

동적인 비디오 프레임 선정과 관련된 방법론을 서베이하던 중 특이한 논문이 있었고, 이 논문의 이름은 AR-Net이며 효율성을 고려했을때 비디오의 프레임마다 다른 scale을 선정하는 방법론을 제안합니다. 이 논문을 보기 이전에는 동적으로 프레임을 선정하는 것에만 초점을 두어 서베이를 하였으나 매 프레임마다의 다른 scale을 적용한다는 것이 매우 참신했으며, scale을 아주 작게 적용하여 일부 프레임은 스킵하는 것으로 기존 서베이 목적과 동일하게 사용될 수 있을 것이라 생각해 이번주 리뷰를 통해 소개합니다.
1. Method
1.1 Approach Overview
본 논문에서 제안된 방법은 Fig 2와 같습니다. 크게는 Policy Network와 Backbone Network로 구성되어 있으며 Policy Network 내부에는 모델 크기가 작은 extractor network와 LSTM 모듈로 구성되어져 있습니다. 이때, LSTM 모듈에서 본 논문의 핵심인 매 프레임마다의 scale을 결정해 주게 됩니다. Scale이 결정되고 나면 이 scale에 따라 Backbone Network의 크기도 달라지는데 이는 EfficientNet 논문에서 저자가 compound scaling 방식을 실험하며 보여주었듯, 해상도가 클경우 더 많은 시각적 정보를 처리해야하기 때문이라고 합니다.
1.2 Learning the Adaptive Resolution Policy
Policy Network에서 scale을 선택하기 위해서 Gumbel-Softmax 연산이 사용됩니다. 이는 y_?=\frac{exp(\frac{log(\pi_?)+g_i}{\tau})}{\sum_{?}exp(\frac{log(\pi_j)+g_j}{\tau})} 와 같이 Softmax와 유사하게 생겼으며 주로 이산적인 값들의 미분 값을 추정하기 위해 사용됩니다. 이러한 연산을 사용하기에 앞서 영상으로부터 extractor network를 이용해 feature를 얻어냅니다. 얻어낸 feature를 LSTM에 넣고 hidden state의 값을 얻어낸 후 이에 Gumbel-Softmax 연산을 취하고 scale 값을 구해 resize한 뒤, Backbone Network를 통해 매 프레임마다의 예측값을 알아내게 됩니다. 그리고 이들을 평균내어 video-level의 feature를 만드는 파이프라인을 지니고 있습니다.
앞선 과정에서 scale 값은 이산적으로 (0, 1, 2, … , L+M-1) 로 구성되며 작을 수록 큰 scale을 나타냅니다. 그리고 만약 scale 값이 무한대를 가리키면 해당 프레임을 skip하는 것을 의미합니다. 이처럼 scale 값은 이산적으로 분포되어 있어 미분가능하지 않기에 backpropagation을 하며 최적화를 하기 어려운 상황에 놓여집니다. 또한 이를 대체하기 위해 Softmax와 같은 score function으로 scale을 선정하더라도 이산 차원에서 score function의 분산이 선형적으로 늘어나기 때문에 수렴하기 어려운 문제도 있습니다. 이러한 상황들을 해결하고자 Gumbel-Softmax을 도입하여 scale을 선택하는 과정을 미분가능하도록 바꿨고, 이산 차원에서 좀 더 직접적인 최적화가 가능하도록 하였습니다.
1.3 Loss Functions
Loss term으로는 총 세개가 사용되었습니다. 첫번째로는, Video-level의 feautre가 예측한 class를 판별할 수 있는 일반적인 CrossEntropy Loss(1)가 사용되었습니다. 그러나 위 Loss 는 efficiency를 고려하지 않은채 오직 정확도를 높이는 데에만 초점을 맞춰져 있기 때문에 flops Loss(2)도 추가되었습니다. 이는 미리 Lookup table에 각기 다른 scale 마다의 GFLOPS를 계산해두고 학습 시 높은 계산량을 가진 프레임에 제약을 두는 Loss 입니다. 또한, Policy Network가 scale을 무한대로 선정하는 Skip 프레임을 많이 선정하여 중복되는 프레임이나 질이 낮은 프레임이 많아져서 생기는 inefficiency를 막기 위해 정규화 Loss인 uni Loss(3)도 추가되었습니다. 이는 행동 분포에 있어 높은 엔트로피를 지니는 프레임을 선정하도록 설계되었습니다.
