안녕하세요, 이번 x-review에서는 제가 이번주에 공부했던 내용중에 Neptune, Github를 다루겠습니다. 사실 이 리뷰를 작성하기에 앞서 “From Coarse to Fine: Robust Hierarchical Localization at Large Scale” 이란 제목의 논문에 대한 review를 3시간정도 투자하여 작성하고있었으나… 생각보다 내용이 많아서 오늘내로 마감을 못하겠다는 생각이 들어서 이미 익숙한주제로 x-review를 쓰겠습니다. 해당 논문에관해서는 초안만 비공개로 게시해둔 상태이며, 충분한 학습을 마치고 다시 이어쓰겠습니다. 그리고 Neptune, Github를 주제로 x-review를 작성하는 것이 도움이될 분들이 더 많을거라고 생각합니다. Github에 관해서는 이번에 구매한 도서목록중에 Git에 관련된 책이 있었는데 해당 책을 절반정도 정독했습니다. 아직 다 읽지는 못했지만 코업을 하는데 내용은 충분히 파악됐다고 생각되어서 간략하게 다루겠습니다. 즉, 해당 리뷰의 본주제는 Neptune입니다. 그렇게 정한 이유는 이미 많은 분들이 Git에는 어느정도 친숙하지만, Neptune은 출시된지 오래되지 않아서 처음 들어봤을 가능성이 크기 때문입니다. 그럼 리뷰 시작하겠습니다.
What is Neptune?
넵튠이라는 것에 대해 들어보신적이 있으신가요? 2020 Google Landmark Challenge의 1st place를 차지한 winner의 인터뷰를 보면 Neptune을 사용했다는 것을 알 수 있습니다. 해당 winner는 senior engineer로 나이가 좀 있으신 분이셨기에 최신 프로그램들을 배우는 취지에서 챌린지를 진행했다고 하였습니다. 그중 하나가 Neptune이었습니다. 그렇다면 Neptune이 무엇일까요? 쉽게말해서 Neptune은 Tensorboard와 비슷한 시각화 도구입니다. 각종 설계한 모델을 실험들을 할때 사용한 parameters 와 arguments들, output등 을 웹브라우저상에 저장하고 이를 시각화 할 수 있습니다. 사용법이 그리 어렵지 않고 tutorial 까지 친절하게 제공하고 있으므로 상당히 괜찮은 tool이라고 생각합니다.
https://neptune.ai 먼저 해당 사이트에 들어가시면 Neptune에 회원가입 할 수 있습니다. 회원가입 절차는 간단하기에 생략하겠습니다.
사이트에 잘 찾아보시면 tutorial 동영상, github, documents, Neptune에 대한 소개글 등이 수록되어 있습니다. 사실상 그것들을 보고 직접 실습해보는게 Neptune을 이해하는데 가장 도움이 될 것입니다. 제가 쓰는 이 리뷰는 tutorial이 아닌 실제로 어떻게 Neptune이 적용되는지 네이버챌린지 indoor팀 코드에 적용해보고, 어떠한 이점이 있는지에 대한 소개글입니다. 직접 실무에 적용하고 싶으신분들은 tutorial 부터 차근차근 해보시길 권장드립니다.
