https://arxiv.org/abs/1812.03506 논문에 기반하여 작성하였습니다.
컴퓨터 비전에 있어서 6DoF localization은 중요한 과제중 한개입니다. 그 이유는 GPS-denied environments에서의 자율주행차나 증강현실 기술에 활용되기 때문입니다. 또한 visual localization은 Structure-fromMotion (SfM) 이나 SLAM에 활용되기 때문에 중요한 기술입니다. visual localizaion은 크게 indoor 와 outdoor로 나뉘며 계절, 빛 등 각종 방해요소들에 robust하게 하는것이 관건입니다.
해당 논문에서는 이동기기에서 제한된 resource로 large scale의 visual localizaion을 할때의 상황에 주안점을 두고 있습니다. 좀 더 구체적으로는 test query의 6-DoF pose를 estimation 하는것을 목표로합니다. 이 논문의 주요 contiribution은 다음과 같습니다.
- We set a new state-of-the-art in several public benchmarks for large-scale localization with an outstanding robustness in particularly challenging conditions;
- We introduce HF-Net, a monolithic neural network which efficiently predicts hierarchical features for a fast and robust localization;
- We demonstrate the practical usefulness and effectiveness of multitask distillation to achieve runtime goals with heterogeneous predictors.
6-DoF visual localization methods는 전형적으로 structure-based와 image-based로 나뉩니다. 해당 논문이 발표될 시점인 2019년 4월 이전까지 leading을 하고 있던 방법론인 query image의 2D keypoints와 3D points를 이용한 matching방법은 꽤나 정확한 pose estimation이 가능했지만 computation 이 너무 많았습니다. 따라서 모델사이즈가 커지고 레이어가 깊어지면 aliasing이 증가했고, 이러한 점은 ambiguity를 증가시켰습니다. 특히나 낮과 밤이 바뀌는 등 큰 차이가 발생하면 robust성을 잃어버리는 단점이 있었습니다.
Hierarchical Localization
해당 work에서는 localization의 robust성을 극대화하는 것과 computation time을 줄이는 것을 목표로 합니다. 이를 위해 기존에 존재하던 방법론인 SuperPoint, mobileNetVLAD등을 이용한 Hierarchical localization과 HFnet을 제안합니다.
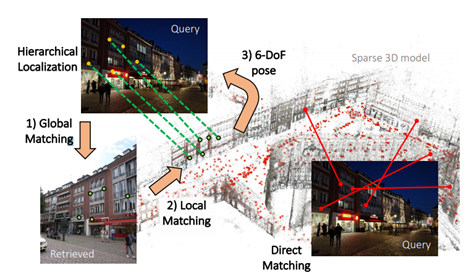
Global descriptor를 이용해 retrieval을 하고, local feature matching을 통해 6DoF pose를 예측합니다. 해당논문에서는 이러한 과정을 hierarchical하다고 표현했습니다. 그리고 HFnet이라는 제안된 네크워크에서는 이를 동시에 진행합니다.
Prior retrieval.
Map lavel에서의 이미지 탐색은 test query와 database로 부터 얻은 global descriptor의 매칭을 통해 수행됩니다. Prior frames이라 불리는 k-nearest neighbors은 map에서 candidate를 대표합니다. 이 탐색은 SfM 모델에서 포인트보다 데이터베이스 이미지가 훨씬 적다는 점을 고려할 때 효율적입니다.
Covisibility clustering.
Prior frames은 co-observe하는 3D 구조를 기반으로 함께 클러스터링됩니다. 이는 데이터베이스 이미지를 모델의 3D 지점에 연결하는 co-visibility graph에서 ‘place’라고 불리는 연결된 구성요소를 찾는 것과 같습니다.
Local feature matching.
각각의 place에서, 쿼리이미지로 부터 구한 2D 키포인트를 place에 포함된 3D points와 연속적으로 매칭시켰습니다. 그리고, RANSAC과 PnP를 사용하여 6-DoF pose를 구했습니다. 이 local search은 고려하는 3D 포인트 수가 전체 모델에 비해 현저히 적기 때문에 효율적이라고 합니다. 해당 알고리즘은 유효한 포즈를 추정하는 즉시 정지합니다.
Discussion
Image search를 위한 대규모 최신 네트워크인 NetVLAD는 소형 모델인 MobileNetVLAD로 발전합니다. 이는 원래 모델의 정확성을 부분적으로 유지하면서 mobile 기기같은 제한된 자원에서의 image retrieval task를 수행하는데 도움이 됩니다. 그러나 로컬 매칭 단계는 SIFT를 기반으로 하는데, SIFT는 계산이 오래 걸린다는 단점이 있습니다. 따라서, 이 방법은 소규모 환경에서는 좋은 성능을 보이지만, 더 크고 밀도가 높은 모델에 적용하기에는 제약이 있습니다. 또한 SIFT는 큰 illumination이 발생할때, robust성을 잃어버릴 수 있다는 단점이 있습니다.
