
IITP가 올해에도 계속 진행되기 때문에 찾아본 논문입니다. 저희가 진행하는 연구의 방향과 비슷한 것 같아 논문을 읽어보았습니다.
Application Usage Overview
본 논문에서도 피실험자의 데이터를 안드로이드 폰으로 수집하여 우울증 정도를 예측합니다.
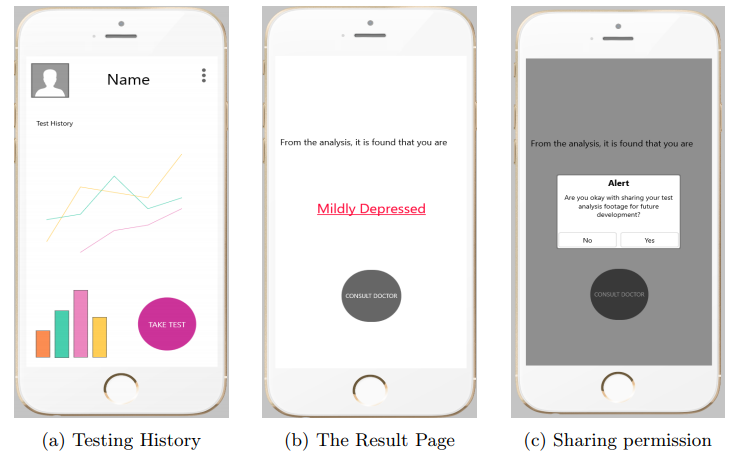
당연히 피실험자에게 스마트폰을 통한 데이터 수집에 대한 동의 여부를 물어보며, 해당 논문에서 만든 Application은 피실험자에게 우울감 상태를 알려주고 이를 가족 및 전문의에게 공유할 수 있다고 합니다.
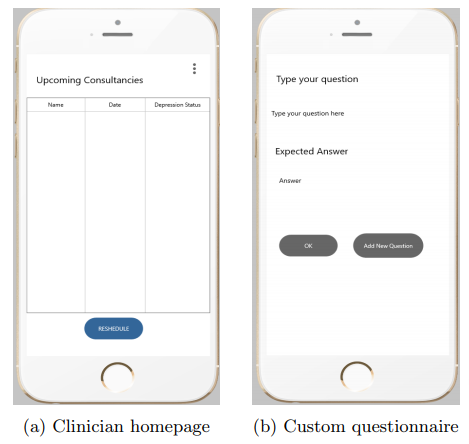
특징적인 부분은 위의 그림 (b)에서처럼 질문에 대해서 실제 응답을 수행하고 이를 우울증 예측에 사용한다는 점 입니다. 피실험자가 입력한 텍스트를 BERT를 이용해서 하나의 피처로 만든다고 합니다. 뒤에 더 설명하겠습니다.
Backend Model
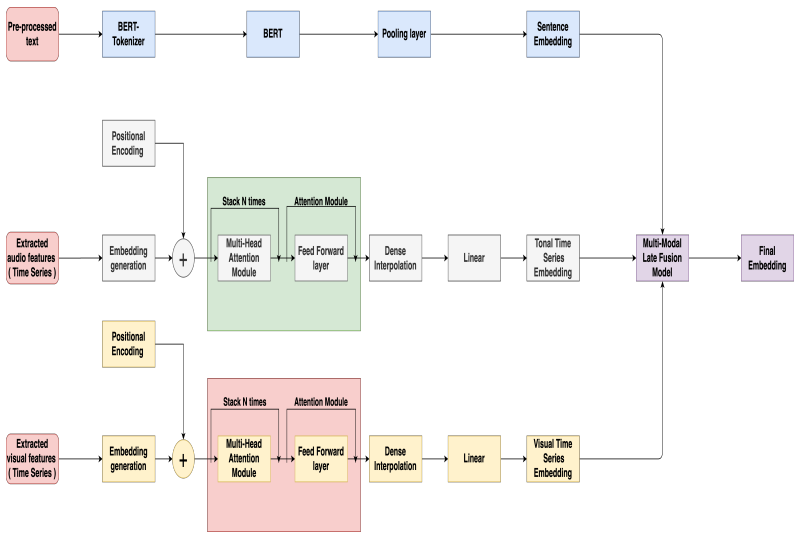
본 논문에서 제안하는 전체 아키텍처 입니다. 사진이 잘 안보일 수도 있는데 논문에 들어가셔서 확인해보시길 바랍니다.
정리해서 설명하자면 해당 논문에서는 질문에 대한 응답을 BERT를 통해서 Sentence Embedding, Time Series의 Audio Feature로 Tonal(음색의) Time Series Embedding, 그리고 Visual Feature로 Visual Time Series Embedding을 만들고 이러한 Multi Modal의 임베딩을 Late Fusion하여 최종적으로 우울증을 예측하는 논문입니다.
