이번 리뷰도 역시 Colorization 관련 논문을 가져왔습니다. 하지만 이전에 논문들은 non-reference기반의 방법론들이었다면, 이번 논문은 exemplar-based라는 것이 큰 차이가 있을 것 같습니다.
Introduction
colorization은 아시다시피 gray 영상을 color 영상으로 만드는 것이 목표입니다. 간단하게 생각하면 colorization 역시 다른 task 처럼 GT(color image)와 predict 사이에 차이가 거의 안나게끔 loss함수를 설계하여 학습하면 되겠죠?
하지만 다른 task와 달리 colorization은 뚜렷한 정답이 없습니다. 예를 들어 사과를 찍은 흑백영상의 GT가 빨간색 사과일지라도, 모델이 해당 영상의 사과를 초록색 사과로 예측한다고 해서 틀렸다고 하기에는 애매한 것이죠.
그래서 colorization 기법들 중 일부는 종종 사람이 관여하여 영상의 결과에 중요한 영향을 결정하기도 했습니다.
위와 같은 방식은 일반적으로 2가지 형태로 나타납니다. 하나는 사람이 직접 colorization할 color를 guide 하는 방식이 있고, 나머지 하나는 참고 영상(reference image)를 같이 주는 것입니다.
먼저 사람이 직접 색을 지도하는 방식은 상당히 cost가 많이 들며 비숙련자들과 숙련자들 간에 결과 차이가 심하다는 단점이 존재합니다.

두번째 방식은 gray scale image와 유사한 color reference image를 주는 것인데, 먼저 두 영상간에 대응점들을 추출한 후에 가장 유사한 대응지점들의 색을 전파받는 것입니다.
하지만 이 방식은 reference image의 선택 방식에 따라 결과의 성능이 크게 차이납니다. reference와 target간에 조도, view point, 영상 내용의 비유사도 등이 심하게 차이날수록, colorization 결과 역시 크게 떨어지게 됩니다.
해당 논문에서는 이러한 reference image 방식의 단점을 보완하여 reference와 target간 유사성이 높지 않더라도 그럴듯한 colorization을 수행하는 모델을 제안합니다.
Contribution은 다음과 같습니다.
- Deep learning 기반의 Exemplar-based colorization method를 첨으로 제안.
- 신뢰성없는 reference 영상에 대해서도 그럴듯한 colorization 하기 위하여 2개의 가지 형식의 end-to-end 네트워크 구조를 제안.
- Reference 영상을 선택하기 위하여 Image retrieval 기법을 적용하였으며 이를 통해 오나전 자동의 colorization을 수행.
- 해당 방법은 비디오 colorization에도 확장가능.
Exemplar-based Colorization Network
해당 논문의 목적을 다시 한번 말씀드리면, reference image와 target(gray) image간에 의미적으로 관련있는 지점에서의 reference color를 target(gray image)에 적용시키는 것 입니다.
그리고 reference 영상과 관련없는 영역에 대해서는 그럴듯한 색상으로 colorization을 하는 것이구요.
이러한 목표를 달성하기에는 크게 2가지 어려움이 존재합니다.
먼저 첫번째는 reference image와 target image간에 의미있는 관계를 측정하는 것이 쉽지 않습니다. 그 이유는 한쪽 영상은 color 영상이고, 나머지 영상은 gray 영상이기 때문이죠.
이러한 문제를 해결하고자 해당 논문에서는 영상 분류를 진행하기 위해 밝기 채널을 이용하여 학습된 gray-VGG-19 pretrained model을 사용하였습니다.
둘째로, reference color를 선택하여 이를 전파하기 위해 similarity metric을 기반으로 한 hand-crafted rule을 규정하는 것은 상당히 어려운 작업이라고 합니다.
이를 위해 해당 논문에서는 color를 선택하고 전파하는 것을 동시에 학습하는 end-to-end 형식의 네트워크를 제안합니다.
종종 선택과 전파를 하는 것은 모든 색상을 다루지 못할때가 있습니다. 특히 reference 영상과 target 영상간에 유사도가 크게 떨어질 때 그럴 가능성이 커집니다.
