이번 논문은 GAN 기반의 Colorization 방법론인 SCGAN에 대해서 리뷰하고자 합니다.
Introduction
Colorization의 성능이 나날이 좋아지고는 있지만, 아직까지도 다음과 같은 어려운 점들이 존재합니다.
- Semantic confusion
- color bleeding
- edge distortion
- object intervention
Semantic confusion은 영상 속에 존재하는 각각의 물체들에게 어떤 색을 입혀야하는지? 에대한 문제이며, color bleeding에 경우에는 물체 경계 너머로 색상이 입혀지는 즉 번지는 현상을 의미합니다.

2번째와 3번째 row는 기존의 colorization 방법론으로 만들어낸 영상으로 부분부분 하자가 있는 것을 확인할 수 있습니다.
예를 들어 첫번째 column에서는 군중들의 색상이 나무의 색상에 영향을 받아 번진 것을 확인할 수 있으며, 4번째 column에서는 도로와 사람의 얼굴이 파란색으로 colorized 된 것을 확인할 수 있습니다.
이러한 문제들을 해결하고자 영상의 변화(gradient)나 segmentation을 이용한 regularization term을 두어 학습을 하는 방법론들이 제안되었으나, 이들 역시도 몇몇 상황에서는 큰 효과를 발휘하지는 못했다고 합니다.
그 이유는 영상의 변화도가 실제로 의미있는 정보를 담고 있지 않는 경우들이 존재하며, segmentation의 경우에는 colorization network가 유사한 경계를 가지는 물체에 대해서 color를 입히는데 많은 어려움이 존재했다고 합니다. (예를 들어 나무들의 경계랑 군중들의 경계면이 유사하게 생겨 군중들을 나무로 착각하여 초록색상을 입히는 등..)
또한 추가적으로 segmentation의 경우에는 segmentation gt를 가지는 데이터 셋이 적다보니 학습할 데이터 셋을 찾는데도 제약이 어느정도 있습니다.
그래서 이번 논문에서는 saliency map을 이용해서 위에 언급한 문제들을 해결해보고자 합니다. 먼저 saliency map을 사용했을 경우 3가지의 이점을 얻을 수 있습니다.
- 영상 내 지각적으로 상당히 중요한 영역을 구분할 수 있다.
- 픽셀 단위에서 물체의 localize를 수행할 수 있다.
- saliency map은 영상 내 다른 물체들에 다 적용할 수 있으므로, multiple dataset에서 사용할 수 있다.
먼저 첫번째 이점에 대해서 설명을 드리자면, colorization 성공의 핵심은 배경의 영향을 최소한으로 받으면서 동시에 object에 대해서는 더 집중적으로 봐야합니다.
왜냐하면 주로 영상 속 주요 물체는 색감이 풍부한 반면에, 배경은 파랑, 초록, 회색 같은 단색들이 대부분이기 때문입니다. (예를 들어 하늘은 온통 하늘색, 나무는 초록색, 도로는 회색 등등)
이러한 배경들과 주요 물체를 구분하지 않으면 주요 물체에 대한 풍부한 색감들을 전혀 예측하지 못하고 배경색에 영향을 받아 색이 퍼지는 현상이 발생합니다.
그래서 지난번에 작성한 Instance aware Colorization 역시 이러한 관점에서 Detection model을 이용하여 배경과 object를 따로 구분하여 colorization을 함으로써 성능을 높이고자 했었죠.
마찬가지로 해당 논문에서는 saliency map을 이용해서 배경과 주요 물체를 구분함으로써 배경의 영향력을 줄이고 특정 색상으로 편향되는 것을 막고자 하였습니다.
두번째 이점은 saliency map을 통하여 배경과 물체에 대하여 상대적으로 명확한 경계를 구분지음으로써 colorization network가 색상을 깨끗하게 입히도록 도와준다고 합니다. 즉 color bleeding 현상이 줄어든다는 것이죠?
마지막 이점에 대해서는 말 그대로 saliency map은 dataset의 제약이 없기에 다양한 데이터 셋에서 사용할 수 있다는 것 입니다.
그럼 전체적인 Contribution에 대해서 설명하고 바로 본론으로 넘어가겠습니다.
- pre-trained VGG-Net을 통해 semantic information을 추출함으로써 유사한 edge를 가지는 물체들에 대하여 사실적인 색상을 구분할 수 있게 합니다.
- decoder는 크게 colorization과 saliency map을 추정하는 2개의 branch로 나뉘어져 있으며 이 2개의 output을 곱함으로써, 그림 2와 같은 salient areas를 구합니다.