본 논문에서는 학습을 위해서 AVEC depression dataset 데이터셋을 사용했다고 합니다. 해당 데이터셋은 4개의 타입으로 피실험자를 인터뷰한 데이터셋이며, 피실험자의 PTSD 및 주요 우울증의 증상이 있는 사람들의 특성을 컴퓨터로 예측하기 위해 수집하였다고 합니다. 해당 AVEC depression dataset에서 사용한 인터뷰의 종류는 다음과 같습니다.

AVEC depression dataset 논문에서는 인터뷰를 통해서 PTSD나 우울증에 대한 다양한 연관성을 찾아냈는데 대표적으로 Visual 정보와 Audio가 있습니다. 해당 논문에서 설명하는 관련 내용을 발췌한 부분은 다음과 같습니다.
” For example, men who scored positively for depression tend to display more frowning than men who did not, whereas women who scored positively for depression tend to display less frowning than those who did not. Other features such as variability of facial expressions show a main effect of gender – women tend to be more expressive than men, while still other observations, such as head-rotation variation, were entirely gender independent. “
” Depression and PTSD are both predicted by more tense voice features, such that those with depression and PTSD exhibit more tense voice characteristics than those without depression or PTSD. Tense voice features were, specifically, able to distinguish interviewees with depression from those without depression with an accuracy of 75%, and distinguish those with PTSD from those without PTSD with an accuracy of 72%. “
자 다시 제가 리뷰중인 논문으로 돌아와서 … 해당 논문에서는 이러한 선행 연구를 기반으로 멀티모달을 통합해 우울증을 예측하는 연구를 수행했습니다. 그래서 학습에 AVEC depression dataset 을 사용했다고 합니다. 자 그럼 본 논문에서는 3가지 특성(텍스트, 비주얼, 오디오) 을 이용합니다. 각각에 대한 Data Pre-processing을 살펴보면 다음과 같습니다.
텍스트 : 텍스트에 대해서 피처를 추출하고 임베딩 벡터를 만들기 위한 전처리를 위해 해당 논문에서는 siamese sentence-BERT 모델인 RoBERTa와 사전학습 모델을 사용했다고 합니다.
비주얼 : 비주얼에 대해서 피처를 추출하기 위해서 해당 논문에서는 OpenFace를 사용했다고 합니다. 이를통해 머리의 포즈, 표정, 시선 등의 정보를 피처 벡터로 추출하였다고 합니다.
오디오 : 오디오에는 많은 노이즈가 포함됐기 때문에 Cycle GAN 기반의 Audio Noise Filter를 사용해 오디오 정보에 노이즈를 제거했다고 합니다. 그리고 노이즈가 필터된 오디오에서 피처를 뽑기 위해서 COVAREP을 사용했다고 합니다.
Model Architecture and Training
모델의 아키텍처는 오디오나 비주얼 피처가 multivariate time-series representation task이기 때문에 해당 분야에서 가장 많이 사용되는 Simply Attend and Diagnose 아키텍처를 사용했다고 합니다. 해당 아키텍처를 처음으로 제안한 논문에서 사용한 구조는 다음과 같습니다.

따라서 본 논문에서도 해당 아키텍처를 그대로 사용했다고 합니다. 오디오와 비주얼 데이터는 시퀀스 데이터기 때문에 Simply Attend and Diagnose 아키텍처를 통해서 임베딩 벡터를 추출하고 텍스트는 RoBERTa 를 통해 임베딩 벡터를 추출해서 마지막에 Fusion을 수행하였습니다. 다음 그림과 같이..
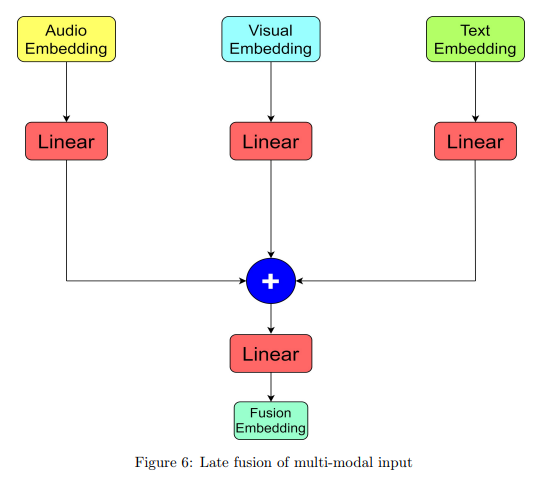
Experiments and Results
앞서 설명한 AVEC depression dataset 을 통해서 학습을 수행합니다. 해당 데이터셋은 인터뷰에 참가한 피실험자들의 PHQ-8(?) 스코어가 포함됐다고 합니다. 해당 데이터셋 피실험자의 분포를 살펴보면 다음과 같다고 합니다.
