2020년 CVPR Oral paper 입니다. 굉장히 재미있는 논문입니다.
Introduction
3D Point 기반 Object Detection은 2D Object Detectio과는 많이 다른 특징이 있습니다. Point Cloud 데이터는 일단 굉장히 Sparse하고, Unordered하며, Locality sensitive 합니다. 이러한 특성이 3D Point에서의 Object Detection에서의 CNN기반 Object Detection을 어렵게 만듭니다.
이러한 어려운 조건에서도 컴퓨터비전 연구자는 포기하지 않고 3D Point를 이용해서 Object Detection을 수행하는 방법들을 만들었습니다. 일부 연구는 3D Point를 투영시켜서 문제를 풀기도 하였고, 일부 연구는 Voxel을 만들어 문제를 해결하기도 하였습니다.
여기서 Voxel을 처음 들으시는 분들을 위해서 잠깐 설명하자면 Point Cloud 맵을 특정한 큐브 박스로 나누는 개념인데요… 자세한 설명은 해당링크 에 잘 나타나있습니다.
이렇게 Voxel 방법은 3D Point를 이용해 Object Detection을 수행하는데 있어서 굉장히 좋은 성능을 나타냈습니다. 이러한 Voxel 방법을 Voxel based method라고 칭하겠습니다. 이러한 Voxel based method는 가장먼저 3D point를 Voxel로 만들고(Voxelization) Voxel 마다의 Feature를 추출합니다.(예를 들면 Point Net 이나 기타 Handcrafted 방법을 이용해) 그리고 그걸로 Detection을 수행하죠. 이러한 Voxel 기반의 방법들은 2D Object Detection에서 사용된 기법들을 추가적인 과정없이 적용할 수 있다는 장점도 가지고 있다고 합니다.
하지만… 이런 Voxel based method는 Voxelization하는 과정에서 Information Loss를 겪기도 하고, Performance bottlenect에 마주칠 수 있다고 저자는 주장합니다.
그래서 이러한 Voxel 기반의 방법론과는 다른 방법으로 raw point cloud를 그대로 입력으로 사용하는 연구들이 이뤄지고 있습니다. 해당 논문도 raw point cloud를 사용하는 네트워크를 제안합니다. 이러한 raw point 기반의 연구들은 일반적으로 2 단계(Stage) 로 구성됩니다.
첫번째는 raw point를 다운 샘플링과 context feature를 추출하기 위한 Set Abstraction(SA) 레이어를 사용하고, 이후에는 업 샘플링과 동시에 feature를 raw point로 broadcasting 하기위한 Feature Propagation(FP) 레이어를 사용 합니다. 이와 같이 raw point 를 바로 입력으로 사용하는 방법론은 3D region proposal network(RPN)이라고 각 Object의 center point를 첫번째 단계에서 선정합니다.
두번째는 refinement module을 사용해 최종 예측을 수행합니다. 이를 통해서 높은 Performance를 달성할 수 있다고 합니다. 단점으로는 inference time이 실제 real time system에서 사용되기에는 적합하지 않을 정도로 많이 느린 단점이 있습니다.
본 논문에서는 raw point를 이용해 3D Object Detection을 수행합니다. 단 Raw point 방법론의 가장 큰 단점이였던 속도적인 측면을 개선하기 위해서 다양한 방법들을 제안합니다. 이에 대해서는 뒤에서 설명하도록 하겠습니다. 우선 본 논문에서 주장하는 Contribution은 다음과 같습니다.
- 해당 논문에서는 처음으로 lightweight and effective point based 3D single stage object detector를 제안했습니다. 해당 Detector의 이름은 3DSSD 입니다. 해당 논문에서 제안하는 방법론은 기존 point based 방법론에서 속도를 느리게 만들었던 FP layer와 refinement module을 성공적으로 제거하였습니다. 이 두가지 방법은 기존 point based 방법에는 필수적이 였는데, 이 두 부분을 제거함으로 속도 부분에서 엄청난 차이를 감소를 이끌어 냈습니다.