- 2개의 discriminator들은 전체 영상과 weighted 영상(salient areas)에 대하여 평가를 진행하며 이러한 adversarial training 기법을 통해 영상과 색상의 선명도를 확보하였습니다.

SCGAN Architecture
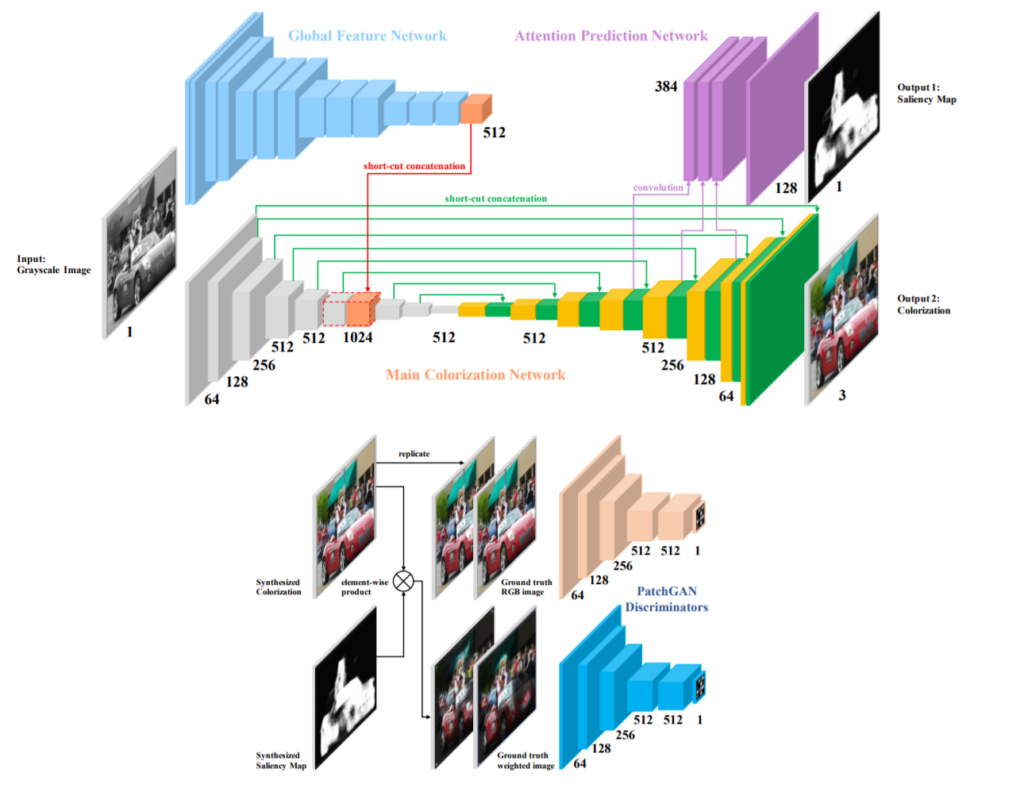
일단 SCGAN은 계층적 GAN 구조를 가지고 있으며 해당 GAN은 graysale image를 입력으로하여 colorization과 salieny map을 생산합니다.
전체적인 구조는 총 4개의 파트로 이루어져있는데, 바로 global feature encoder, main colorization network, saliency prediction network, 그리고 patch-based discriminator입니다.
먼저 Generator부터 살펴보시죠. generator는 위에서 말한 4개의 part 중 3개(global feature encoder, main colorization network, saliency prediction network)로 이루어져 있습니다.
Global feature encoder는 VGG-16-Gray 네트워크를 사용하였으며, 모든 max pooling은 stride값이 2인 컨볼루션 레이어로 대체하였습니다.
반면에 main colorization network의 경우에는 U-Net을 사용하였으며, encoder와 decoder 간에 skip connection을 사용합니다. 이를 통해 gradient vanishment와 accelerates convergence 문제를 완화하였습니다.
Global information과 local low level information을 결합하기 위해서, global feature encoder의 마지막 레이어와 main colorization network의 middle layer를 합쳤으며, decoder 부분에서 3개의 레이어를 추가하여 colorization과 동일한 resolution을 가지는 saliency map을 만들었다고 합니다.
다음은 Discriminator입니다. Discriminator는 위에서도 설명드렸다시피 2개 존재하는데, 이 두개의 discriminator는 모두 PatchGAN의 구조를 사용합니다. PatchGAN은 local image patch에서 high-frequency correctness의 강점을 보이고 Markov random field에 효율적인 모델이라고 합니다.
