이번 리뷰 글은 논문 리뷰 연습을 위해 읽은 논문으로 해당 X-review는 예약설정을 통해 올릴 예정입니다.
해당 논문의 주제는 논문 제목에도 나와있듯이 열화상 영상의 feature extraction 및 정밀한 descriptor 표현 방법에 대하여 연구한 논문입니다.
Introduction
보다 정확하고 신뢰성있는 Feature extraction 및 descriptor는 image retrieval, scene reconstruction, SLAM 등등 다양한 robotics and computer vision task에 필수적입니다.
그래서 전통적인 hand-craft method나 learning based method 등이 활발히 연구, 제안되고 있으며 좋은 성능을 내는 방법론들도 존재합니다.
하지만 위에 설명한 방법로들은 일반적으로 color 영상에 적용되는 방법론들이기 때문에, 물체의 열을 읽어들이는 LWIR 영상에 기존 방법론들을 적용하게 되면 color 영상보다 저조한 성능을 얻게 됩니다.

그 이유는 LWIR 영상이 color 영상과 달리 장면을 잘 표현하지 못하는 textureless한 특성을 지니기 때문입니다. 그렇기 때문에 interest point 검출도 힘들며, 대응점간에 matching 성능도 매우 떨어지게 되는 것입니다.
이를 해결하기 위해 논문에서는 크게 enhancement network와 descriptor network를 통하여 Thermal 영상에 맞는 feature extraction 및 descriptor를 제안하였습니다.
Thermal Matching Architecture
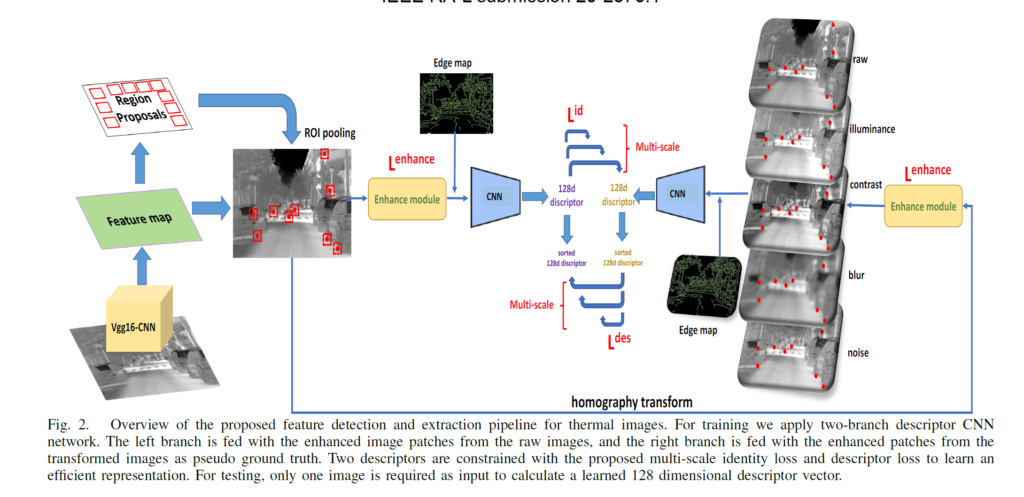
위에 그림은 전체적인 구조를 나타낸 것입니다. 간략히 설명하자면 enhancement network를 통해 Thermal 영상의 고질적인 문제 중 하나인 low resolution를 최대한 보완하였습니다.
또한 multiple image patch를 통하여 영상의 scale 특성을 부여하고, 단순히 intensity image 만으로는 정확한 descriptor 후보군을 뽑기는 어려우므로 Canny edge map을 추가하여 영상의 descriptor 후보군을 증가시켰다고 합니다.
Faster-RCNN based interest point detection
이제 조금 더 자세히 알아보도록 하겠습니다. 해당 논문에서는 Faster-RCNN 기법을 응용하여, thermal 영상과 color 영상에서의 interest point box를 검출한 후 검출된 박스들 사이에 차이를 최소화하는 과정을 통해 interest point detection을 학습한다고 합니다.
object detection과 달리, 논문에서는 Faster-RCNN을 interest point detection에 사용하는 것이기 때문에 검출된 point가 서로 다른 bounding box를 가질 필요 없이 항상 동일한 크기의 box를 가지면 된다는 점입니다.
그래서 해당 논문에서는 기존 Faster-RCNN에서 bounding box의 크기를 조정하는 값은 제외시켜버리고 interest point feature patch의 사이즈를 고정한체 학습을 진행한다고 합니다.
또한 학습을 진행하고자 thermal 영상과 정합되는 color 영상에 대해서 먼저 BRISK feature detection method를 통하여 interest point를 검출한 후 각 point를 중심으로 주변 16 × 16 크기의 patch를 추출한다고 합니다.
추출된 patch들은 thermal image의 key point 검출 및 bounding box regression을 위한 학습용 label이 됩니다.
