지난시간 PoseCNN에 대해서 리뷰를 진행하였고, 오늘은 Dense Fusion에 대해서 리뷰를 진행하겠습니다. Dense Fusion에서의 Contribution을 소개하면 다음과 같습니다.
- RGB-D를 Fusion하여 6DoF를 예측하는 네트워크를 제안하였다.
- end to end의 iterative pose refinement procedure를 통해 6DoF 예측을 실시간으로 수행했다.
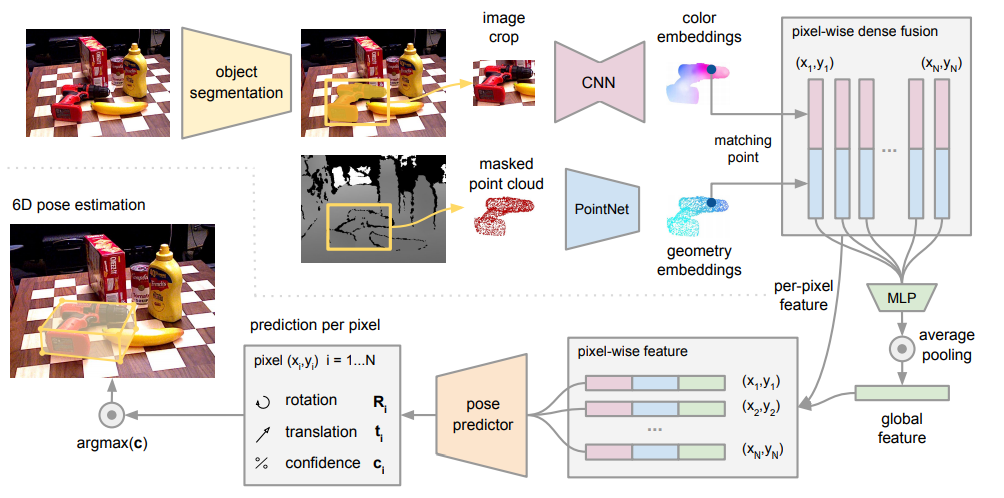
본 연구에서 제안하는 전체 네트워크 입니다. 부분별로 분석해보겠습니다.
Semantic Segmentation
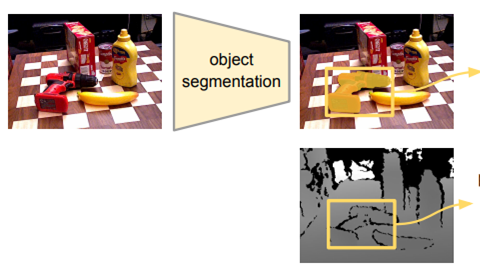
본 논문은 6DoF에 관한 논문이므로 Semantic Segmentation은 지난번 리뷰한 PoseCNN에서 사용한 네트워크 구조를 그대로 사용했다고 합니다.
The focus of this work is to develop a pose estimation algorithm. Thus we use an existing segmentation architecture proposed by [40].
Dense Feature Extraction
본 논문에서는 RGB, 3D point cloud를 Fusion하고 있습니다. 두 서로 다른 도메인의 영상을 Fusion하기 위해 두 영상을 각각 다른 네트워크를 이용해 Dense한 Feature를 추출합니다.
Dense 3D point cloud feature embedding
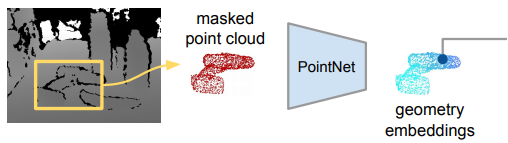
먼저 3D point cloud에서 Feature를 추출하기 위해서 사용한 네트워크는 PointNet입니다. PointNet에서는 Unordered input을 위해 symmetric 함수를 적용하였습니다. 여기서 symmetric 함수란 변수들의 위치(순서)가 바뀌어도 결과가 같은 함수를 의미합니다. (ex. f(x,y,z) = f(y,z,x)) 이러한 PointNet은 classification, segmentation, poseestimation 등 다양한 Task에서도 잘 작동함이 기존 연구들에서 나타났기 때문에 본 논문의 저자도 3D point cloud에서 Dense한 feature embedding을 얻기위해 PointNet을 사용했다고 합니다. 다만 masked point cloud마다 desne한 feature 추출을 위해서 일반적으로 PointNet에서 사용하는 Maxpooing대신 Average pooling을 사용했다고 합니다.