기능소개
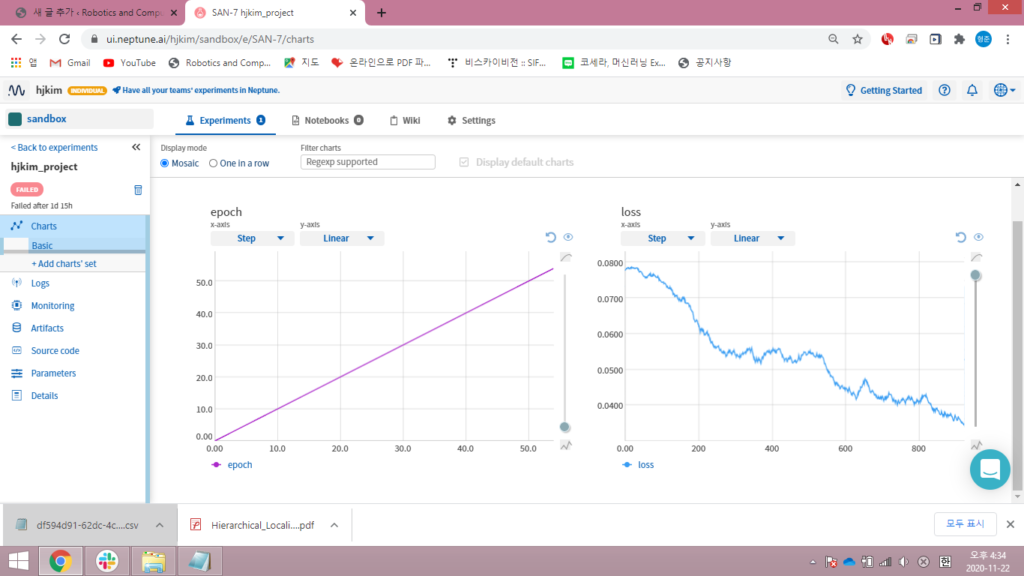
먼저 Neptune에서 가장 큰 기능인 visualization 부분 입니다. 해당 그래프는 indoor팀의 코드를 돌렸을때 loss 그래프를 실시간으로 받아온 그래프입니다. 또한 왼쪽의 그래프는 epochs수 입니다. 이렇게 받아올 변수를 코드단에서 지정해서 그래프화 할 수 있습니다. 또한 해당 변수들을 csv파일로 다운로드 할 수 있습니다.
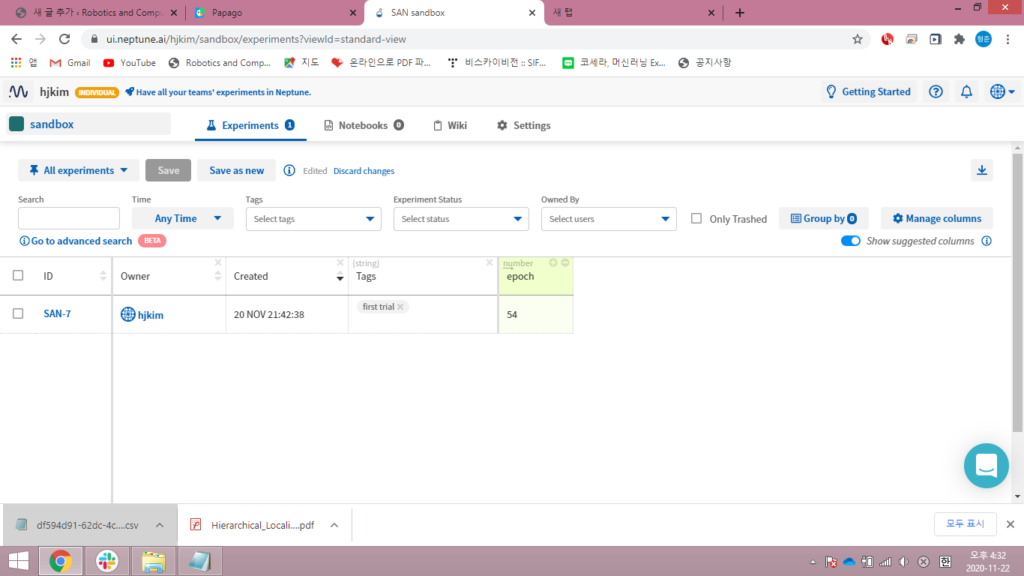
이번 기능은 experiment를 하는 기능입니다. 말그대로 실험을 할때 setting해두었던 변수들, 조건들을 주석과 함께 저장할 수 있습니다. 저장된 날짜, tag(꼬리표), 저장한 사람, 프로젝드ID등이 같이 저장됩니다. 이때, 저장할 변수 및 조건을 지정할 수 있습니다.