- 본 논문에서는 새로운 SA Layer에서 새로운 전략을 소개합니다. interior point 도 살릴 수 있는 샘플링 방법을 제안해 regression과 calssification을 위한 rich information을 preserve 할 수 있도록 하였습니다.
- 본 논문에서는 delicate(섬세한) box prediction network를 제안하였고, 이를 통해 더 효과적이고 효과적으로 Detection을 수행할 수 있도록 했습니다. 그리고 이러한 프레임 워크를 KITTI 데이터셋과 좀 더 어려운 nuScenes 데이터셋에 적용하여 기타 다른 모든 single stage methods 보다 좋은 성능을 나타냈습니다. 본 논문에서 제안하는 방법은 point based 의 2 stage 방법들과 비교해도 SOTA의 성능을 나타냈고 속도도 향상시켰습니다. (38ms per scene)
Related Work
크게는 LiDAR만 사용하는 연구와 LiDAR와 다른 센서들의 Fusion 으로 Detection을 수행하는 연구로 나뉜다. 다시 LiDAR만 사용하는 연구는 voxel based 방법과 point based 방법으로 나뉜다.
Voxel based : VoxelNet, PointNet, SECOND, PointPillars
Point based : F-PointNet, IPOD, PointRCNN, PointNet++, STD
두 방법의 큰 차이는 point cloud를 사용하는데 있어 voxelization 과정을 거쳐서 Detection을 수행하는지(Voxel based) 아니면 raw point cloud를 그대로 입력으로 사용하는지(Point based) 이다. 본 논문은 point based 방법이며, point based 방법이 갖는 큰 단점인 느린 속도를 개선하기 위해서 point based 방법에서는 필수적으로 사용되던 방법인 FP layer와 refinement module을 제거하였다.
Frame Work
Fusion Sampling
기존 point based 방법은 voxel based 방법보다 느리다. 느린 이유를 분석하면 존재하는 point based 방법이 proposal generation stage와 prediction refinement stage 두 단계로 이뤄지는데, 첫번째 단계에서는 SA layer와 FP layer를 사용한다. 이때 SA layer는 point cloud에 대해서 더 많은 receptive field를 키우고, 더 효율적으로 처리하기 위해서 다운 샘플링을 수행하고 FP layer 에서는 다운 샘플링 과정에서 drop된 이미지들을 recover 하며 feature를 point로 broadcast 한다. 두번째 단계에서는 RPN을 통해서 얻은 proposals을 refinement module을 통해서 최적화하고 이를 통해서 더 높은 정확도로 예측이 가능하도록 한다.
문제는 SA Layer는 receptive field 키우는 등 point의 feature를 추출하기 위해서 필수적이지만, FP layer와 refinement module은 필요성에 비해서 point based 방법론의 속도 저하에 크게 관여한다는 것이다. 다음 표를 보면 실제 각각의 파트가 얼만큼의 시간을 소요하는지 나타낸다.

따라서 본 논문에서는 FP layer와 refinement module을 제거해서 point based의 방법이 더 효율적이도록 만드는 것을 목표로 연구를 수행했다고 한다.
단…. 그러면 효율적인 point based의 Object Detection을 수행하는 프레임 워크를 만들기 위해서는 몇가지 챌린지한 문제가 중요하다. SA Layer는 유클리드 거리를 기준(D-FPS)를 기준으로 point의 subset을 선택해 다운 샘플링을 수행하고 이를 통해 representative points를 만든다. 그리고 FP layer에서 다시 recover 하는데, FP layer가 없으면 실제 box prediction netowork 에서는 SA layer로 다운샘플링해 만든 representative points로만 detection을 수행해야한다는 것이다.
