage detector들은 YOLO나 SSD를 기반으로 하고 있습니다. 일반적으로 One stage detector는 2 stage detector에 비해 속도가 빠르나 정확도가 더 떨어지는 경향이 있습니다.
SSD 이전에 나온 one stage detector인 YOLO는 Faster-RCNN에 비해 훨씬 빠른속도를 가지나 정확도면에서 한계가 있었습니다. SSD는 속도도 빠르며 성능도 2-stage detector에 크게 뒤지지 않는 것을 목표로 합니다. 결과론적으로 SSD는 속도와 정확도 두마리 토끼를 잡는데 성공합니다. 그리고 이후에 one-stage detector는 SSD기반으로 만들어진게 많습니다.
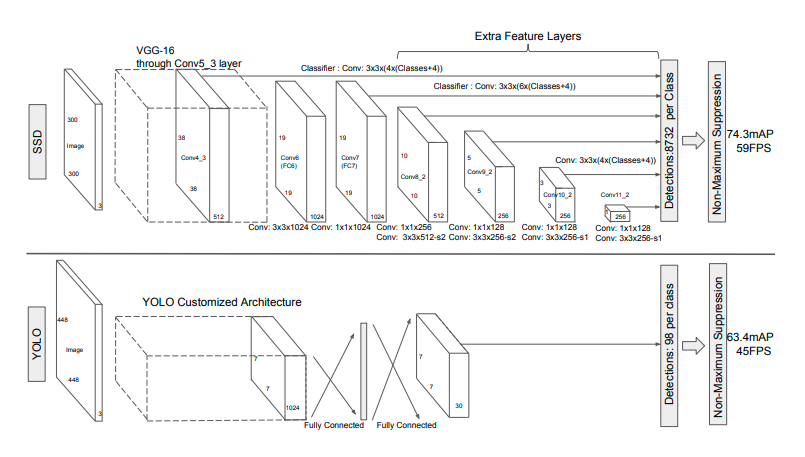

그럼 이제 본격적으로 논문에서 나온 SSD 그림과 VGG16 그림을 통해 설명을 이어가보겠습니다. 먼저 입력은 300*300 혹은 500*500으로 받습니다. ImageNet에서 pretrained된 VGG16을 베이스 네트워크로 사용하였습니다. 이는 SSD가 개발될 당시에 VGG16이 해당 task에 좋은 성능을 보였기 때문입니다. VGG-16의 Conv layer를 1-1~5-3까지 사용하였고 뒤에 dense layer제거한 후 추가적인 conv layer 들을 사용하였습니다.
conv layer들은 stride를 증가시켜 feature map을 점점 작게 뽑아내게끔 설계되어 있습니다. feature map의 사이즈를 작게하는 방법에는 여러가지 방법이 있지만 해당논문에서는 stride를 늘리는 방법을 택하였고 일반적으로 많이 사용되는 방법입니다. SSD의 가장 큰 특징인 이렇게 중간중간에서 추출된 feature map들을 활용하는데 있습니다. 이러한 방법은 OD나 segmentation에서 많이 사용되는 방법입니다. 하지만 이때 당시만해도 feature map의 사이즈를 다르게해서 뽑아내는 형식의 방법론은 획기적이었습니다. 아래에서는 논문에서처럼 욜로와 비교하는 위주로 서술을 이어가겠습니다.
인풋이미지가 300*300 일때를 기준으로 총 8732개의 bounding box가 뽑히게됩니다. 500*500에서는 24564개로 더 늘어나게됩니다. 굉장히 많이 뽑는것을 알 수 있습니다. 이는 욜로에서 bounding box를 98개만 사용하는데 비하면 엄청나게 큰 숫자입니다.
욜로는 FC layer를 사용하였기 때문에 이미지 전체에대한 정보를 동시에 볼 수 있고, SSD는 conv layer만을 사용하여 지역적인 특성에 좀 더 초점을 맞추었습니다.
그렇다면 이번에는 한개의 feature map에서 어떠한 정보들을 추출하는지 좀 더 디테일하게 보겠습니다.