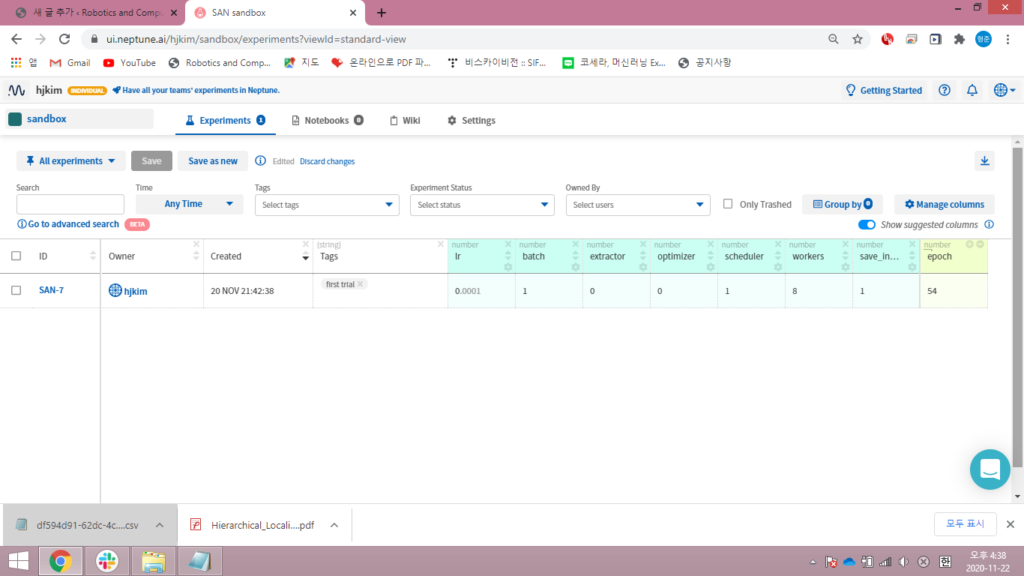
몇몇개의 변수및 조건들을 추가해보았습니다. 해당 예시에서는 숫자로만 받아왔는데 str형식또한 지원을 합니다.
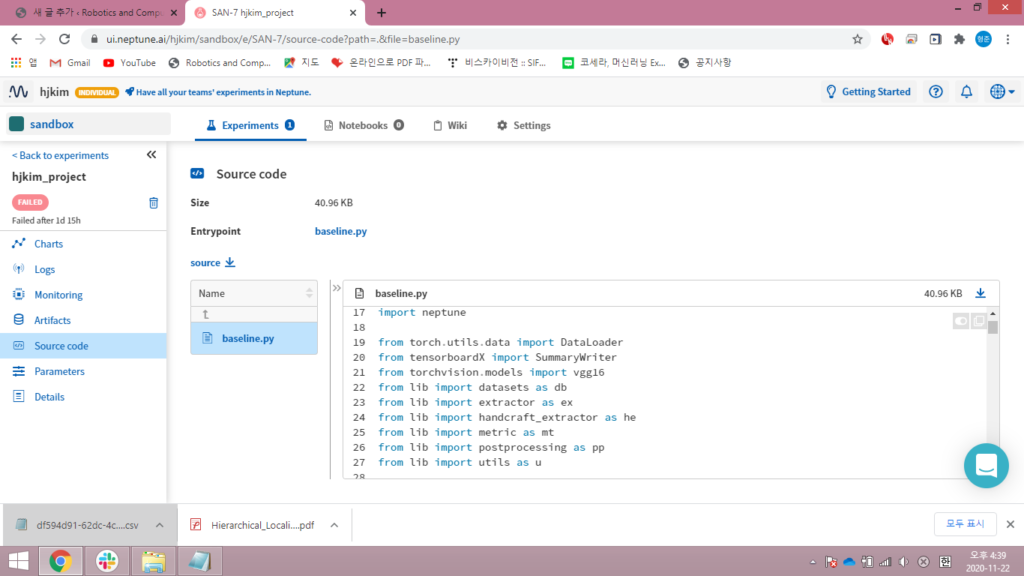
해당 실험을 했을 당시와 코드가 변할 수 있기 때문에 code를 백업해두는 것도 가능합니다. security issue에 대한 concern으로 privacy-policy를 읽어보았더니, “Neptune Labs ensures that all source code, files and data remain private and confidential. Due to the sensitive nature of source code we take this very seriously and make it our primary concern for all customers. ” 라고 수록되어있었습니다.