이러한 문제를 해결하고자 제안되는 네트워크는 방대한 양의 데이터로부터 그릇된 물체에 대한 dominant color를 예측해서 사용한다고 합니다. 예를들어 아래 그림에서 빨간 경계선 영역은 reference 영상과 관련성이 없는 영역이기 때문에, dominant color로 predict 합니다.

전체적인 네트워크 구조는 아래와 같습니다.
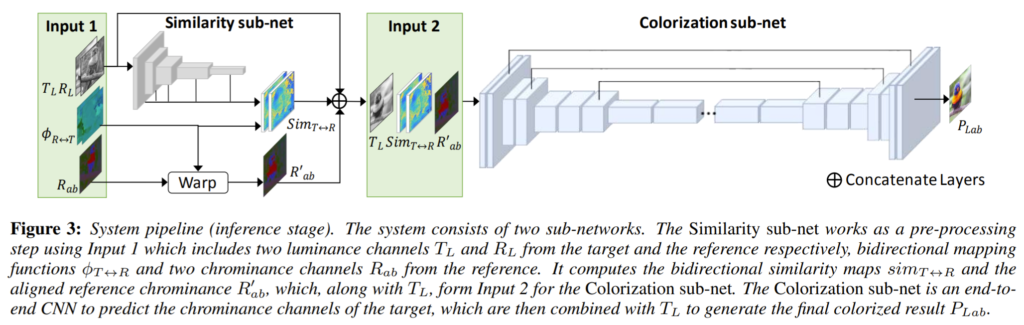
먼저 Lab color sapce를 사용하며, Target 영상과 reference 영상, 그리고 양방향 맵핑 함수를 입력으로 사용한다고 합니다.
여기서 양방향 맵핑 함수는 spatial warping function으로 target과 reference 간에 양방향에 대한 correspondence를 가지고 정의됩니다. 해당 함수는 source location ‘p’에 대하여 변환된 location을 반환합니다.
맵핑함수에 대한 표기 \phi_{T\rightarrow R}는 target으로부터 reference에 픽셀을 맵핑한다는 의미이며 \phi_{R\rightarrow T}는 그 반대입니다.
모델 구조는 크게 2가지 네트워크로 이루어져있는데 하나는 Similarity sub-net이고 다른 하나는 Colorization sub-net입니다.
간략히 설명하자면 Similarity sub-net은 end-to-end 형식의 colorization network의 입력을 제공하기 위한 전처리 단계의 네트워크로 reference와 target 사이의 의미있는 유사성을 계산하여 양방향 유사성 맵을 출력으로 합니다.
Colorization sub-net은 reference와 target image간에 유사성이 높든 작든 일반적인 colorization 결과를 제공하기 위해 2개의 서로 다른 가지로 학습되는 multi-task learning을 진행합니다.
Similarity Sub-Network
pixel-level로 유사성을 계산하기전에, 먼저 Target과 ref 영상간에 align이 되어야만 합니다. 그래서 추가적인 입력으로 bidirectional mapping function이 들어가게되는데, 이때 해당 mapping function은 SIFTFLow나 DeepFlow와 같은 dense correspondence algorithm을 사용하여 계산할 수 있다고 합니다.
해당 논문에서는 그 당시에 가장 최신 기법인 Deep Image Analogy를 이용하여 mapping function을 계산하였는데, 해당 Deep image Analogy는 두 영상이 시각적으로 다를지어도 의미적으로 관련있는 경우에 사용가능하기 때문에 채택했다고 합니다.
Similarity Sub-Net은 CNN기반의 Image recognition task에 영감을 받았다고 합니다. 그래서 VGG-19를 통해 feature를 표현하였습니다.