조금 어려우니 다시 설명하면 수많은 cloud point를 유클리드 거리를 기준으로 일정 거리 이상 멀어진 포인트들을 기준으로 다운샘플링을 수행했다. 근데 기존에는 이러한 방법으로 수행해도 FP layer를 통해서 다시 recover 하므로 상관 없었는데, 만약 다운샘플링된 point 만 가지고 box prediction을 수행한다면 정상적으로 prediction이 이뤄질까? 여기서 생각해볼 문제가 있다. 다운 샘플링 과정에서 유클리드 거리 기준으로 진행하기 때문에 고르게 point를 뽑을 수는 있지만, 실제 포인트의 대부분은 배경에서 수집된 포인트이다. 따라서 실제 Object detection을 수행하다면 이렇게 다운샘플링된 representative points로 Detection을 수행하기에는 정보도 부족하고 거의 불가능할 것이다. 또 이런식의 다운 샘플링 수행은 많은 interior 포인트를 버리게 만든다. (3D point object detection에서는 interior(inner) 포인트는 중요하다.)
이러한 내용을 실제 실험을 통해서 논문은 확인했다. 그 실험은 실제 representative point를 분석하였는데, SA layer를 통해서 다운샘플링해 얻은 representative point에서 실제 interior point의 비율을 확인했는데, 다음과 같다.

위의 표를 보면 SA layer를 통해서 다운샘플링을 수행할때마다 실제 interior point의 비율이 줄어들고 있고 마지막에는 65.9% or 50%(prepresentative point의 갯수를 어떻게 정하느냐에 따라서 다르지만 이는 연산량과도 연관있으므로 트레이드 오프 관계이다..) 정도만 살아남는다. FP layer를 통해서 버려진 interior포인트를 살릴순 있지만(실제 기존 방법들은 살리고 있지만) 본 논문의 저자는 FP layer로 살리는건 overhead of computation 이라고 한다.
따라서 본 논문에서는 이러한 방법을 개선하기 위해서 Feature의 거리를 사용하는 방법을 제안한다. 기존은 3D 포인트의 유클리드 거리를 기준으로 샘플링을 수행했다면 본 논문에서는 Feature의 거리를 기준으로 샘플링을 수행하는 방법을 제안한다. 저자는 Feature disrance방법을 통해서 무의미한 네거티브 포인트(배경)을 지울 수 있다고 이야기한다.
자 그럼 Feature distance 통해서 무의미한 배경에서 포인트가 샘플링 되는것도 막고 유의미한 포인트를 최대한 살리는 방향으로 수정했다. 이제 그럼 완벽할까? 본 논문에서는 아니라고 이야기한다. 왜냐면 feature distance 통해서 샘플링을 수행할 경우 실제 유의미한 point를 많이 얻을 수는 있지만, 자동차를 예로 들면 자동차의 유리나 자동차의 바퀴와 같이 서로다른 피처들을 나타내는 포인트를 추출했지만 결국 두 피처 모두 자동차를 나타내기 때문에 실제 자동차에 대해서 중복된 포인트들만 추출하게 될 수 있다.
따라서 본 논문에서는 중복성은 줄이고 다양성을 높이기 위해 유클리드 거리와 feature의 거리를 적절하게 섞은 F-FPS룰 제안한다. 이를 수식으로 나타내면 다음과 같다.
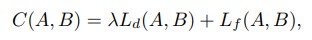
여기서 람다는 밸런스 factor인데 이를 조절해서 적절한 값을 찾을 수 있다. 실제 이를 통한 결과는 다음과 같다.
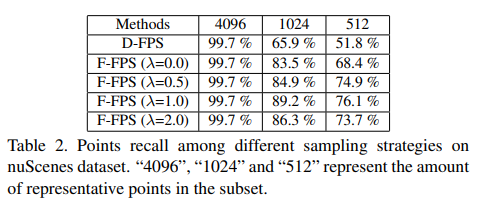
F-FPS의 방법은 기존 D-FPS보다 51.8% 보다 더 많은 포인트(76.1%)들을 살릴 수 있었다. 이를 통해서 FP layer의 필요성을 제거할 수 있게 됐다.(속도 향상)
비슷한 맥락에서 F-FPS를 사용해서 더 많은 interior 포인트를 살릴 수 있었다. 이는 더 좋은 box prediction을 이끌어 낼 수 있다. 근데 문제는 이렇게 interior 포인트가 많아지만 무작정 좋아진걸까??
