
논문의 내용은 간단합니다. 새로운 Loss function 을 도입하여 Metric Learning의
Image retrieval 성능을 높힌것입니다.

Fast AP Loss
새로 도입한 loss function은 Fast AP Loss라고 명명하였습니다.
Average Precision의 정의부터 시작하여,
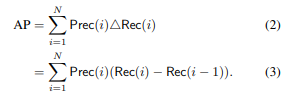
이를 학습에 적용하였을떄의 Precision과 Recall을 정의합니다.
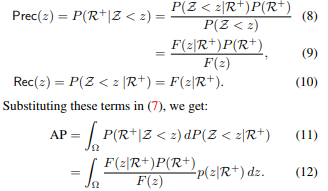
수학적용어가 많아 이해에 어려움은 있었지만, 논문의 설명이 비교적 자세하여 읽을땐 나름 이해가 되었습니다.
그렇게 FastAP라는 수식을 정의하고, 이에histogram을 적용하여 간단히 표현합니다.
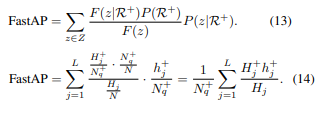
Optimization
이후, SGD를 이용하여 학습이 가능하다는것을 증명합니다. histogram에 linear interpolation을 적용하여 연속적인 수로 만들어, 미분가능하게 만듭니다.
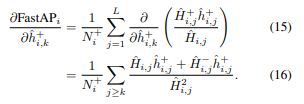
Mini batch Sampling
triplet loss를 사용할때와는 달리, AP loss와 같은 listwise loss는 한 학습(batch)에 여러장의 이미지가 들어간다. 따라서 이때의 이미지들을 선정하는 Minibatch Sampling 이 중요하다.
논문에서는, random으로 category를 골라 이미지들을 선정하는것이 아니라, 최대한 비슷한 카테고리의 이미지들을 학습시키는 방법을 제안한다. 또한 한번에 여러개의 카테고리가 아니라 유사한 적은 카테고리를 선정한다.
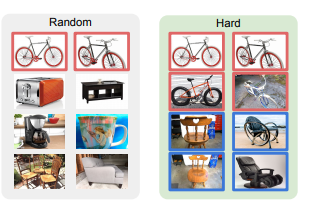
토스터기, 컵, 의자에서 자전거를 찾기는 비교적 쉽지만, 이와 비슷한 의자들에서 자전거를 찾는것은 비교적 어렵다. 이러한 카테고리의 유사성은 WordNet similarity를 통해 정보를 얻었다고 한다.
Experiments
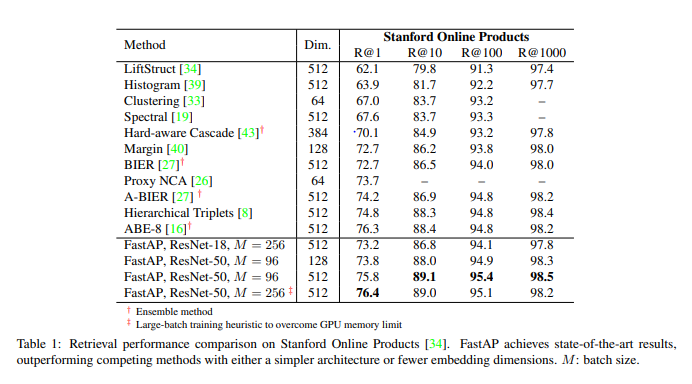
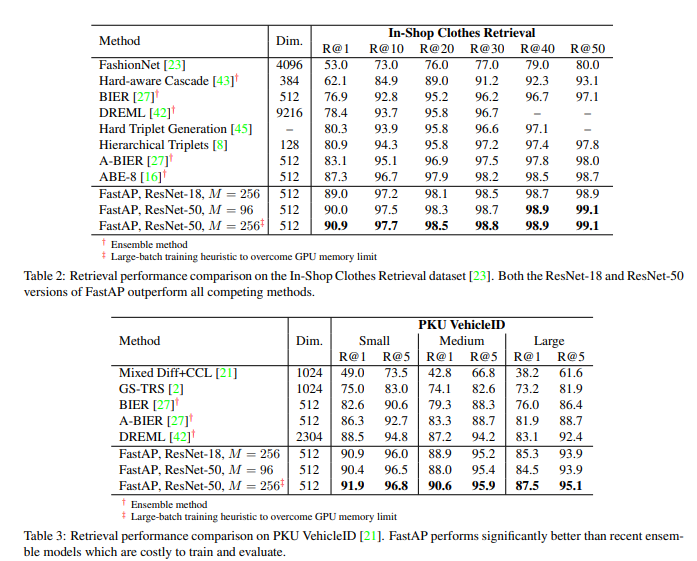
3개의 데이터셋에서 실험을 진행하였습니다. 각 데이터셋에서 모두 SOTA를 넘는 성능을 보입니다.
미니배치의 크기와, 앞서말한 히스토그램에서 bin의 수에 따른 성능을 실험했습니다.
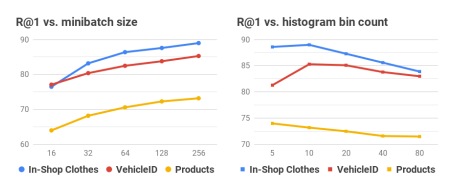
미니배치의 크기가 클 수록 성능이 높아지는걸 확인할 수 있었고, 히스토그램의 수는 10일때가 적당한것을 실험적으로 확인할 수 있었습니다.
FastAP Loss는 AP Loss의 개선버전인가요? 두 Loss의 가장 차이는 뭔가요? 그래서 어떻게 효율성을 극대화 했다는 거죠?