Proposed approach
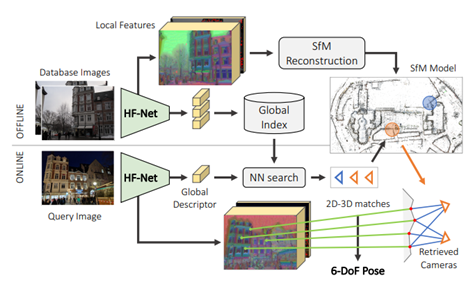
위와같은 문제들을 해결하기위해 저자는 SOTA를 달성한 Local feature를 뽑는 방법론과 image retrieval network를 combination함으로써 더 좋은 성능을 가지고온 방법론을 소개합니다. 그것이 바로 HFnet입니다. HFnet에서는 SIFT대신 Superpoint를 사용하여 local feature를 뽑아내고, 이는 SIFT보다 더 sparser 하기 때문에 real-time 6 DoF estimation을 하는데 더 유리합니다. 또한, 기존에 SOTA를 달성한 NetVLAD와 NetVLAD를 distill 한 Mobile-Net을 사용하여 computation time을 매우 빠르게 했습니다. 빠른 computation에도 불구하고, robust성까지도 잃지 않는 것을 다양한 데이터셋에서의 실험을 통해 검증했습니다. 그럼 이제 여러번 언급했던 HFnet이 어떻게 구성되어있는지 structure를 한번 보겠습니다.
HFnet
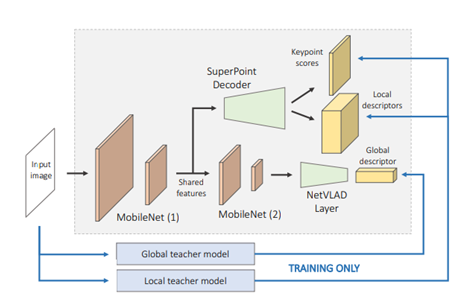
Hierarchical structure를 가진 HFnet의 파이프라인 입니다. 먼저 구성을 보시면, 한개의 싱글 인코더와 3개의 heads를 가지고 있습니다. 각각의 head는 keypoint detection score, dense local descriptors, global image wide descriptor를 예측합니다. 백본으로는 mobile기기에서 작동할수있도록 computation을 줄인 Mobilenet을 사용합니다. 2개의 Mobilenet을 거쳐서 나온 feature map에서 NetVLADlayer를 일종의 pooling layer로 사용합니다. 이렇게 NetVLAD layer를 거치고 나면 Global descriptor가 추출이됩니다. keypoints와 Local descriptor를 뽑는 방식으로는 당시 SOTA인 SuperPoint Decoder를 사용합니다. 1개의 Mobilenet을 거친 feature map은 SuperPoint Decoder를 거쳐 keypoint와 local descriptor로 decode됩니다. 이는 SIFT를 사용하는것보다 훨씬 빠르고 효율적입니다.
SuperPoint Decoder는 Mobilenet 1개를 거치고나온 feature map을 이용했습니다. 반면에 NetVLAD layer는 Mobilenet 2개를 거치고나온 feature map을 사용합니다. 이같은 이유는 Local에 관한 정보를 찾는 과정에서는 좀 더 spatial resolution이 높은 feature map이 사용되어야 하기 때문입니다. 그래야만 discriminative한 features를 얻을 수 있게됩니다.
Training process
Data scarcity
Local과 global descriptors는 주로 metric learning방식으로 학습이 됩니다. 이때 local patches와 full images에서의 ground truth positive와 negative paris를 사용하게됩니다. 그러나 이러한 GT correspodences값을 구하는것은 데이터셋의 한계로 상당히 힘듭니다.
Data augmentation
correspondence에 의존적이지 않음 SuperPoint와 같은 Self-supervised 방법을 적용하기 위해서는 heavy한 dataagumentation이 필요합니다. 그래야만 local descriptor가 invariance를 가질 수 있습니다. 하지만, data agumentaiton은 local 이미지에서의 다양성을 부여할 수 있지만, global 이미지의 연속성을 깨서 global descriptor를 학습하는데 좀 더 challenging하게 될 수 있습니다.
Multi-task distillation
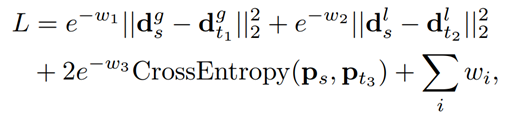
GT correspondences를 구하는 과정에서의 computational expense와 dataset의 한계 등을 고려해서 해당 논문에서는 Multi-task distillation이란 방법론을 학습방법으로 제안합니다. 위의 식에서 d는 descriptor, p는 key point score, w는 optimized variable를 의미합니다. 또한 t 하첨자는 teacher를 s 하첨자는 student를 의미합니다. 위와 같이 teacher networks로 부터 나온 값과의 차이를 loss로 사용하면 student에 해당하는 값들을 최적화 시킬 수 있게됩니다. 즉, 위와 같은 식을 loss로 사용하면 앞서 설명했던 문제들을 해결할 수 있습니다.