Dense color image feature embedding
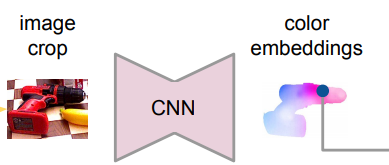
RGB 영상에서도 3D cloud point와 마찬가지로 픽셀마다 Dense한 Feature embedding을 얻어야 합니다. 또 이렇게 얻어진 feature embedding은 3D point와도 correspondences 해야 합니다. 이를 위해서 저자는 CNN 기반의 encoder-decoder 아키텍처를 만들었다고 합니다. 이를 통해서 H*W*3 을 H*W*d차원의 embedding space로 매핑시켰다고 합니다.
Pixel-wise Dense Fusion
앞서 RGB 영상과 3D point cloud에서 얻은 Dense한 Feature를 이제 Fusion 해야합니다. 가장 단순하게 두 영상의 segmented area에서 global feature를 생성하는 방법도 있지만, heavy occlusion과 segmentation errors가 있으면 앞선 단계에서 픽셀레벨 혹은 3D point 레벨로 피처를 만들었기 때문에 다른 object나 배경에 영향을 많이 받을 수 있습니다. 따라서 이는 성능저하의 원인이 될 수 있습니다. 이에 본 논문의 저자는 새롭고 효율적인 pixel-wise dense fusion network를 제안합니다.
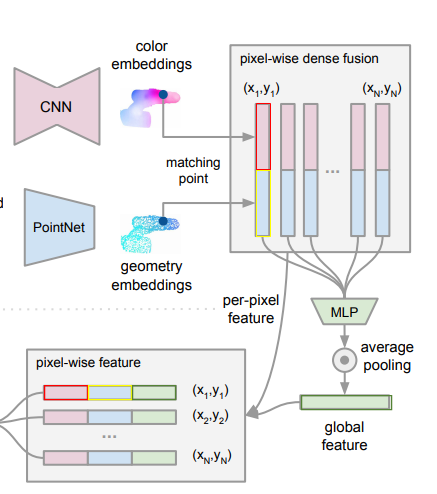
해당 논문에서 제안하는 dense fusion의 key idea는 픽셀레벨, 3D point 레벨로 기술한 feature를 local level에서 퓨전을 진행한다는 점 입니다. 이를 통해서 prediction하는 과정에서 object의 visible part를 선택할 수 있고, occlusion과 segmentation noise의 영향을 줄일 수 있다고 합니다. 다시 구체적으로 설명하면 3D point cloud를 카메라의 intrinsic parameters를 알고 있기 때문에 image plane으로 projection 시키고 이를 통해서 각 feature의 pair를 얻습니다. 그리고 각 pair된 feature를 concatenate하고 이를 통해서 고정된 크기의 global feature를 생산합니다. 이 global feature가 바로 Fusion된 feature를 의미합니다. 그리고 이 global feature를 기존 feature에 다시 합쳐서 최종적인 Feature를 만들게 됩니다.
이해를 돕기위해서 빨간색, 노란색, 초록색으로 한번더 표기하였습니다. 위의 그림에서 빨간색은 color embedding, 노란색은 geometry embeddings, 초록색은 두 feature를 합친 global feature를 의미합니다. 그리고 최종적으로 이 3개를 모두 concatenate한 pixel-wise feature를 만들게 됩니다.