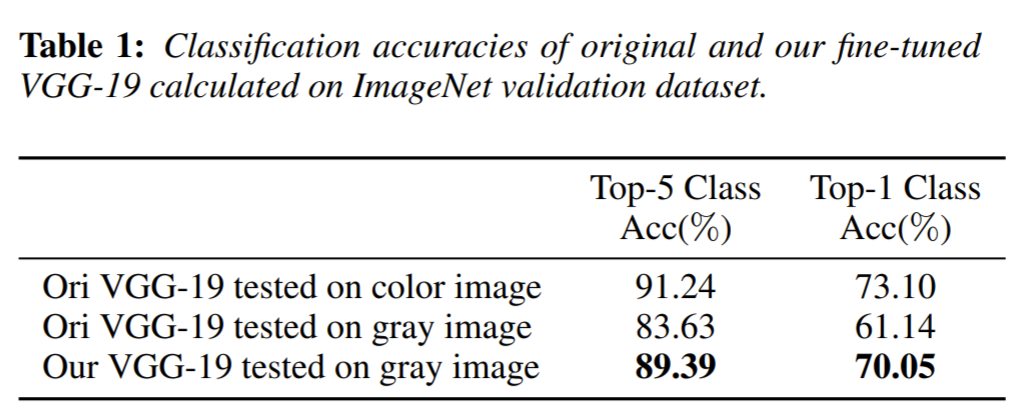
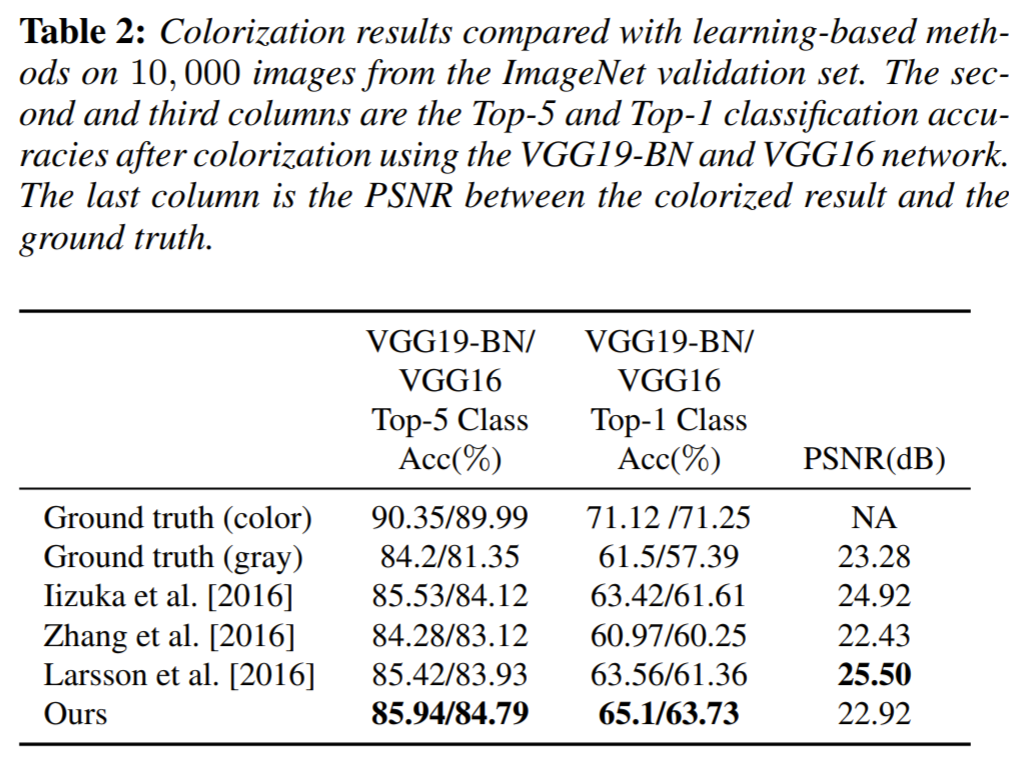
이때 VGG-19의 경우 color image로 pre-trained 됐기 때문에, gray 영상을 분류하는 경우 위의 테이블과 같은 성능 차이가 발생하게 되는데 이를 해결하고자 color 영상의 밝기값만을 이용하여 fine tuning했다고 합니다.
그 다음에 해당 VGG-19에다가 T_{L} 과 R_{L}를 입력으로 넣어 각각의 five-level feature map을 피라미드 형식으로 구합니다.
각각의 feature map들은 relu를 통과하여 나왔으며 점진적으로 더 강한 공간적 해상도를 지니고 있습니다. 이러한 feature들을 입력 영상과 모두 동일한 해상도로 up-sampling 하였으며 이를 각각 F^{i}_{T_{L}} 와 F^{i}_{R_{L}} 로 나타냅니다.