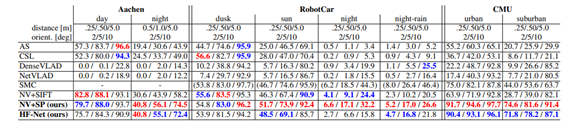
해당 방법론은 3가지의 다른 데이터셋의 day, night 이미지에 대해서 꽤나 괜찮은 성능을 달성했습니다.
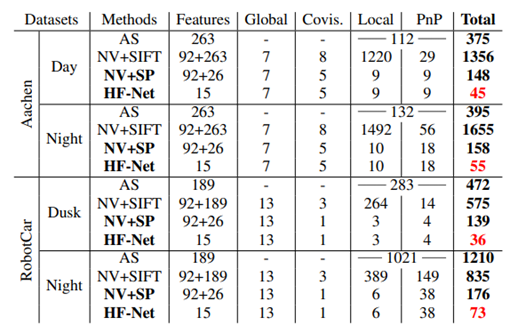
사실 robust성과 성능을 달성했다고 논문에서 소개하지만, 가장 큰 차이점은 바로 computation이라고 생각합니다. 위의 표를보면 HF-Net이 월등하게 빠른속도로 작동하는 것을 볼 수 있습니다. 빠른속도로 돌아가야 real-time 연산이 가능해지고 실제 일상생활에 적용이 가능해집니다. 그 점에서보면 큰 contribution이라고 생각합니다.
해당 논문에서 소개되는 방법론이 상당히 많았습니다. 그런 모든 방법론들을 다 공부해보진 못해서 이해하는데 상당히 오랜시간이 걸렸습니다. 그래도 최신 논문을 먼저읽으니 기존 방법론들중에 어떤한 방법론들을 공부해볼지 감이 잡히는 것 같습니다. 3D문제에 대한 관심과 image retrieval에 대한 학습을 위하여 읽은 논문이었는데 기본적인 컨셉을 잡는데 도움이 된거같습니다. 하지만, 해당논문에서는 reference로만 간략히 언급하는 teacher net과 SuperPoint 등에 대한 이해가 부족했던거 같습니다. 이에 어떤식으로 작동하는지 호기심이 생겨서 차후 학습할 생각입니다. 틀린곳있으면 지적해주시고 궁금증은 댓글로 달아주세요! 이상 리뷰 마치겠습니다.
정리하면 속도가 빨라진 이유가 SIFT대신 Superpoint를 사용하고 백본으로 MobileNet을 이용한게 전부인가요…? 그리고 결국 HFNet의 핵심은 local,global descriptor를 동시에 모델이 만들고 어떻게 보면 두 task가 충돌이 일어날수도 있는데 이를 multi task distillation으로 해결할 수 있다는게 신기합니다. 결국 transfer 방법도 일반적인 loss와 같아서 multi task를 학습하는데 충돌이 일어날거 같은데 해당 방법이 이를 방지하는 이유는 무엇일까요?
일단 속도가 빨라진 이유는 감히 그것이 “전부”라고 표현하겠습니다. 사실 “전부”라는 표현을 사용하는데는 상당히 조심스럽습니다. 항상 예외가 있을수 있기 때문입니다.
transfer 방법도 일반 loss와 같다는 표현이 이해가 안갑니다. transfer learning 방식을 얘기하는건가요? 만약 그렇다면 당연히 loss term은 같을 것입니다. 또한 transfer leaning 여부와 상관없이 충돌이 일어날것 같다고 하시는것은 해당 loss term이 convex하지 못하여 local minima로 수렴할수도 있을거같단 소리인가요? loss를 정의할때 local, global, teacher-student와의 관계를 모두 포함하여 정의하였고, 해당 loss term이 convex하다면 gradient를 계산해서 mobilenet의 파라미터를 업데이트 하는데는 지장이 없을거라고 생각합니다. 어찌됐든 mobilenet의 파라미터가 세가지(local, global, teacher-student관계)를 모두 포함한 loss를 떨어트리는방향으로 학습이 되는것이니깐요.
Covisibility clustering 으로 클러스트링으로 최적의 6 dof 를 찾는 알고리즘에 관한 설명이 빠진 것 같아서 아쉽네요 혹시 보충 설명해주실 수 있을까요?
해당 논문을 읽을때 알고리즘에 대한 설명을 읽은 기억이 없어서 다시 검토해본 결과 위에 제가 리뷰에 남긴 내용이 전부였습니다. 현재 계획상 6DoF관련 내용들을 다뤄볼 생각이라 조만간 관련내용을 포함하여 리뷰하겠습니다.
추가적으로 https://hello-stella.tistory.com/66 해당 링크 공유합니다. 구글링하다보니 해당논문을 한글로 리뷰한 글을 찾았네요. 읽어보시면 도움이 될거 같습니다.