본 논문은 Underwater 환경에서 6DOF Object Detection을 수행하는 연구입니다. 해당 논문은 코드도 함께 공개하고 있습니다.
Abstract & Introduction
본 논문은 딥러닝 기반의 실시간 6D Relative pose를 한 장의 이미지를 가지고 예측하는 논문입니다. 해당 논문에서 저자가 이야기하는 논문의 Contribution은 다음과 같습니다.
- 본 논문에서는 제안하는 네트워크는 6D pose를 계산하기 위해 Object bounding boxes와 8 keypoint를 예측합니다. 앞서 모델이 예측한 2D keypoint들에 2D-to-3D correspondence를 적용하여 6D pose를 예측합니다.
- 렌더링 이미지로 학습하는 방법론은 실제 이미지에서 GT를 얻기위해 라벨링하는 과정을 없애 효율적임을 나타냈고, 라벨링한 이미지에 augmentation을 적용하면 color-loss, texture-smoothing 기타 domain-specific challenges에 강인함을 보였습니다.
- Aqua2 robot에서 수집한 ocean과 swimming pool 데이터셋을 공개하였습니다.
Proposed system
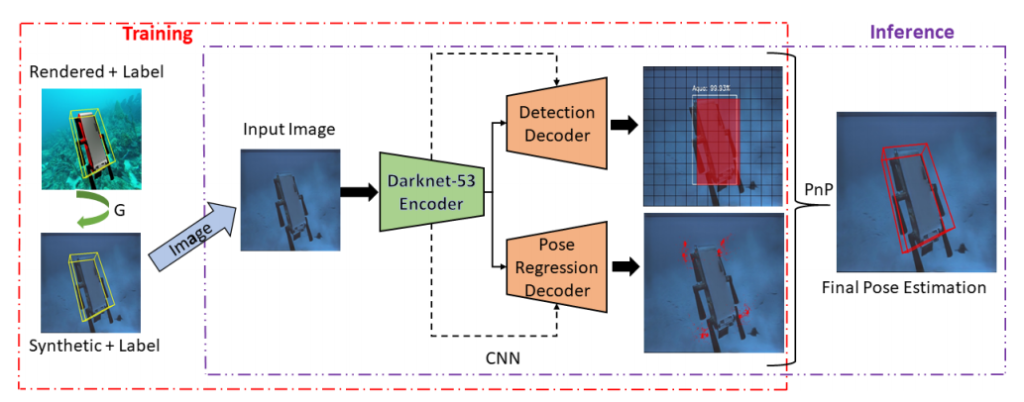
위 그림은 본 논문에서 제안하는 전체 구조 입니다.
가장 먼저 Training 과정에서는 UE4( Unreal Engine 4 ) 으로 렌더링한 Aqua2(로봇이름)의 3D모델(직접 만들었기 때문에 해당 모델의 6D pose는 알고있습니다)를 ocean이미지 위에 투영 시킵니다.

해당 이미지를 그대로 사용하기에는 GAP이 존재하기 때문에 CycleGAN으로 도메인 GAP을 줄입니다.

이렇게 만들어진 이미지를 본 논문에서 제안하는 네트워크의 입력으로 사용합니다. ( 이때 해당 영상의 GT가 되는 6D pose는 UE4로 모델링했기 때문에 알고 있습니다. ) 네트워크에 본 영상을 입력으로 주면 네트워크는 총 8개의 코너지점을 예측하게 됩니다. 여기서의 코너지점이란 3D 박스를 2D에 투영시킬때 발생하는 8개의 점을 의미합니다. Projection 시킨 8개의 2D 점에 PnP를 사용해 6D pose를 estimation합니다. 더 자세히 확인해보겠습니다.
A. Domain Adaptation
Domain Adaptation에는 Cycle GAN을 사용합니다.
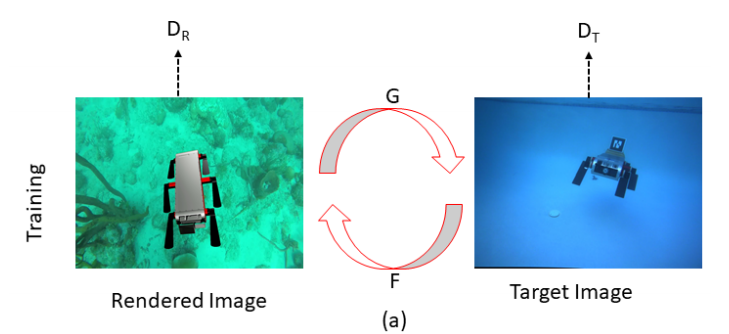