만약 코드가 정상적으로 실행되지 않으면 오류메시지에 대한 로그도 남습니다. 해당 예제에서는 ctr+c를 눌러 강제 종료하여 pop up된 오류메시지가 로그로 남았습니다. 이제 기능에 대한 간략한 소개가 끝났습니다. 그렇다면 적용하기는 어떨까요?
import neptune
# Neptune parameters
api_token="ANONYMOUS",
project_qualified_name='사용자명/저장소이름'
api_token='API 토큰 번호'
upload_source_files = 'baseline.py' #백업할 파일 지정
# Neptune initialize
neptune.init(
api_token=api_token,
project_qualified_name=project_qualified_name,
)
def create_exp(name, params, upload_source_files):
neptune.create_experiment(
name=name,
params=params,
upload_source_files = upload_source_files
)
def create_tag(tag):
return neptune.append_tags(tag)
def create_log_metric(name, val):
return neptune.log_metric(name, val)여기 까지가 간단한 초기 설정입니다. 해당 코드는 좀더 직관적으로 보기위해 제가 만들었으며, 사이트의 tutorial을 참고하면 좀더 깔끔한 예시들이 있을수 있습니다. 그 예시들을 참고하시고 코드에 적용하셔도됩니다. 이제 눈여겨 보고싶은 parameter들을 정의할 차례입니다. 아래에서 예시코드로 확인해보겠습니다.
# parameters 정의
params = {'seed':args.seed,'image_size':args.image_size,'normalize_mean':args.normalize_mean, 'normalize_std':args.normalize_std, 'batch':args.batch, 'shuffle':args.shuffle, 'workers':args.workers, 'epochs':args.epochs, 'lr':args.lr, 'save_interval':args.save_interval, 'save_root':args.save_root, 'ckpt_path':args.ckpt_path, 'save_folder':args.save_folder, 'valid_interval':args.valid_interval, 'train':args.train, 'test':args.test, 'valid':args.valid, 'valid_sample':args.valid_sample, 'qualitative':args.qualitative, 'cluster':args.cluster, 'pca':args.pca, 'pca_dim':args.pca_dim, 'tuple':args.tuple, 'neg_num':args.neg_num, 'cen_crop':args.cen_crop, 'topk':args.topk, 'db_save':args.db_save, 'db_load':args.db_load, 'pose_estimation':args.pose_estimation, 'pose_pointcloud_load':args.pose_pointcloud_load, 'pose_covisibility':args.pose_covisibility, 'pose_noniter':args.pose_noniter, 'pose_cupy':args.pose_cupy, 'pose_timechecker':args.pose_timechecker, 'lmr_score':args.lmr_score, 'topk_load':args.topk_load, 'topk_save':args.topk_save, 'rerank':args.rerank, 'pose_ld':args.pose_ld, 'positive_selection':args.positive_selection, 'dataset':args.dataset, 'optimizer':args.optimizer, 'scheduler':args.scheduler, 'extractor':args.extractor, 'handcraft':args.handcraft, 'searching':args.searching, 'metric':args.metric}
create_exp(name = 'hjkim_project', params = params, upload_source_files = upload_source_files)
create_tag('first trial')params라는 dictionary에 눈여겨 보고싶은 실험조건들을 담았습니다. 그렇다면 매번 변하는 변수들은 어떻게 받을까요?
create_log_metric('loss', loss)위와 같이 간단하게 받을 수 있습니다. 해당 코드의 의미는 loss라는 변수를 loss라는 이름으로 Neptune 서버에 저장하는 것 입니다. 이때 loss는 iteration마다 값이 변하므로, iteration에 따른 graph를 plot하는 것도 가능하고, csv파일로 다운로드하는 것도 가능합니다.
이렇게 간략하게 Neptune 사용법에 대해 알아보았습니다. Again, Neptune 사이트를 들어가면 더 친절한 tutorial code와 설명이 나와 있습니다. 제 리뷰는 소개글로만 생각하시고 해당 tutorial code및 동영상을 참고하시는게 best임을 다시한번 remind해 드립니다.
Github
이제 깃허브에 대해서 알아보겠습니다. 리뷰를 시작하기전에 언급했듯이 해당 리뷰는 Neptune에 주안점을 두고있습니다. Github는 이번에 구매한 도서에 대한 리뷰 느낌으로 짧게 작성할 생각입니다.
가장 간단한 Git은 아래와 같은 순서로 작동합니다.
- git init
- git add 파일명
- git commit -m 설명
- git push
먼저, 프로젝트가 진행중인 폴더에 git폴더를 생성해줍니다 그 과정이 git init입니다. 이 후 업로드하고싶은 파일을 git add로 추가해준다음 commit해주면 로컬환경에 upload가 완료됩니다. 이를 원격저장소(git hub)에 push 해주면 자신의 코드를 최신화 할 수 있습니다.