먼저 bounding box의 위치를 나타내는 값은 x, y, w, h로 총 4개가 필요합니다. 그리고 class가 어디에 속하는지 classification 하려면 class의 갯수만큼의 변수가 또 필요하게됩니다.
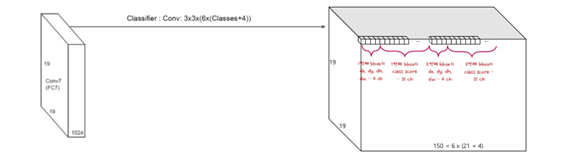
즉 위와같은 그림처럼 feature map이 뽑히게 됩니다. 좀 더 이해를 돕기위해 pascal VOC를 기준으로 설명 하겠습니다. pascal VOC는 20개의 class label과 background로 나뉘게 됩니다. 즉 총 21개의 class를 갖습니다. bounding box를 6개씩 뽑아낸다고 했을때, 총 6*(21+4)=150개씩의 정보를 가집니다. 이때 6은 bounding box의 갯수이고, 21은 class의 갯수, 4는 bouding box의 위치정보입니다. 즉, 3*3 convolution을 할때 chanel을 150으로 설정하면 각 location마다 해당 정보(bounding box좌표, class마다 확률)들을 담고있는 150개의 채널의 feaure맵이 나오게됩니다.
위에서 설명한 연산을 통해 모든 location에 대해 각 6개씩의 bounding box를 뽑고 각 label마다의 확률값을 뽑아왔습니다. 그럼 이제 이 뽑아온 정보를 어떤식으로 가공해야하는지 알아볼 차례입니다. 이때 사용되는 개념이 IoU입니다.
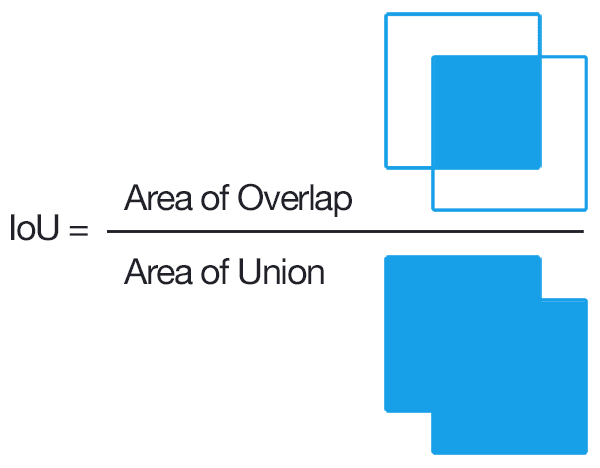
IoU는 다들 아시다시피 위와같이 정의됩니다. 쉽게 말해서 이미지가 얼마나 겹치냐를 나타내주는 척도입니다. 위에서 bounding box의 좌표와 class마다 속할 확률을 담고있는 feature map을 뽑아왔습니다. 이제 그 bounding box들 중에서 IoU가 일정 threshold를 넘는 녀석들을 골라내야합니다. 이때 IoU는 사전에 annotation한 GT정보와 비교하여 구합니다.
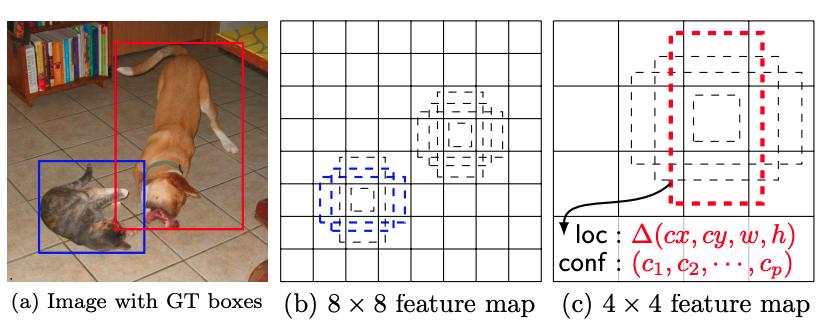
또한 SSD 에서는 default box개념을 사용합니다. 이 부분이 좀 독특했는데 bounding box를 default값으로 뽑아낸다음에 얼마만큼 bounding box를 재위치 시켜야 하는지를 loss로 설계하여 최적화를 진행합니다. feature map의 사이즈를 줄여가며 feature를 추출하기 때문에 뒤로갈수록 1개의 feature가 담고있는 정보는 더 커지게됩니다. 그렇기 때문에 작은물체들은 앞부분의 conv layer를 통해 추출된 feature map에서 검출이되고 큰 물체들은 뒤에서 검출이 됩니다. 기본적으로 YOLO에 비해 훨씬 더 많은 bounding box를 뽑기 때문에 더 정확도가 높아지게 되는 것입니다.