이때 Generator는 2개가 있는데, 하나는 simming pool을 타겟으로 하는 Generator와 다른 하나는 Ocean environment를 타겟으로하는 Generator라고 합니다.
B. 6D Pose Estimation
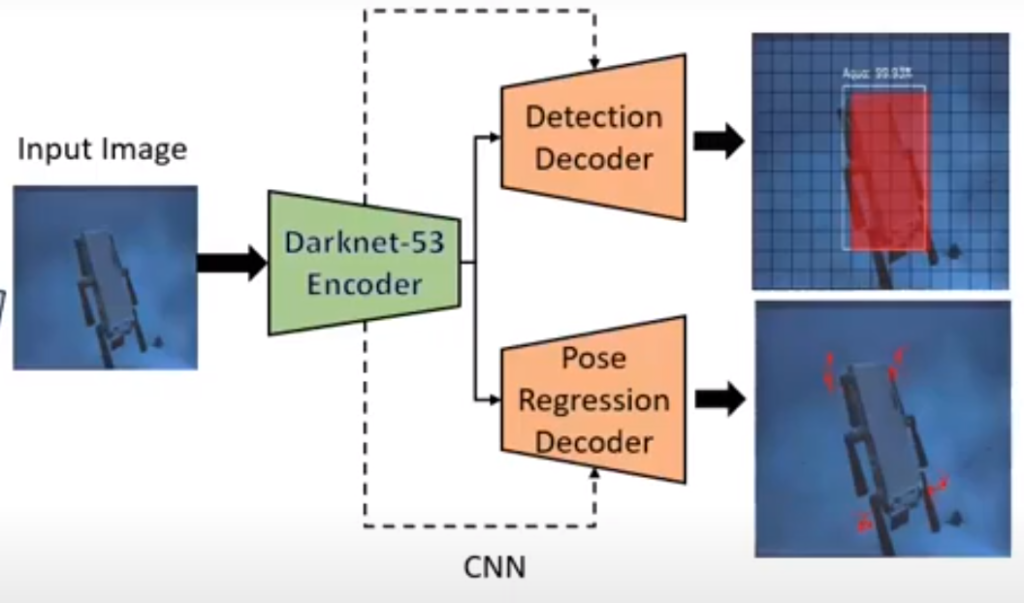
6D Pose Estimation을 위해서 인코더 네트워크로는 Darknet-53을 사용합니다. 디코더 네트워크는 2개가 있는데. 하나는 Detection Decoder, 다른 하나는 Pose Regression Decoder 입니다. Detection Decoder는 Object를 bounding box로 예측합니다. 그리고 Pose regression Decoder는 3D 물체의 2D 코너 코너키포인트를 회귀(Rgegression) 합니다.
Object Detection Stream

해당 부분은 모두가 잘알고 있는 YOLOv3와 같습니다.
Pose Regression Stream
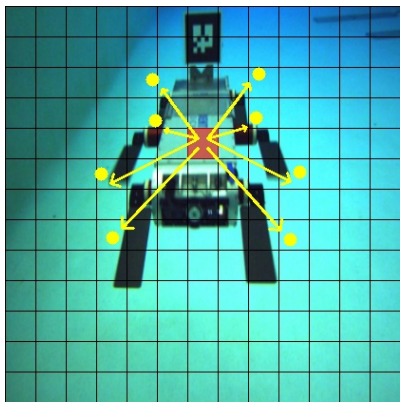
해당 부분에서는 3D 모델을 투영시킨 2D 포인트 8개를 구한다. 이때. 해당 포인트 8개는 모델이 직접적으로 예측하는 방법은 아니며, corresponding grid cell과의 offset을 학습시킨다.
C. Pose Refinement

Pose Refinement는 총 4단계로 진행되는데 하나씩 살펴보자.
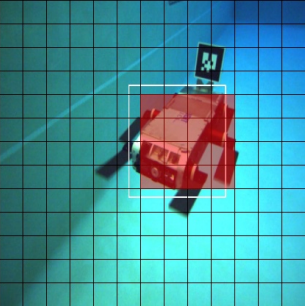
가장먼저 2D obejct detection을 수행한 결과를 얻는다. 이때 NMS를 이용해 최종 박스를 구한다고 한다.

