
그 동안 Monocular Depth Estimation 방법론들은 최대한 영상 하나 외에 필요한 부가 정보들을 없애는 방향으로 연구가 진행 되어 왔습니다. 하지만 그럼에도 카메라 내부 파라미터는 무조건 적으로 필요해서 유튜베에서 촬영된 영상같은 미지의 카메라로부터 얻은 영상의 경우 깊이 추정이 어려운 상황이였습니다. 이러한 상황을 극복하기 위해서 구글에서 2019년도에 Inference 단계에서 카메라 내부 파라미터가 안주어줘도 되는 방법론을 이 논문을 통해서 제안했습니다. 이 논문의 키 contribution은 다음과 같습니다.
1. Intrinsic Parameters를 CNN으로 Predict
2. 처음으로 Predict한 Depth를 가지고 Occlusion을다룸
3. 모든 Moving object의Segmentation를 추출하지 않고 간단한 마스킹을 활용함
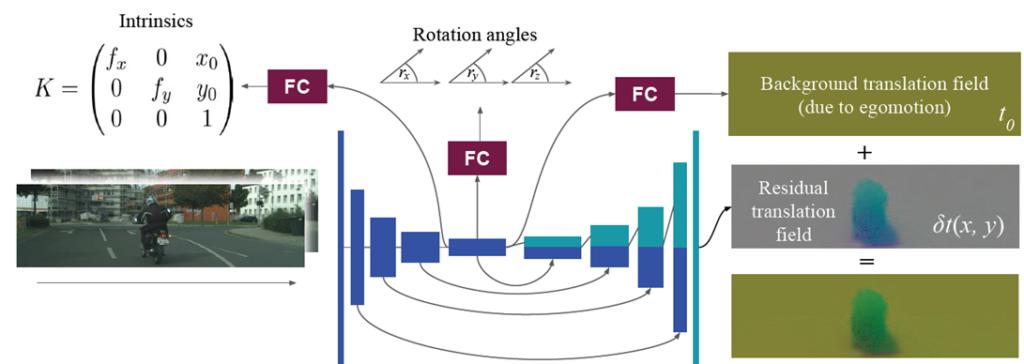
이 방법론은 총 두개의 네트워크를 사용한다. 하나는 Depth 를 추정하는 네트워크이고 다른 하나는 그림 2와 같이 Camera Parameter 그리고 영상속 moving object를 추정하는 네트워크 이다. 이 두번쨰 네크워크를 통해서 camera parameter를 추정하는 것이 이 논문의 큰 첫번째 key contribution이다.
학습하기 위한 Loss로는
1) SSIM 과 L1으로 warp 된 영상과 기존 영상의 차이를 계산
2) camera parameter를 L2 로 계산
3) Smooth loss 를 생성한 disparity와 motion map에 적용
위 loss를 통해서 학습을 진행한다.
Occulusion
Occlusion은 픽셀 비교를 할 수 없게 함, 따라서 Occur 이 된 부분을 Depth 와 motion field를 통해 제거해야함, 하지만 이것을 학습하면서 하려면 매우 어려운 일이다.
이러한 문제를 해결하기 위한 계산으로 이 논문은 다으과 같은 방식을 제안한다.
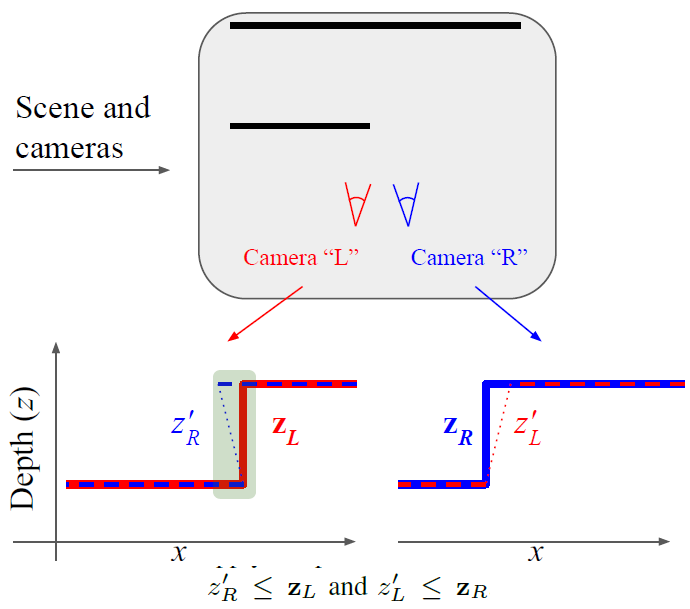
Occlusion 문제를 해결하기 위해 Occlusion이 발생한 부분을 찾는 방식으로 그림 3 과 같은 방식을 제안합니다. 아래 식과 같이 점선으로 warp 한 영상의 Depth 가 기존 영상보다 Depth가 앞으로 나와 있다면 그 pixel이 occlusion이 발생한 부분이라 판단하고 그 부분은 Backpropagation을 안하도록 합니다.