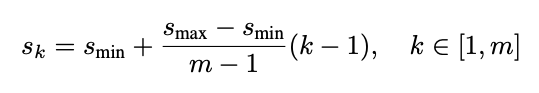
bounding box는 위와같은 식에 의해서 만들어지게됩니다. 복잡해보이지만, 해당 식에서 k만이 변수이고 나머지는 상수입니다. m은 feature map을 몇번을 뽑는지를 나타내고 SSD에서는 6입니다. s_min은 0.2, s_max는 0.9입니다. feature map마다의 s_k는 0.1, 0.2, 0.375, 0.55, 0.725, 0.9입니다. 300*300의 input image가 들어갔다고 했을때 s_k가 0.1이면 30*30을 의미합니다. 즉 얼마만큼 scale이 되었는지를 나타내는 지표이고 이는 bounding box를 만드는데 사용됩니다.
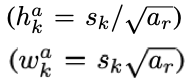
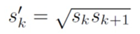
scale을 정한 후에는 aspect ratio를 위와 같은 공식으로 정하게됩니다. 이때 a_r은 (1, 2, 3, 1/2, 1/3) 중 한개의 숫자입니다. 다만 예외적으로 aspect ratio가 1일때는 s_k프라임 값을 추가적으로 사용합니다. 이렇게 최대 6개의 default box가 만들어집니다. default box를 4개만 사용할때는 3이랑 1/3이 빠진 값들을 사용합니다.
Hard Negative Mining
Class imbalance문제를 해결하기위한 방법으로 hard negative mining 방법을 사용합니다. SSD에서는 bounding box를 8000개 넘게 뽑아내는데, 예를들어 이중 30개 만이 일정 threshold IoU를 넘었다고 해봅시다. 정작 쓸모있는 정보는 30개 뿐인데 나머지 8000개는 쓸모없는 Background에 대한 정보를 담게됩니다. 이는 심각한 imbalance문제를 초래할 수 있습니다. 욜로에서는 confidence를 fast-RCNN에서는 region proposal net을 사용하여 한번 걸러주는 역할을 하여 해당 문제를 해결합니다. 이와 비슷하게 SSD에서는 hard negative mining 기법을 사용하여 imbalance문제를 해결합니다.
즉, background에서 뽑아낸 loss를 모두 사용하는것이 아닌 negative(필요없는 loss)를 mining(발굴)해서 없애는 것 입니다. 이를 위해 loss가 큰 순서대로 sorting을 합니다. 이때, loss가 크다는 것은 background인데 background일 확률이 작게 나온 경우를 의미합니다. 그리고 그 sorting된 값들중 높은순서대로 positive example의 3배만을 학습에 사용합니다.
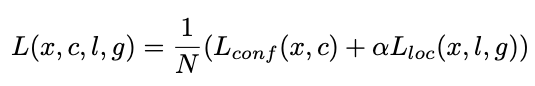
먼저 N은 match된 bounding box들의 개수입니다. N이 전체가 아닌이유는 hard negative mining에 의해 negative sample들이 학습에서 제거되었기 때문입니다. L_conf는 classification loss이고 loc는 localization loss입니다.
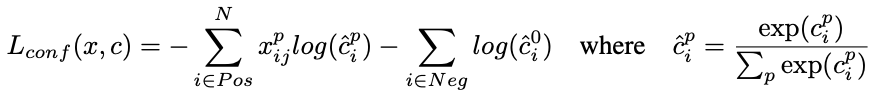
classification loss는 잘 아시는 cross entropy loss입니다. 해당 내용에 대해서는 아래에 좀 더 자세히 다루었습니다.
