본 논문은 action recognition을 위한 video frame selection 문제를 다룬다. 아카이브 기준으로 2020.12.19일 공개 되어 코드는 공개되지 않았다.
명칭을 SMART frame selection으로 하였는데 SMART는 Sampling through Multi-frame Attention and Relations in Time의 약자이다.
2021 01 05 추가
즉, 해당 논문을 정리하면,
frame 마다 선택하는 MLP는 2 층짜리 layer로 oracle을 모방하기 위하여 학습하고
global selector는 해당 논문에서 제안하는 방식의 attention을 사용한다.
이 모델에 대한 현재 나의 생각은 다음과 같다.
우션 global selector를 위해 사용한 방법은 FC layer를 이용한 간단한 모델로 짧은 얼굴 영상으로 감정을 분석하기 위한 attention으로 긴 영상에 적용하기에는 무리가 있을 것 같다.
또한 단순히 oracle을 모방하기 위한 학습이 과연 효과적일지에 대한 의문도 든다.
논문의 Relation Work-Frame Selection 부분을 보면
이전 접근법들은 one at a time으로 selection을 진행하는 RL 기반 방법이 많았다고 한다. 즉, 비디오를 Markov decision(의사 결정 과정을 모델링하는 하나의 방법으로, 쉽게 이해하면 현재 프레임과 다음 프래임과의 관계를 확률적으로 나타낼 수 있도록 모델링 한다고 보면 될것같다.)으로 모델링하여 문제를 해결하는 방식이다.
본 논문은 이러한 one at a time 선택 (비디오 전체와의 관계를 고려하지 않는 선택 방식을 말하는 듯 하다)을 기존 접근법의 문제로 하여 one at a time 를 위한 stream과 entire video at a time을 위한 stream의 two stream selection model을 제안한다. 다음 figure 1은 제안하는 모델의 overview이다.
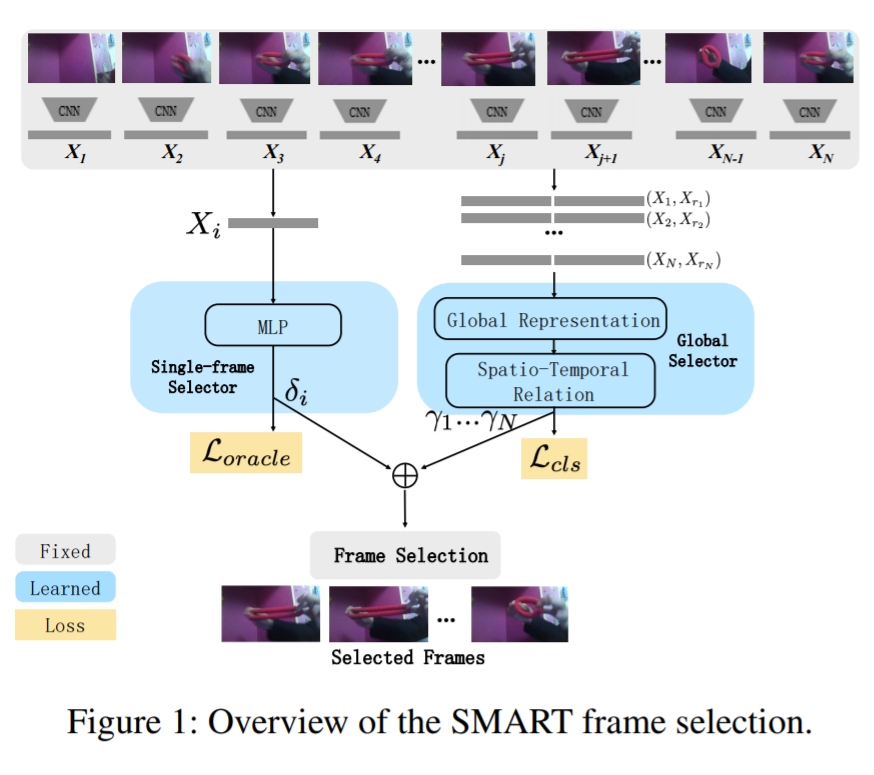
Detail
first(one at a time):
input) 전체 비디오의 feature
output) 각 프레임의 important score (= how useful the frame for classification)
전체 비디오의 feature를 추출하기 위해 Imagenet으로 pre-train된 MobilNet의 output feature를 사용한다. 이 후 모델의 결과인 output top 10 classes를 워드 임베딩 모델(GloVe)을 이용하여 class정보도 feature에 포함된다.
이 후, Huang et al.(2018)을 이용하여 important score을 얻는다고 한다.
second(entire at a time):
input) 프레임의 쌍들 (렌덤으로 선택된 2개의 비디오 쌍)
output) 각 프레임 쌍의 important score
가까이에 있는 프레임간 관계 뿐만 아니라 멀리있는 프레임 간의 관계도 중요하다 판단하여 렌덤 매칭을 하여 input을 구성한다고 한다.
total (classification):
두 socre를 multiplied 하여 top n개의 good frame을 선정한다.
논문에서 소개한 선정 예시 및 실험 결과는 다음과 같다.

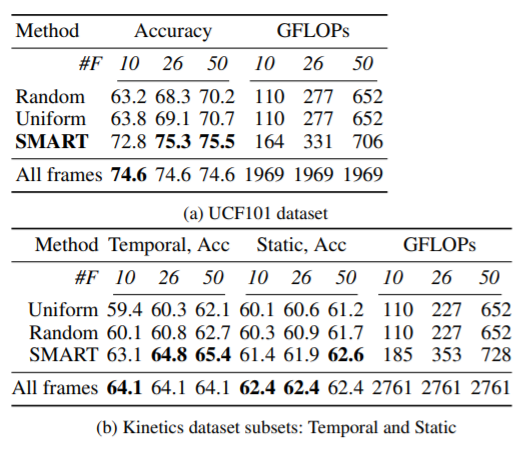
Kinetics dataset의 성능 테이블에서 Temporal, ACC와 Static, ACC는 각각 어떤 정확도를 의미하는 것인가요?!
Kinetics dataset이 Temporal 그룹과 Static 그룹 두가지 종류로 나뉜다고 합니다!