먼저 첫번째 Discriminator는 colorized image와 GT image(RGB image)를 판단하는 역할을 수행합니다.
두번째 Discriminator는 weighted image와 GT weighted image를 판단하는 모델로, weighted image의 경우 colorized image와 saliency map간에 element-wise product를 통해 만들 수 있습니다. GT weighted image 역시 동일하게 GT 영상과 saliency map을 elementwise 하여 구할 수 있습니다.
해당 논문에서는 PatchGAN의 patch size를 70 × 70으로 설정하였다고 합니다.
Attention Mechanism and Training Schedule
Saliency map은 흔히 영상에서 시각적으로 이목이 끌리는 지역을 표현하는데 많이 사용됩니다. 이러한 관점에서, 저자는 이러한 salient areas에 더 많은 색상 패턴과 더 큰 분산을 가지고 있을 것이라고 판단하였습니다. 이러한 큰 분산은 colorization 네트워크가 rare color들에 대하여 더 자세히 보고 학습할 수 있게끔 하는 중요한 값을 의미합니다.
이러한 지역들을 강조하기 위해, 저자는 colorful image와 saliency map을 element-wise product하는 방식을 제안합니다. 이를 통해 만들어지는 weighted image는 풍부한 색을 가진 지역들을 포함하였으며 반면에 배경과 같은 flatten region들은 모두 필터링해버렸습니다.
추가적인 attention loss를 적용하기 위해, 수식(2)와 같이 loss를 설계함으로써 saliency prediction network를 통하여 main colorization network가 해당 네트워크의 bottom layer를 조정하는데 도움을 주도록 하였습니다.
GAN Architecture는 매우 비선형적이기 때문에 random initialization이 local minima로 이끄는 경향이 강합니다. 이러한 문제를 완화시키기 위해, 저자는 학습 방식을 2단계로 나누었습니다.
먼저 첫번째 단계에서는, SCGAN의 generator만을 L1 loss로 학습시킵니다. L1 loss를 통해 outlier를 제거할 수 있으며, 이는 L2 loss보다 더 나은 생성 결과를 보여준다고 합니다.
이를 통해 generator와 discriminator간에 밸런싱 패치를 함으로써 안정적인 adversarial 학습 과정을 계속 유지할 수 있다고 합니다.
두번째 단계에서는, 전체 generator와 discriminator를 번갈아 학습함으로써 전체 SCGAN을 학습시킵니다. 참고로, saliency map 기반의 지도 방법은 1단계와 2단계 학습 방법 모두 적용됩니다.
Loss
첫번째 학습 단계에서는 위에서 설명드렸다시피 L1 loss를 사용합니다. L1 loss는 colorized image와 weighted image 모두한테 사용되며 이를 통해 생성된 영상들의 픽셀들간에 유사성과 인지적으로 중요한 지역들 모두에 대해 강조하게 됩니다.
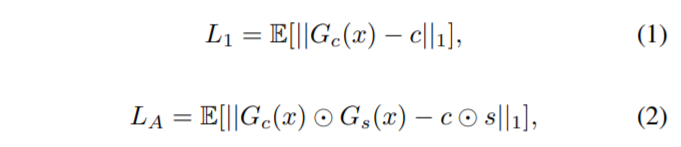
x는 gray image, s는 saliency map, c는 color image를 의미합니다. ⊙는 element-wise product을 나타내며 G_{c}, G_{s}는 각각 color와 saliency map을 생성하는 generator를 의미합니다.
두번째 학습 단계에서는 generator뿐만 아니라 discriminator도 학습해야하니 loss가 위에보단 복잡해보이지만 사실 간단합니다.
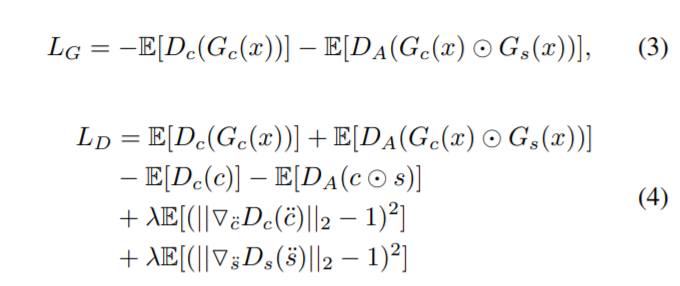
먼저 식 3과 식4의 4개의 term은 original WGAN loss입니다.