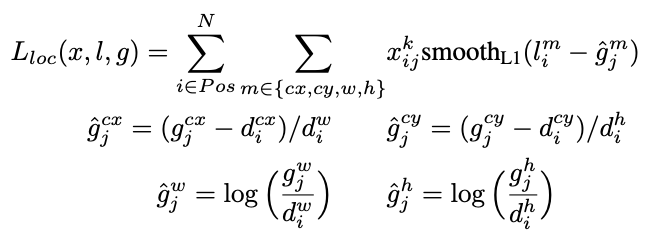
localization을 하는 과정에서의 loss는 좀 독특합니다. 위에서 소개한 default bounding box의 개념을 각 feature map마다 적용하였고, 일정 IoU를 넘은 bounding box들에 대해서 위치를 미세조정 해주기 방향으로 학습을 합니다. 따라서 loss도 이같은 방향으로 학습을 하도록 설계되었습니다. GT box와 얼마나 차이가 나는지가 loss가 되며 g는 GT값이고 d는 학습되어야하는 변수입니다. 이때 bounding box의 x, y는 width 와 height의 비율로 따지게됩니다. 그리고 w와 h는 log 스케일로 되어있습니다. 이때 log 스케일을 도입한 이유는 w와 h는 변화폭이 크기 때문입니다.
정량적 평가
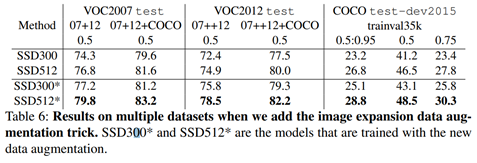
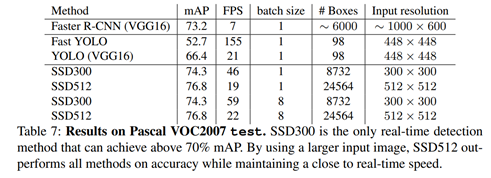
정량적인 결과입니다. 사실상… 이미 수많은 사람들에 의해 검증된 work이라 정량적인 성능을 자세하게 뜯어보는 것은 큰 의미가 없다고 생각합니다. 그렇지만 기존 work중 하나인 YOLO 처럼 빠르고 Faster R-CNN의 accuracy를 따라갔다는 정도로 의미파악을 하면 될거같습니다.
이상 리뷰 읽어주셔서 감사합니다.
댓글에 Data augmentation 이야기가 나와 내용을 추가합니다.
Data Augmentation
신정민 연구원님이 지적해준신거 처럼 data augmentation이 좀 특이하고 성능에도 영향을 많이 미쳤습니다. 그래서 기왕 리뷰하는거 포함하는게 좋을거같아서 추가했습니다. 아래 글에서 0.5의 확률이란 50%의 확률을 의미합니다. (할푼리)
- original input image를 사용
- Object와 오버랩되는 부분이 0.1, 0.3, 0.5, 0.7, 0.9 이상이 되도록 crop하여 사용
- Random sample patch사용
- 각각의 sample patch의 사이즈를 오리지널 이미지의 [0~1 , 1]로 사용
- 1/2와 2 사이의 aspect ratio사용
- 0.5 확률로 horizontal flip 사용
즉, 오리지날 이미지를 쓰기도하고, crop하여 쓰기도하고 horizontal flip을 적용하기도 했습니다. Crop할때 crop할 영역은 최소IoU를 정하기도하고 aspect ratio, scale등을 바꿔가며 했습니다
상당히 꼼꼼한 리뷰글 잘 읽었습니다.
튜토리얼 코드도 돌려보셨고, 이론 내용도 자세히 작성하셨으니이론 내용에 대응되는 코드도 같이 보여주셨으면 하는 아쉬움이 살짝 있네요ㅎㅎ.. 그리고 리뷰에 성능지표를 2개 올려주셨는데 data augmentation에 따른 성능의 차이가 제법 커 보입니다. 해당 data augmentation 방식은 무엇이고 이는 기존의 SSD의 어떤 단점을 보완한 것일까요?
해당 내용을 댓글로 작성하기엔 내용이 많아서 글 내용에 추가했습니다! 아주 날카로운 지적 감사합니다.