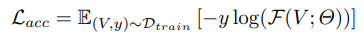
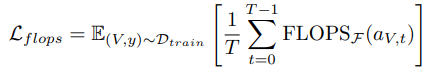
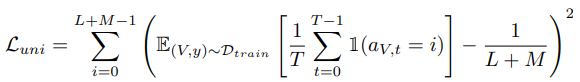
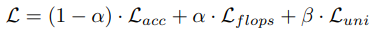
2. Experiment
실험을 위해 비교 군으로 아래와 같은 방법론들을 사용했습니다.
- UNIFORM : 가장 큰 프레임인 224×224의 프레임에서 얻은 feature를 평균내어 video-level의 feature로 이용한 것
- LSTM : 224×224의 프레임을 입력으로 LSTM에서 예측된 모든 값의 평균을 video-level의 feature로 이용한 것
- RANDOM : Policy Network를 학습하여 scale을 선정한 것이 아닌 랜덤으로 선정한 것
- Multi-Scale : 매 프레임마다 최적의 scale을 고른 것이 아닌 여러 scale을 적용하여 예측한 것
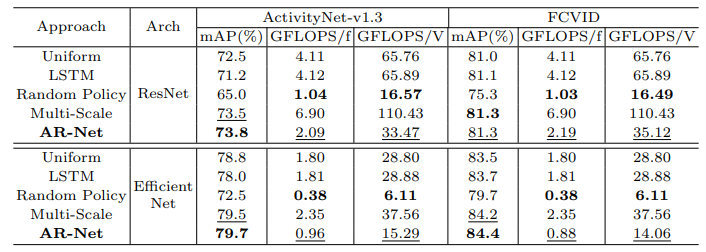
앞서 설정한 비교 군들과 프레임 마다 최적의 scale을 학습하여 찾는 본 논문의 방법론 AR-Net을 비교했을 때 ActivityNet-v1.3 데이터 셋과 FCVID 데이터 셋에서 가장 좋은 성능을 나타내고 있는 것을 Table 1에서 확인할 수 있습니다. 그리고 눈여겨 봐야할 점을 Multi-Scale은 미리 정해둔 모든 Scale을 다 썻음에도 불구하고 AR-Net에 비해 낮은 성능을 보였으며 AR-Net은 Multi-Scale과 비교했을 때 계산량이 70퍼센트 적었습니다.
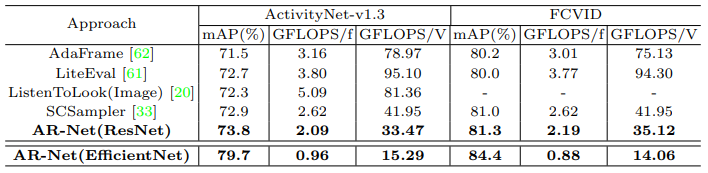
동시에 같은 데이터 셋에서 다른 방법론들과 비교를 하였을 때 mAP에 있어 SOTA의 성능을 보였을 뿐만아니라 계산 속도 면에서도 SOTA를 달성한 것을 Table 2를 통해 확인할 수 있습니다.
3. Reference
[1] https://arxiv.org/pdf/2007.15796.pdf
scale을 계속 변화하는 것 같은데 그럼 scale을 변환 시킬때 interpolation 같은 경우는 어떤 방식으로 하나요?
논문에 resize 시 사용하는 interpolation 종류에 대한 설명은 써있지 않는 것으로 보아 일반적으로 사용하는 bilinear 혹은 bicubic을 사용하지 않았나 싶습니다.