본 논문은 제목에서 알 수 있듯이 영상(image, video)의 retrieval 문제의 해결에 관한 논문이다. 간단하게 작성자가 이해한 컨셉을 정리하였다. (이는 조원 연구원이 세미나와 x-review를 했던 논문입니다.)
본인이 읽으며 이해한 논문의 주요한 제안점은 다음과 같다.
“새로운 hashing method를 통한 효율적인 영상 검색”
Hashing
우선 본 논문을 읽으면 hash code, hash center 등 다양한 hash 관련 용어가 나오는데, 물론 알고리즘 수업에서 들어봐서 초면은 아니였지만 헷갈려서 읽기가 매끄럽지는 않았다. Conclution에서 논문은 새로운 “Hash Center”를 제안하였다 하였는데, 관련해서 보며 이를 정리해보자. 내가 알고있던 hash 알고리즘에서는 hash center라는 것이 명확하지 않았던것같다. 본인이 이해한 hash code와 center는 다음과 같다. 예를 들어 수지, 천우희, 고준희의 정보를 hash function을 통해 정보를 다음의 hamming space에 임베딩 한 값을 hash code라 한다(파란 점). 이때 이들의 hash center는 주황색 점이다. 이(hash center)는 hash 알고리즘의 hash function을 지난 후 나온 index와 유사하다고 이해하였다.
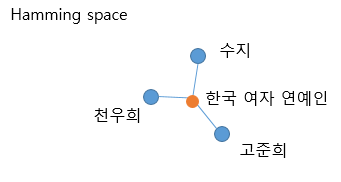
Hash center 생성
그러나, 논문이 제안한 hash center는 data기반이 아니다. 논문은 hash center를 특정한 조건을 만족시키도록 생성하였고, 이를 중심으로 잘 hashing을 하도록 hashing function(hash layer)을 학습시킨다.
hash center의 갯수가 임배딩할 hamming space의 차원보다 적거나 적절하면 mutually orthogonal 한 성질을 갖는 Hadamard matrix의 열벡터를 center로 하고, hash center의 갯수가 매우 많아 space가 포화되는 상황이면, 베르누이 방식으로 벡터를 생성한다. 자세한 알고리즘은 하단과 같다.

Central Similarity Quantization
마지막으로 CSQ는 deep-hashing methods 를 학습하는 방법론(이라 이해하였다. 간단하게 방향을 설명하면 다음과 같다. 데이터 x가 c’의 hashing center로 임배딩 된다 하자. 이때 x는 “커피”라는 클래스를 가진 영상이고, 이 label에 해당하는 선언된 hashing center는 c1이다. CSQ는 관찰된 사건 c’이 c1에 가까워지는 결과를 내는 방향으로 학습을 유도한다. 뿐만 아니라 미리 선언한 조건에 맞기 위해서는 hash center가 이진수 (0,1로 구성)되어야 하는데 이처럼 양자화 하기위한 loss또한 이용한다.
이 논문이 해결한점은 조원 연구원의 x-review에 잘 적혀있어 본 글에는 적지 않으려 했으나, 이를 추가하지 않으면 본 글에는 핵심이 없는 것 같아 다시한번 이곳에 정리한다.
제안하는 hashing method가 좋은 이유는
1. 기존의 triplet이나 pairwise처럼 pair로 움직이는 loss로 학습시키는 hashing method는 전체 영역의 데이터를 볼 수 없고, pair 기반이라 효율성도 떨어진다(다양한 조합이 있기 때문).
2. imbalanced한 data에 대해 좋지 못한 성능을 보인다. (전체 영역을 커버하지 못하기 때문.)
이는 다음의 그림으로 직관적인 이해가 가능하다.
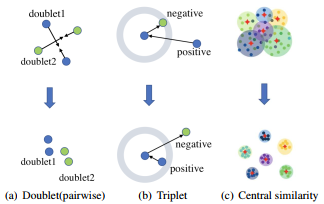
논문은 실제로 좋은 실험 성능을 보이고 있고, github도 공개되어있다. retrieval task를 수행할 때 참고하면 좋겠다.