Branch, pull request
Git에서는 branch를 만들 수 있고, 각 프로젝트를 fork해서 평행우주를 구성하는 것이 가능합니다. 자세한 내용은 이번에 구매한 책에 실려있지만 간략히 소개하겠습니다.
먼저 branch는 말 그대로 줄기입니다. 기본적으로 master branch가 default 이며, branch를 추가적으로 만들 수 있습니다. 코업을 할때 branch는 다음과 같이 활용됩니다. (가장 간단한 예시일 뿐입니다.)
- 개발자 철수와 영희가 코업을 한다고 가정
- 철수는 고수, 영희는 초보 개발자 임
- 메인프로젝트는 master branch에 철수는 chulsu브랜치에 영희는 yeonghi 브랜치에서 작업을 진행
- 각자 만든 코드들을 master branch에 병합하여 코드를 구성해 나감
- 이때, 영희는 철수의 허락을 받아야만 master branch에 병합을 할 수 있음. 이것을 pull request라고 함.
- 철수는 영희의 pull request를 통해 영희가 구성한 코드를 확인하고 master branch에 병합함. 이 과정에서 코드가 conflict(충돌)이 나는지 확인을 해야함.
- 해당 과정을 통해 분업하여 master branch를 만들어 나갈수 있음
이게 branch에 대한 개념입니다. 그렇다면 fork와 평행우주? 이런말들은 어디서 나온것 일까요? 먼저, master branch에 대한 접근권한을 여러명에게 주는것은 담당 개발자에게 큰 부담일 것입니다. 위의 예시에서 철수와 영희는 서로 사수, 부사수 관계라고 합시다. 그렇다면 더 많은 사람이 코업을 하기위해서는 어떠한 방식이 있을까요? 바로 오픈소스로 코드를 공개하는 것 입니다. 소스를 공개해두면 관심있는 개발자들이 stat표시(좋아요)를 할 수도있고, fork하여 자신의 repository에 저장하여 원하는 기능을 추가하고 메인 개발자인 철수에게 pull request하여 contribution을 할 수 있습니다. 실제로 이와같은 방식으로 많은 코드들이 오픈소스로 공개되어있고, 많은 개발자들이 Github라는 플랫폼을 통해서 협업하고 있습니다. 이렇게 project 전체를 fork해오는 것을 평행우주를 구성한다고 합니다.
소스트리
소스트리는 git을 시각화하는 도구입니다. 다만 서버와 연동하면 상당한 랙(lag)이 발생합니다. 그럼에도 불구하고 Git을 이해하는데는 상당한 도움이 되므로 입문으로 사용하기를 권장드립니다. 해당 책에서도 소스트리와 깃명령어를 동시에 비교해가며 설명을 하고 있습니다. 매우 친절하게 step by step으로 설명이 진행되므로 이해를 하는데 상당한 도움이 될 것입니다. 또한 Github로 Q&A도 받아주고 있으므로 활용해보시길 권장드립니다. 아무튼, 소스트리를 활용하면 branch를 가시적으로 볼 수 있습니다.
번외로 Git의 branch를 병합하는 과정에서는 총 3가지가 있습니다. 병합과정에서 conflict가 발생하면 어떤식으로 해결하는지에 대한 정보도 책에 수록되어있습니다. (코드가 바뀐부분을 가시적으로 알려줍니다)
이 밖에도 다양한 내용들이 있었지만 해당 부분까지만 읽어도 일단은 코업을 하는 환경에 큰 지장이 없으므로 다른공부를 우선순위로 두었습니다. Git branch, fork, init, push, pull, master branch, origin등에 대한 이해를 하기에 도움이 되었던 책 이므로 한번 읽어보시는 것을 추천드립니다. 이상 리뷰 마치겠습니다.
꼭 연구개발을 진행하면서 git을 적극적으로 활용해보길 바랍니다. 책으로 보는 것보다 실습해야 늘겁니다.
좋은 말씀 감사합니다. 해당 책에서 실습위주로 진행을 하고 있어서 따라해보니 확실히 도움이 많이 되었습니다. 하지만, 실전에서의 실습은 아직 부족한것이 사실입니다. 앞으로 프로젝트를 진행할때 깃을 활용해볼 생각입니다.
유용한 툴이네요 당장 사용해보겠습니다.