양방향 similarity map sim^{i}_{T \rightarrow R}, sim^{i}_{R \rightarrow T} 는 다음과 같은 수식을 통해 계산됩니다.
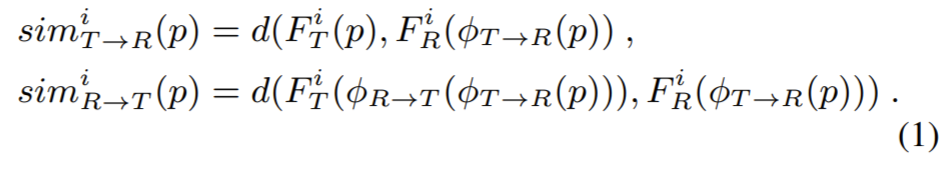
여기서 d는 similarity metric으로 pair 영상간에 생김새로부터 강인하여 feature 유사성을 잘 측정해주는 cosine similarity를 사용했다고 합니다.
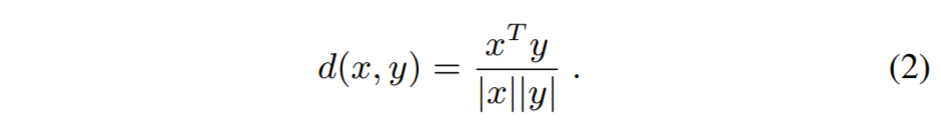
Colorization Sub-Network
Colorization network는 input으로 target image, chrominance channel만을 가지는 reference image, 마지막으로 similarity sub net에서 구한 양방향 similarity map을 concat하여 총 13개의 채널 map을 사용합니다.
그리고 출력은 target image에 대하여 예측한 ab channel map이죠.
Loss
기존 학습 방식의 colorization method들은 단순히 예측한 color map P_{ab}에 대하여 GT인 T_{ab}에 최대한 동일하게 되게끔 loss function을 설계하고 학습했습니다.
하지만 아까 리뷰 처음에서 사과를 예시로 들며 설명드렸다시피, 물체에 대하여 정해진 딱 하나의 유니크한 정답을 가진 색상은 없기 때문에 그러한 loss function들은 잘못되었다고 말합니다.
해당논문에서는 loss function의 목적으로 신뢰성있는 reference color를 가져오며, 만약 reference color를 가져올 수 없다면, 가장 자연스러운 colorization을 할 수 있게끔 설계하였다고 합니다.
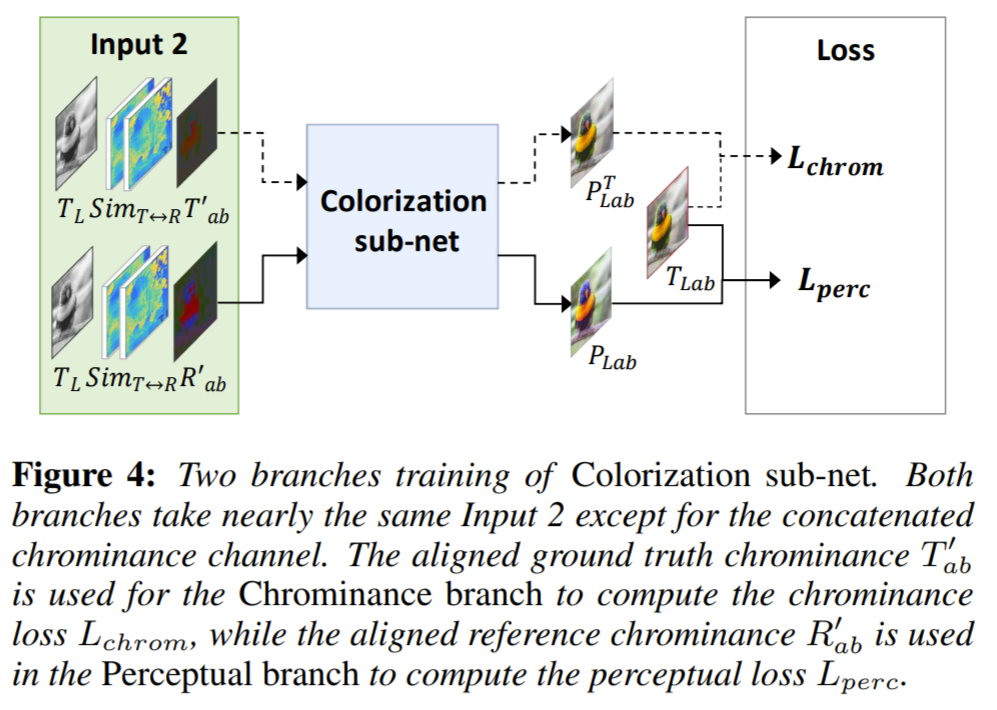
이를 위해서 네트워크를 2개의 브랜치(Chrominance branch, perceptual branch)로 나뉘는 네트워크로 설계하였으며, 각 브랜치는 동일한 네트워크 C와 weight \theta 를 공유하지만, fig 4처럼 각각 고유의 입력과 loss function을 사용한다고 합니다.