본 논문에서 저자는 아니라고 답한다. 그 이유는 이렇게 interior 포인트가 많아진건 positive point가 많아졌다는 걸 의미하는 것이며, 이는 regression에서는 효과를 나타내지만 반대로 classification에서는 방해가 될 수 있다고 이야기한다. 왜냐면 만약 주위에서 negative point가 없으면 receptive field를 키우기가 불가능해지고(?) 결론적으로 모델은 positive 와 negative point를 식별할 수 없게 된다고 한다. (우리가 알기 쉽게 정리하면 언밸런스 문제가 발생하는 것 같다.) 그리고 이러한 내용을 실제 ablatioin study를 통해서 증명한다. 아니 그렇다고 해도 F-FPS가 D-FPS보다 좋다.. 따라서 이러한 애매한 상황이 되는데 그래서 본 논문의 저자는 많은 positive point와 언밸런스 문제가 발생하지 않도록 충분한 양의 negative point를 얻기위해서 SA-layer에서 F-FPS와 D-FPS를 융합(Fusion)해 샘플링을 수행한다. 각각 샘플링을 수행하고 이를 합치는 방식이다. 이때 합칠때는 그냥 반반 합친다고 한다.
Box Prediction Network
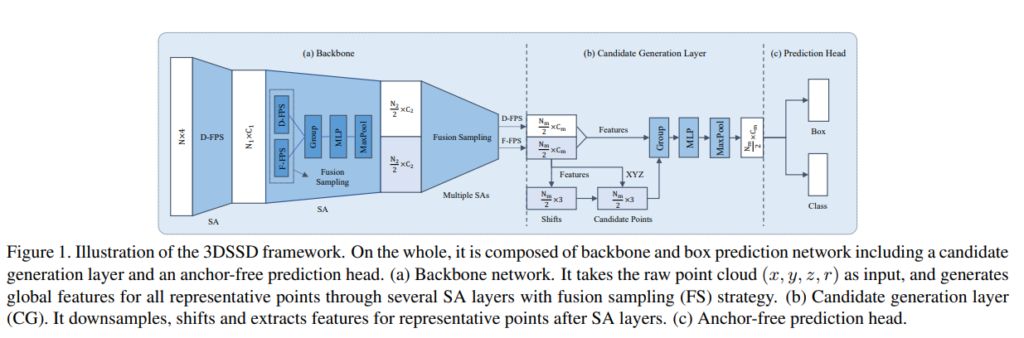
자 앞에서 FA layer를 없애고 SA layer만을 통해서 적절한 postive와 negative가 살아남은 representative point를 추출하였다. 이제는 이러한 포인트를 가지고 피처를 추출해야한다. 기존의 point based 방법에서는 SA layer에서 prediction을 수행하기 이전에 point에서 feature를 추출했다. 이전에 제안된 방법들은 SA layer에서 feature를 추출하기 위해서 3단계를 거치는데, center point 선택하기, surrounding point 추출하기, semantic feature 생성하기 3단계를 통해서 feature를 추출한다.
본 논문에서는 이러한 과정에서도 computation cost를 줄이고 앞서 제안했던 fusion sampling의 이점을 최대화 하기위해서 Candidate generation layer(CG)를 제안한다. 해당 방법은 Fusion sampling을 통해서 적절한 positive , negative point를 선정하였다. 이 포인트중에서 positive 포인트만을 사용해서 F-FPS를 사용해 추출한 포인트들만을 가지고 초기 center point를 선정한다. 그리고 이 center point는 shift하면서 최종 center를 정한다고 합니다. (이때 shift는 ‘under the supervision of their relative locations to their corresponding instances’ 한다는데 해당 부분은 잘 이해가 안되네요…)

그림을 보면 F-FPS로 선정된 포인트(초록색) 를 shift해서 candidate point를 구하고 이를 통해서 빨간색인 Instance Center를 구하는 것을 볼 수 있습니다. 이때 Instance Center를 구하기 위해서는 VoteNet에서 사용한 방법을 이용하는데 해당 포인트의 벡터를 Voting해서 센터를 선정하는 방법입니다.