\ddot{c}, \ddot{s}는 합성된 color와 saliency 영상들과 gt color, saliency 영상들로부터 샘플링된 포인트 쌍들 사이의 직선을 따라 균일하게 샘플링 된 값들이라고 논문에선 나와있는데 이게 무슨 소리인지는 잘 모르겠네요?
람다는 gradient penalty 상수로 10의 값을 가진다고 합니다.
지각적인 품질을 향상시키기 위해서, 저자는 high-level feature space 속 semantic similarity를 추정하고자 perceptual loss를 추가로 제안하였습니다.
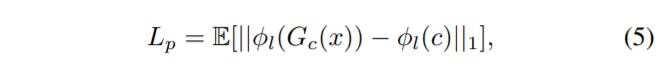
\phi_{l}(*)는 pre-traiend network의 l-th layer의 feature를 의미합니다. 해당 논문에서는 ImageNet으로 pre-trained된 VGG-16 network 중 ReLU가 적용된 conv_{3\_3}을 사용했다고 하네용.
이를 통해 generator의 total loss는 식 (1), (2), (3), (5)를 합친 아래 loss가 됩니다.
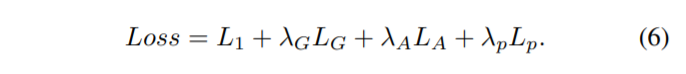
Experiment
먼저 실험에 사용된 데이터 셋은 만장의 ImageNet validation dataset을 사용하였습니다. 만장은 랜덤하게 선택되었으며 ImageNet 카테고리에 균형이 잘 맞게끔 구성되어있다고 합니다.
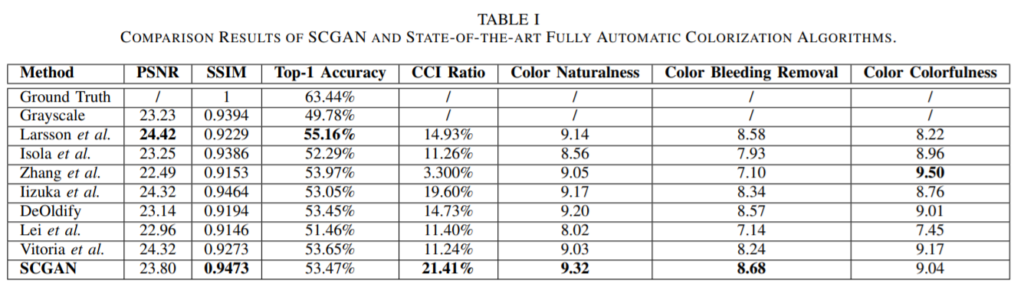
먼저 영상품질 평가 메트릭으로 가장 기본적인 PSNR과 SSIM뿐 만아니라, ImageNet으로 학습된 VGG16에 변환된 color image를 넣었을 때 분류 성능 결과 및 다양한 결과 표들이 나와있습니다.
PSNR의 경우 다른 기법들에 비해 밀리는 모습을 보이기는 하지만, PSNR은 인간의 시각 체계와 큰 연관이 없는, 단순히 영상 처리 및 복원 관점에서의 평가 지표이기 때문에 비중있게 보고있지 않고 있습니다.
SSIM 같은 경우에는 luminance, contrast, structure 등을 토대로 평가를 하기 때문에 PSNR에 비해 상대적으로 colorization이 잘 됐는지 안됐는지를 살펴볼 수 있는 지표로 사용될 수 있습니다.
CCI Ratio의 경우 색상이 얼마나 shift 됐으며 어느정도의 saturation level을 지니는지에 대하여 초점을 둔 평가 방식이라고 합니다.
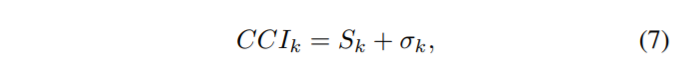
S_{k}는 k번째 영상의 평균 saturation 값을 의미하며 세타는 표준편차를 의미합니다. CCI는 0(achromatic image)~무한대(most colorful image)의 범위를 지니고 있으나 생성된 컬러 영상에 대한 CCI값의 optimal 범위는 16~20정도 입니다.
이를 인간의 지각 능력과의 상관관계로 나타내면 95.3%라고 합니다. 인간의 시각 체계는 반대되는 색상 영역 안에서 색상 정보를 포착하기 때문에, CCI를 계산하기 위해서는 RGB image를 먼저 반대되는 색상 영역으로 변환시켜주어야 합니다.