Chrominance branch loss
먼저 Chrominance branch의 경우, 해당 네트워크 올바른 reference color를 선택적으로 전파하는 것을 학습해야합니다. 이는 얼마나 target 영상과 reference 영상이 잘 매칭됐는지에 의존합니다.
하지만 이러한 네트워크를 학습하는데는 큰 어려움이 존재합니다. 먼저 target 영상의 warping된 reference chrominance R'_{ab}를 가지고 direct로 학습하기에는 대응되는 GT가 존재하지 않아서 불가능하다고 합니다.
반면에 target chrominance의 gt인 T_{ab}를 reference로 사용하게 되면 이는 예측의 정답을 이미 줘버리는 것이기 때문에 학습에 사용할 수 없게 되는 것이죠.
이를 해결하고자 논문에서는 양방향 mapping 함수를 이용하여 gt chrominance로부터 fake reference T'_{ab}를 재구성하였다고 합니다.
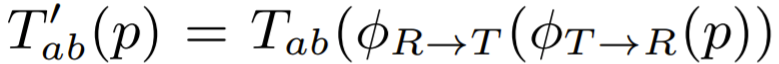
T'_{ab}는 R'_{ab}를 대체하여 학습에 사용되며, T'_{ab} 안에 올바른 color sample들은 R'_{ab}의 올바른 color sample들과 동일 선상으로 보게됩니다.
chrominance branch를 학습하기 위해 T_{L},T'_{ab} 둘 다 입력으로 하며 이를 통해 P^{T}_{ab}를 output으로 구하게 됩니다.
여기서 P^{T}_{ab} 는 T'_{ab}를 참고하여 colorization된 결과를 말하며, 만약 네트워크가 올바른 컬러 샘플을 골라서 전파하였다면 GT인 T_{ab}와 유사하게끔 만듭니다.
즉 P^{T}_{ab} 와 T_{ab} 를 유사하게 하기 위해 smooth L1 loss를 사용하였으며 아래 수식과 같이 전체 영상에 대하여 계산하게 됩니다.
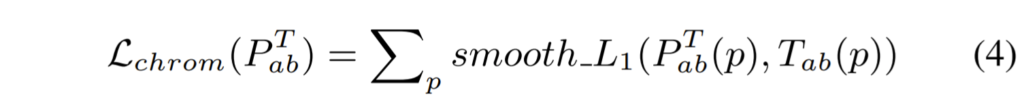
Perceptual loss
Chrominance branch는 오직 신뢰성있는 color sample에 대해서만 작동하기에 reference와 target간에 유사성이 떨어지는 경우에 대해서는 잘 동작하지 못합니다.
이를 해결하기 위해 Perceptual branch를 설계하였으며, 해당 브랜치는 R'_{ab}와 target T_{L}를 네트워크의 입력으로 받습니다.
그 다음에 predict chrominance P_{ab}를 생성하게 됩니다.
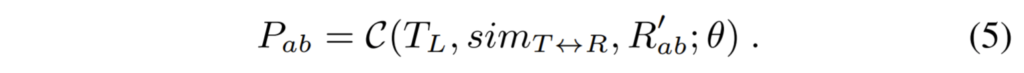
해당 branch에서는 Perceptual loss로 [Johnson et al.2016]을 사용하였으며 수식은 아래와 같습니다.