이렇게 구한 센터 포인트와 일정 threshold를 넘긴 D-FPS, F-FPS로 구한 surrounding 포인트 들을 가지고 MLP layer를 통해서 feature를 추출한다고 합니다. 그리고 이 feature를 가지고 prediction head에 입력해 regression과 classification을 수행합니다.
이러한 전체적인 흐름을 나타내는 그림은 아래와 같습니다.
Anchor based vs Anchor free Regression Head
2D Object Detection과 비슷하게 3D Detection 에서도 Anchor based와 Anchor free 방법이 존재합니다. 본 논문에서는 결론적으로 lightweight design을 위해서 Anchor free 방법을 사용합니다.
Anchor free Regression Head 에서는 distance와 size 그리고 orientation를 예측합니다. 이때 Anchor free 방식이기 때문에 ‘Frustum pointnets for 3d object detection from RGB-D dat, CoRR, 2017’ 에서 제안한 Classification, Regression 하이브리드 formulation을 사용한다고 합니다. (추후 논문을 읽고 다시 추가보완하겠습니다) 특별히 orientation angle은 bin을 나누어 classfy하였는데, 실험적으로 12개로 나눴다고 합니다.
3D Center-ness Assignment Strategy
학습 과정에서는 각 대상에 대해서 라벨(GT)이 필요합니다. 2D Object detection에서는 각 박스에 대해서 IOU를 통해서 픽셀마다의 라벨을 assign 합니다. 하지만 3D point에서는 어떻게 해야할까요? FCOS라는 논문에서 방법을 continuous center-ness label 방법이 제안됐지만, 이 방법은 포인트 레벨에서 나누기에는 불가능하다고 합니다.
따라서 본 논문에서는 예측된 Candidate 포인트사용하는데, 그 이유는 Candidate 포인트가 instance center와 가까울수록 더욱 정확하게 localization 예측하는 경향이 있고, 3D center-ness 라벨이 쉽게 구별할 수 있기 때문입니다. (..?)
따라서 일단 Candidate 포인트가 instance 에 있는지 binary value로 결정하고, 그때 corresponding instance의 6개의 평면(앞,뒤,상,하,좌,우) 의 거리에 따라서 center-ness label을 계산한다고 합니다. 이를 수식으로 나타내면다음과 같습니다.
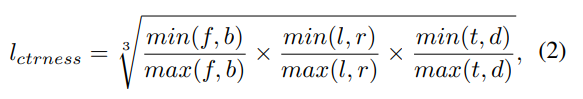
(해당 부분도 코드레벨에서 보면서 한번더 확인후 보완하겠습니다)
Loss Function
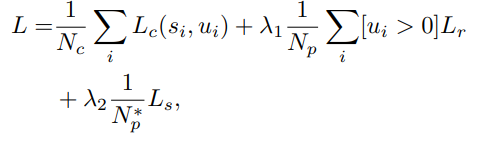
3D point based Object detection의 기법인 3D SSD에서 사용되는 Loss Function은 위와 같습니다. N_c, N_p는 전체 candidate 포인트의 갯수, positive candidate 포인트의 갯수를 나타내며, L_c는 Classification Loss로 s_i는 predicted classification socre, u_i는 center-ness label을 의미합니다. 그리고 L-r은 Regression Loss를 의미하며 Regression Loss에는 Distance Regression, Size Regression, angle Regression Loss와 Coner Loss로 구성됩니다. distance, Size Loss는 Smooth L1 loss를 사용하였고, Angel regression loss에는 orientation classification loss와 residual prediction loss가 포함되는데 이는 다음과 같습니다.
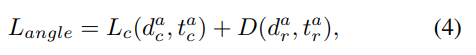
위의 수식에서 dac는 predicted angle class를 dar은 residual을 의미하며 t는 target입니다. 다음으로 Coner loss는 8개의 coner와 assigned ground truth 사이의 distance loss를 의미하며 다음과 같습니다.