6D Object Pose Estimation
지난번 PoseCNN을 기억하시나요?? 해당 논문의 그림을 잠깐 가지고 오자면 Semantic labels, 3D translation, 3D rotation을 모델을 통해서 예측했습니다. 본 논문도 이와 같이 앞에서 Semantic labels은 설명했으므로 이제 3D translation과 3D rotation을 모델을 통해서 예측합니다.
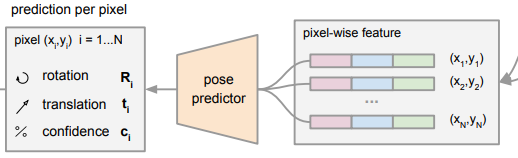
‘Pose predictor’의 출력을 보시면 Rotation과 Translatioin이 나타남을 확인할 수 있습니다. 이는 PoseCNN을 포함한 6DoF의 모델들과 동일합니다. 다만 차이점이라면 해당 모델의 출력은 pixel마다 R,t를 만들어내고 있습니다. 픽셀당 이를 prediction하기위해 본 논문에서 제안하는 Loss function은 다음과 같습니다.
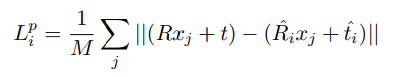
보시는것처럼 R,t에 3D point인 x를 계산한 것을 Loss로 설계하였습니다. 지난번 PoseCNN에서 R,t를 예측할때 object가 symmetric 인경우를 위해서 따로 설계했던 부분을 기억하시나요? 본 논문도 동일하게 symmetric object에 대해서는 동일한 방법으로 새로운 Loss를 적용합니다.
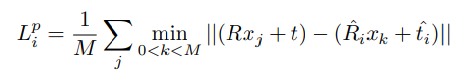
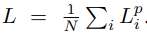
이렇게 설계한 Loss를 가지고 그냥 모든 픽셀에 대해서 평균을 구해서 Loss를 얻고 이를 backward 시키면 될까요? 본 논문에서는 각 dense-pixel간의 confidence 의 밸런스를 학습시키기 위해서 weight를 추가했다고 합니다.
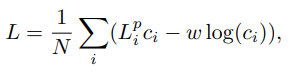
자세한 디테일의 대한 내용은 다시 확인해야하겠지만 결론적으로 confidence를 얻고 confidence가 높은 결과들만 이용해 Pose estimation을 수행한다고 합니다.
Iterative Refinement
앞서 설명한 내용은 실제 RGB-D를 Fusion하는 네트워크 그리고 Fusion이후 Pose를 Estimation 하는 방법에 대해서 이야기드렸다면 이제는 기존 PoseCNN에서 치명적인 단점이였던 ICP로 인한 속도 저하를 해결하는 방법입니다.
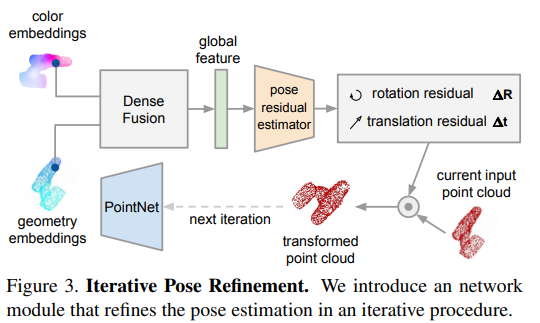
이 부분에 대해서는 약간 이해가 부족한 부분이 있습니다.. (추후 해결이되면 한번더 설명드리겠습니다.) 컨셉은 현재 모델이 예측한 R,t 값을 이용해 Current input point cloud를 transform 하고, 이를 다음 추론에 3D point cloud 입력으로 사용한다는 점 입니다.
Experiments
해당 논문에서 제안하는 방법론은 성능도, 속도도 가장 좋은 결과를 나타냈습니다. 평가는 PoseCNN과 동일하게 ADD, ADD-S로 측정하였으며 수치나열보다는 동영상으로 보여드리겠습니다.