Result
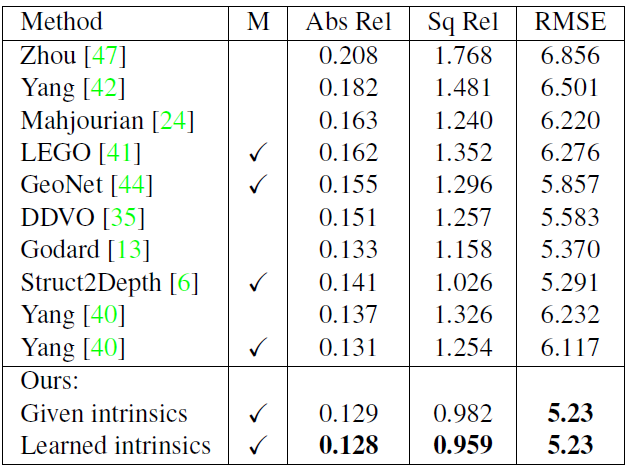
표 1 은 KITTI 데이터셋에서 여러 방법론들의 성능입니다. 이 성능표에서 볼 수 있는 놀라운 점은 Intricsic parameter를 학습하는 방식이 기존 학습하지 않는 방식 보다 더욱 좋은 성능을 기록 했다는 것이다.
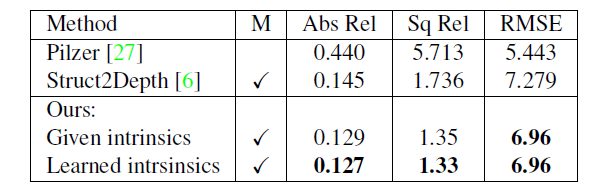
KITTI 뿐만이 아니라 Cityscape에서 또한 동일한 경향성을 보이는 것을 표2를 통해서 확인할 수 있다.
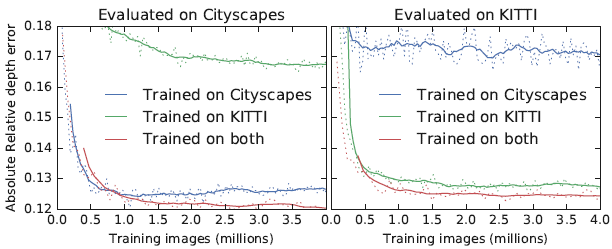
그림 4는 카메라 파라미터의 데이터 셋에 따른 성능 변화를 본 것이다. KITTI로 학습 하고 Cityscape에서 평가한 것과 Citysape로 학습과 평가를 모두 한 것과 성능비교했을때 많이 차이나는 것을 확인 가능하다. 그리고 두개의 데이터셋으로 학습시키고 성능을 각각 평가했을때 전부 기존 보다 오른 것을 알 수 있다 이걸로 카메라 파라미터 역시 데이터를 많이 주면 좋은 성능을 보인다는 것을 알 수 있다.
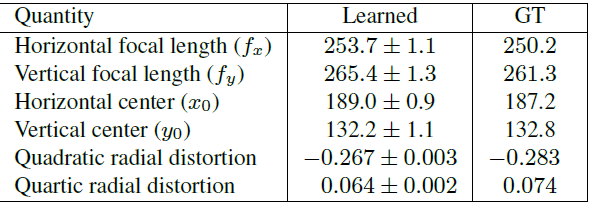
이 논문의 주요 관점인 Intrinsic paramerter을 정량적 성능 평가는 표 4에 나타났다. EuRoC datasetsd에서 평가를 했으며 성능을 보았을때 적은 수치를 내는 것을 볼 수있다.