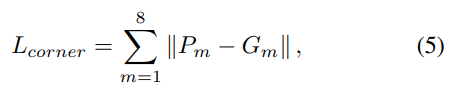
여기서 P는 prediction, G는 Ground-truth를 의미합니다. 그리고 마지막으로 CG layer에서 shifting loss 가 있는데, 해당 로스는 smooth L1 loss를 사용합니다.
Experiments
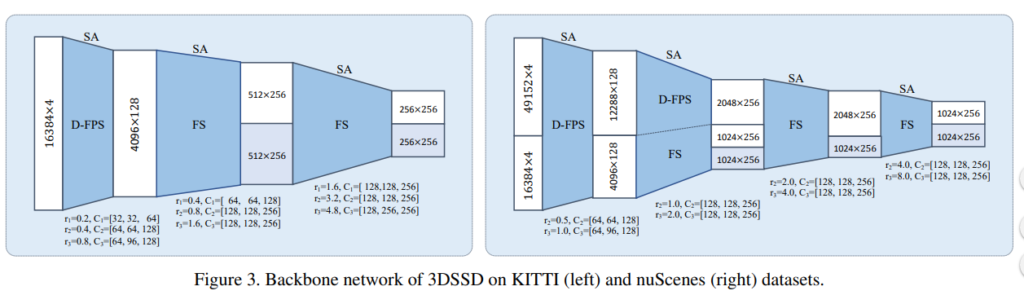
실험은 KITTI 데이터셋과 nuScenes 데이터셋으로 수행하였습니다. 논문에서 제안하는 방법론은 point based 방법이기 때문에 voxelization은 필요하지 않는데, KITTI 셋은 많은 3D object Detection의 선행연구에서 다룬것처럼 Car Class에 대해서만 성능을 평가해 SOTA를 달성했다고 합니다. 데이터셋의 입력으로는 각 scene 마다 전체 point cloud에서 랜덤으로 선택한 16k개의 포인트를 가지고 Object Detection을 수행했다고 합니다. nuScenes 데이터셋은 더 챌린지한 데이터셋인데, 10개의 다른 클래스를 포함하고 있습니다. 해당 데이터셋은 프레임당 40k의 포인트가 존재하고, velocity와 attribute를 predict하기 위해 모든 선행 연구에서는 키프레임과 가장 최근(last) 0.5초의 프레임을 combine 했는데 이를 통해서 얻는 포인트는 400k개라고 합니다. 400k의 포인트는 point based 방법론에서는 너무 많은 포인트고 GPU 메모리도 부족하게 됩니다. 따라서 해당 데이터셋에 대해서는 어쩔 수 없이 voxelization을 수행하였다고 합니다. 그리고 voxelization 이후에 랜덤으로 선택한 65336개의 voxel을 사용했다고 합니다. 각각 데이터셋에 대한 실제 사용된 모델의 입력 및 채널은 다음과 같다고 합니다.
자 그래서 결론적으로 본 논문에서 제안하는 방법론의 성능을 선행 연구와 비교하면 다음과 같습니다.
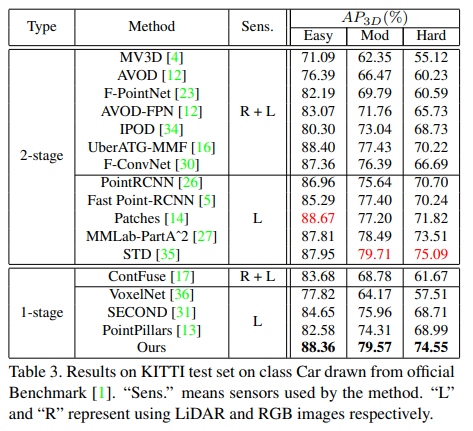
먼저 KITTI 데이터셋에 대해서 다양한 Multi Sensor를 사용한 방법론들과 비교했을때, 라이다 센서만 사용했음에도 라이다 + RGB를 사용한 선행 연구들보다 좋은 성능을 나타냈다고 합니다.