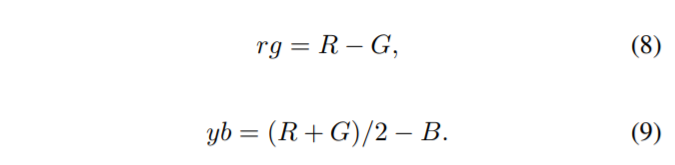
Hasler는 더욱 정확하게 CCI를 계산하기 위해서 아래와 같은 수식을 이용하였으며, 해당 논문의 평가방식도 이 방식을 따랐다고 합니다.
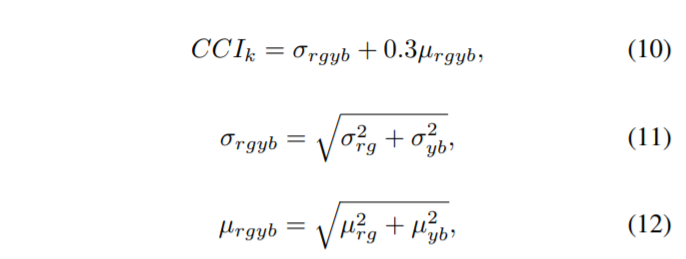
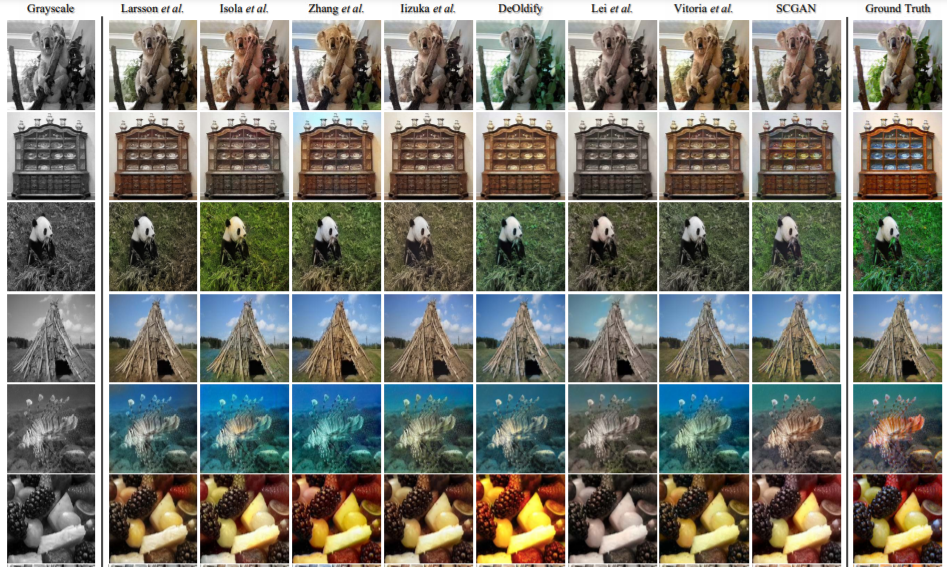
위에는 정량적 결과 비교 영상 중 일부입니다. 2번째와 5번째 column을 보시면 일부 방법론들의 결과 영상이 unsaturated한 것을 볼 수 있으며, 3번째와 4번째 column에서는 semantic confusion 현상이 일어난 것을 확인할 수 있습니다.
예를들어 3~4번째 column 중 4번째 row에서 풀들을 보면 풀들을 성공적으로 분류하지 못하여 마치 썪은 풀처럼 colorization 된 것을 볼 수 있습니다.
그 외에도 6번째 row의 과일들을 보시면 일부 방법론들에서는 과일들의 색상이 번지는 color bleed 현상도 발생합니다. 하지만 SCGAN은 뭐 잘되더라~ 라고 논문에서는 나와있습니다.
saliency map가 정확히 뭔지 모르겠습니다 ㅎ
Saliency map은 결국 관심있는 영역과 비관심 영역에 대해서 마스킹을 나누는 네트워크라고 생각되는데 해당 네트워크가 기존 segmentation과 다른 점은 무엇인가요 ? 제가 생각하기에는 클래스가 필요없다 정도일것 같은데 더 자세히 설명해주실 수 있나요?? 또 추가로 Saliency map 을 얻기위한 saliency prediction network의 GT는 무엇인가요?? 본문에서 ‘decoder 부분에서 3개의 레이어를 추가하여 colorization과 동일한 resolution을 가지는 saliency map’라고 설명하셨는데, 정확히 GT는 어떤것으로 사용하고 Loss는 어떻게 계산하는지 궁금합니다
재미있는 논문 리뷰해주셔서 감사합니다 ~