각 grid cell이 예측한 오프셋을 기준으로 3D corresponding 3D 키포인트를 구한다. 위의 그림은 실제 계산된 8개의 점들을 표현한 것이다.

실제 모델이 찾은 박스 밖에 있는 grid cell이 예측한 point는 제거한다. 일차적으로 클러스터링 하여 일정 범위(0.3) 이상의 범위의 점들을 제거한다. 그리고 confidence도 0.5이하인 점들을 제거한다. 이렇게 여러 과정을 수행하여도 여러 후보군이 될 수 있는 포인트들이 남아있는데, 실시간 처리를 위해서 경험적으로 각 위치마다 12개의 포인트만 남기면 된다고 한다.

마지막으로 여러 필터과정에서 남은 포인트를 PnP를 이용해 6D pose를 구한다. 이때 RANSAC을 이용해 노이즈를 한번더 제거한다.
EXPERIMENTS
해당 분야에서 사용되는 데이터셋과 본인들이 제작한 데이터셋에 대해서 설명한다. 해당 분야에서 사용되는 데이터셋으로는 Barbados 2017 Datasets, Barbados GoPro Datasets가 존재하고 본인들이 Pool Dataset을 만들었다고 한다.
따라서 Rendered/Synthetic Dataset을 이용해 학습을 진행하고, 위에서 언급한 3가지 데이터셋에 대해서 평가를 수행했다고 한다.
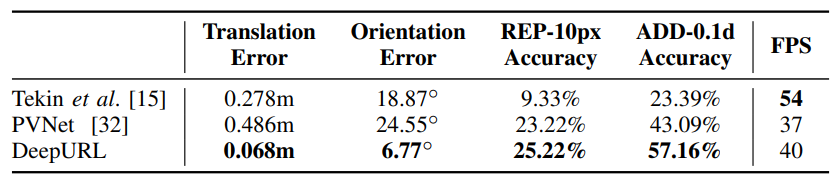
본인들이 제안한 방법과 다른 방법을 Pool Dataset에 대해서 적용했을때 가장 성능이 좋다고 한다. (ADD는 지난번 6DOF에서 설명한 메트릭이다. 다만 차이는 모델 크기의 10% 미만으로 예측한 차이가 작으면 그건 맞혔다고 해서 측정한다고 한다. 물속이라 더어려워서 그런가 …?)

거리별 오차를 나타내면 다음과 같다.
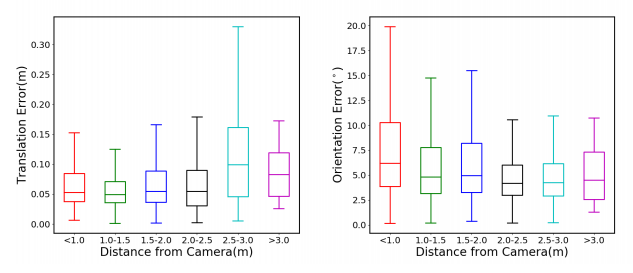
아무래도 단일 이미지를 가지고 예측하다보니 아직은 결과가 많이 높진 않다.

정성적인 결과이며 발표영상도 함께 링크한다.
위에도 이야기했지만 해당 논문은 코드도 제공하고있다.
어려운 논문 같은데 이렇게 금방 읽게 해주셔서 감사합니다!
합성 이미지를 Cycle gan의 입력으로 도메인 통일된 이미지로 6DOF를 추정하고, 이를 위해 실제 수중 이미지(ocean, pool)를 합성 이미지로 변환하는 것 같은데, 실제 수중 이미지에서 바로 도메인 통일을 진행하지 않은 건 데이터셋 생성 (라벨링 작업)을 줄이기 위한 방법인가요?
중간 그림에서 detection decoder와 pose regression decoder가 병렬적으로 연결되어있는데 detection decoder 뒤에 검출 결과를 이용할 수 있도록 pose regression decoder를 직렬 연결하는 방법이나 pose regression decoder에서 bounding box를 추출하는 방법도 가능해 보여서 궁금합니다
넵 맞습니다. 렌더링할경우 6DOF 포즈를 알고있기 때문에 라벨링 과정을 생략할 수 있습니다. 중간 그림에서 병렬적으로 연결한 것은 실제 Mask RCNN과 같이 두가지 Task이기 때문에 병렬적으로 수행한 내용이고 실제로는 Object Detection을 수행한 이후에 해당 Object detection 박스 이내의 grid cell에 대해서만 6DOF Regression 값들을 사용합니다.