다음으로는 nuScenes 데이터셋에 대해서도 voxel based 의 SECOND와 PointPillars보다 좋은 성능을 나타냈다고 합니다.
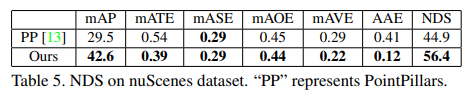
NuScenes 데이터셋에서는 여러가지 평가방법을 통해 NDS라는 score를 계산해 성능을 비교하는데 각각은 다음과 같습니다. mean average precision(mAP), mean average erros of location(mATE), size(mASE), orientation(mAOE), attribute(mAAE) and velocity(mAVE)
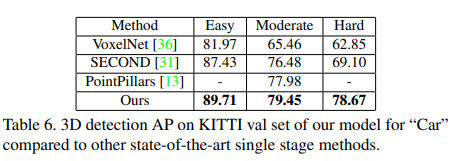
KITTI 데이터셋에서 Voxel based 방법보다 좋은 성능이 나타남을 의미합니다.
그리고 밑에 지표들은 Ablation study 결과를 나타냅니다.
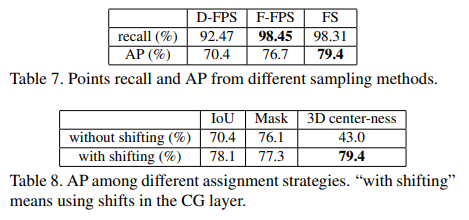
그리고 마지막으로 다른 point based 방법들보다 월등히 속도가 빠름을 이야기합니다.

해당 방법의 Qualitative result 입니다.

나만의 Conclusion
해당 논문을 읽으면서 3D point Object Detection에 대해서 많은 것을 알 수 있었습니다. 아직 일부 디테일에 대해서 부족하지만, 이는 코드레벨에서 확인하고 실제 참조한 이전 연구들에서 제안한 방법들을 확인해보면서 채워나갈 예정입니다. 실제 3D SSD는 코드도 공개가 잘 되어있어서 다음주에는 코드레벨에서의 리뷰를 수행하고 결론적으로 RCV 구성원 여러분들께 3D SSD 튜토리얼 코드를 제공할 수 있도록 이번 겨울방학에 열심히 공부해보겠습니다.
포인트클라우드 기반의 3D OD 이군요. FP layers and the refinement module를 제거함으로써 inference time을 줄였구요. 일반적으로 포인트기반의 3D OD에서는 2 stage를 사용한다고 하셨구.”업 샘플링과 동시에 feature를 raw point로 broadcasting 하기위한 Feature Propagation(FP) 레이어를 사용 합니다. ” 라고 언급하셨는데 해당 부분이 이해가 가지않습니다.
댓글작성중 실수로 엔터를 쳐서 이어서 씁니다. 아마 ” raw point로 broadcasting 하기위한” 이란 부분때문에 이해가 안가는거 같은데 설명좀 부탁드려도될까요? 그리고 voxel 기반의 방법론들과 비교하면 속도가 혹시 어떤지 아시나요? 해당 논문에서 제안하는 방법론으로 computation time을 줄였는데 voxel기반 만큼 computation이 줄어들었는지… real time으로 3D OD가 가능한지가 궁금합니다.
해당 논문은 3D 클라우드 포인트 자체를 사용하는 논문입니다. point based 방법은 3D 포인트를 통해서 feature를 추출합니다. 그리고 그 feature를 다시 실제 포인트에 맞게 broadcasting하는 과정이 FP입니다. segmentation 모델이 다운샘플링으로 줄여서 피처를 추출하고 업샘플링으로 픽셀별 클래스를 구분하는것과 같다고 보시면 될 것 같습니다. 실제 FPlayer는 SA에서 다운샘플링 하면서 사라진 포인트들을 업샘플링 과정에서 recover하는 목적으로 설계된 레이어라고 생각하시면 될 것 같습니다(만 저도 이전 논문들을 안읽어봐서 다음주에 읽어보겠슴돠)