Chao-Yuan Wu1,2 Christoph Feichtenhofer2 Haoqi Fan2 Kaiming He2 Philipp Krahenb ¨ uhl ¨ 1 Ross Girshick2 1The University of Texas at Austin 2Facebook AI Research (FAIR)
이번 1편에서는 deep 하지 않게 큰 흐름에서 이러한 논문이 나오게된 컨셉만 소개해드리려고 합니다.

보통 video를 가지고 하는 task에서 3D CNN model에는 전체 영상의 길이와 관계없이 input으로 정해진 frame 개수만큼(보통 16개)이 들어가게 됩니다.
예를 들어 MFNet의 경우 모델이 다음과 같이 설계 되있습니다.
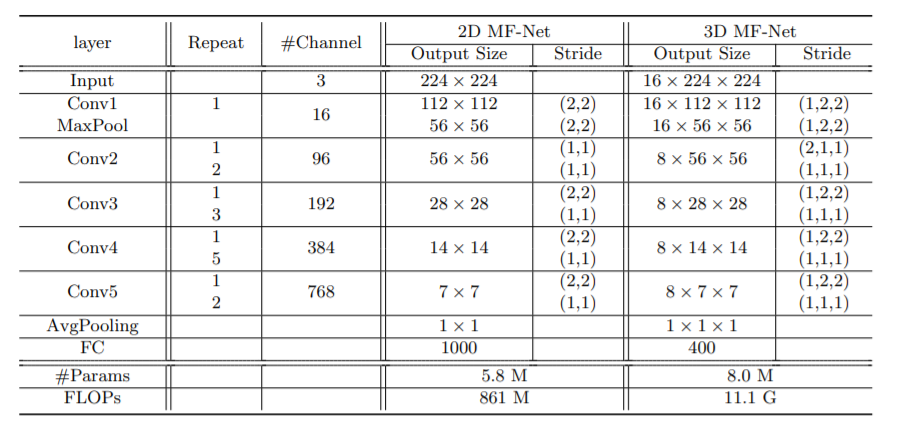
input의 16*224*224가 보이시나요?

이 프레임 개수 N에 대한 성능은 당연히 많이 쓸수록 좋을것 같아 보입니다.
하지만 기존 3D CNN모델은 N이 어느 순간 까지 커지면 그다음부터는 성능이 하락하는 모습을 보입니다.
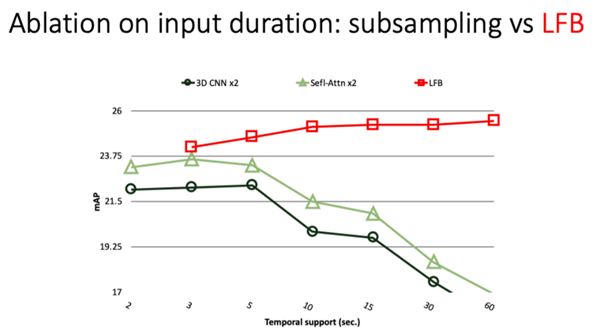
그 이유를 이 논문에서는 기존 3D CNN은 Long term feature를 표현하는 능력이 떨어진다라고 합니다.
그래서 길이가 점점 길어지는 동영상 모델에는 더이상 기존과 같은 frame을 subsampling 하는 방식이 아닌 다음과 같은 Long term feauture를 도입해야 한다고 주장합니다.
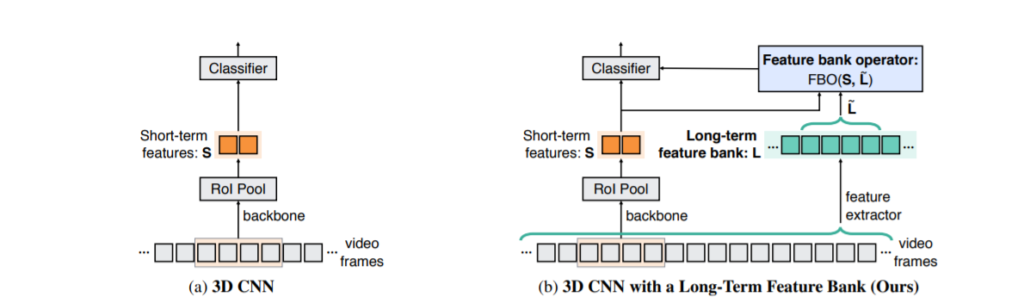
그래서 기존 모델로는 힘들었던 영상의 input이 길어져도 어느정도 성능을 유지하거나 더 높일 수 있는 결과를 내게 됩니다.

지난 번 A Multigrid Method for Efficiently Training Video Models에 대한 리뷰(http://server.rcv.sejong.ac.kr:8080/2020/11/08/cvpr20201%ed%8e%b8a-multigrid-method-for-efficiently-training-video-models/)는 2편이 나오지 않았는데 이번 논문의 리뷰는 2편이 나오길 바라겠습니다.