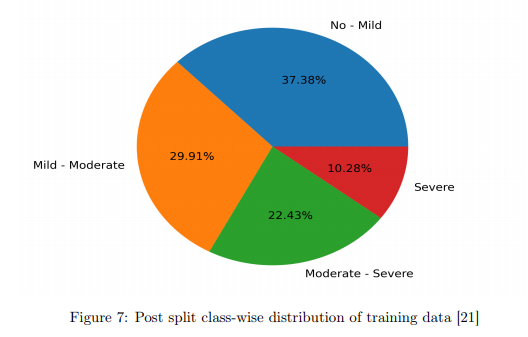
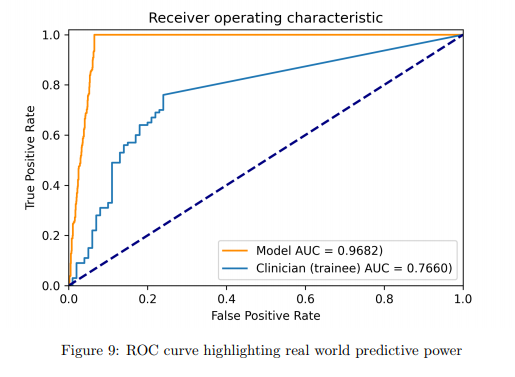
해당 데이터셋을 통해서 각 상태별로 클래스를 나누어 평가를 진행하였고, 평가 결과는 다음과 같다고 합니다. (해당 데이터셋에는 train과 test가 나뉘어져있다고 합니다.)
본 논문에서는 특정 질문에 대한 사용자의 응답 정보(텍스트,음성,비주얼)을 통해 우울감을 예측하고 있습니다. 아래 표는 실제 우울증 진단에 있어서 많은 영향을 미친 질문들을 나타내고 있습니다.
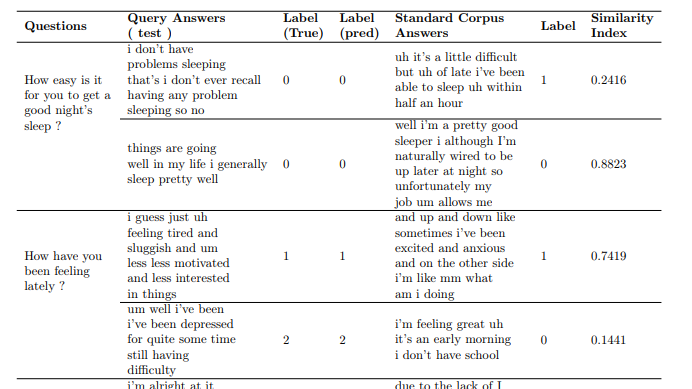
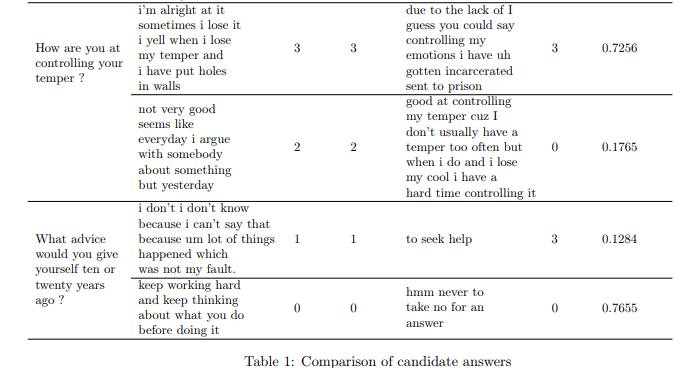
이는 본 논문에서 제안하는 피실험자의 응답을 통해서 클래스 라벨링을 한 결과를 나타냅니다, 여기서 Similarity index는 특정 라벨의 정답이 되는 답변과 피실험자의 답변의 유사도를 나타내는데, 이를 통해 같은 클래스에 속한 피실험자들은 높은 유사도를 보였고, 클래스 라벨의 경계(스코어가 임계값 부근인 케이스)의 피실험자들은 유사도가 낮았다고 합니다. 이를 통해 우울증의 증상정도를 구별할 수 있다고 합니다.
Conclustion
미약한 우울증도 조기에 발견하지 못하면 나중에 나쁜 결과로 이어질 수 있음을 이야기하며 본 논문은 자신들의 방법으로 조기에 우울증을 찾아내 치료하길 바란다고 합니다.
추가적으로…

넵 그렇다고 합니다.
3개의 도메인을 사용하여 inference하는데 사용하는게 인상적입니다. Visual, Text, Audio의 embedding의 차원이 제각각 일거같은데 downsampling하여 차원을 맞추나요? 너무 그 차이가 심하면 어떠한 한 도메인에 dominent하게 결과가 나올지 않을까 싶어서 질문드립니다.
중간에 보시면 linear를 통해서 차원을 맞추고 있습니다.