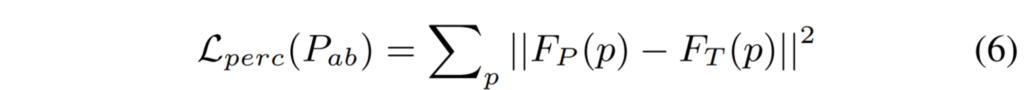
여기서 F_{p}는 P_{Lab}에 대하여 original VGG19 relu5_1 layer를통해 추출된 feature map들을 의미하며, F_{T}는 위와 마찬가지로 VGG19에 T_{Lab}를 input으로한 것입니다.
Perceptual loss는 자연스럽지 못한 colorization으로 인해 발생된 semantic difference를 측정하고, 영상 속 외관에 차이에 대해서는 강인한 모습을 보입니다.
전체적으로 네트워크 C는 chrominance loss와 perceptual loss 양쪽을 최소화하는 방향으로 학습합니다.
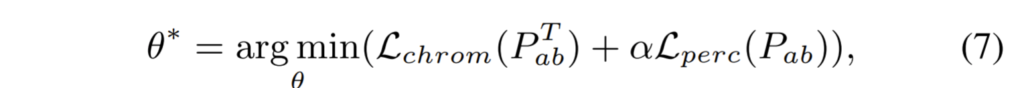
Experiments
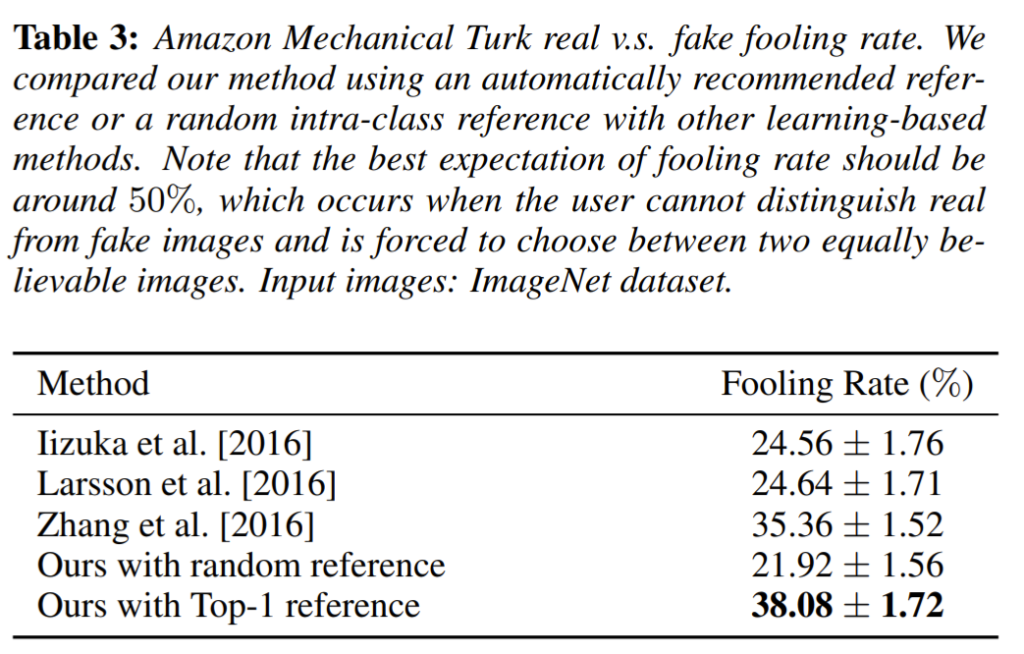
성능 평가 지표는 지난번 리뷰로 작성한 Colorful Image Colorization(http://server.rcv.sejong.ac.kr:8080/2020/10/18/colorful-image-colorization/)과 상당히 동일합니다. 각각의 방법론들로 colorization한 영상을 VGG classifier에 넣어 성능이 얼마나 개선됬는지 여부와, 사람에게 real image와 fake colorization image를 비교하는 테스트에 대한 성능 지표를 제공합니다.
아래는 정성적인 결과입니다.