이때 color image의 일부 proposal들은 textureless한 thermal image에서는 corner가 아닌 곳에서 보이는 경우가 종종 있는데, 이러한 문제를 해결하기 위해 raw label들을 edge 정보를 통해 재정의한다고 합니다.
예를들어 만약 raw candidate patch가 thermal 영상 속 canny edge 주변에 존재한다면 해당 label은 refined되거나 가짜 label로 제거됩니다. 이러한 과정을 통해 더 나은 검출을 위한 의미있는 후보 패치를 추출할 수 있게 됩니다.
Enhancement module for low resolution images
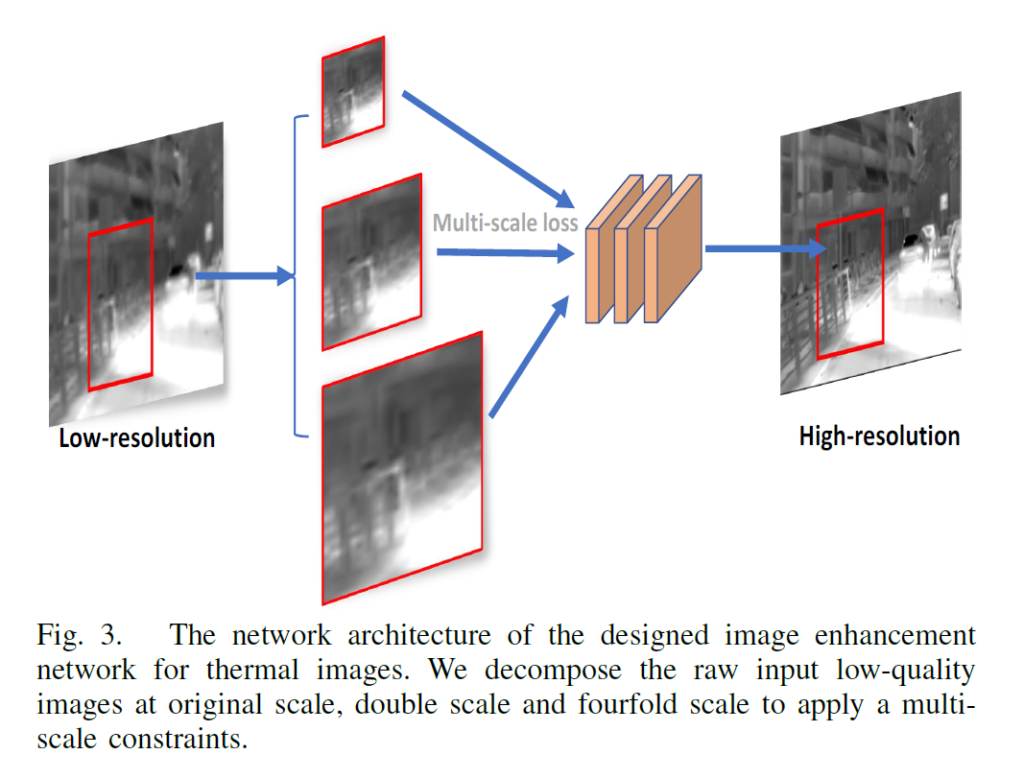
위에서도 간략히 설명드렸다시피, enhancement network에서는 low resolution을 보정해주는 과정도 존재합니다.
Fig 3과 같이 원래 영상의 2배 간격으로 영상을 upsampling한 후 각각에 영상들을 3개의 CNN layer에 입력으로 합니다. 그 다음 최종적인 High resolution 영상을 얻기 위해 3개의 feature map을 stack하게 됩니다.
여기서 눈여겨보실 점은 일반적인 Encoder-Decoder 형식의 네트워크가 아니고 단순히 3개의 CNN layer로 이루어져있기 때문에 Zero padding을 적절히 이용하여 영상의 input과 output size를 동일하게 맞추었다고 합니다.
해당 network의 loss로는 아래 수식과 같이 먼저 각 patch간의 유사도를 측정하는 Structured similarity(SSIM)을 사용하였다고 합니다.
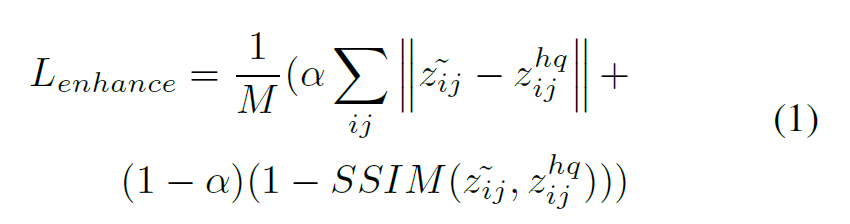
z 틸다는 reconstructed high-quality image를 말하며, z^{hq}_{ij}는 orginal high-quality image 즉 GT를 의미합니다. 알파는 학습을 위한 adjusted weight paramter라고 합니다.
Descriptor Learning
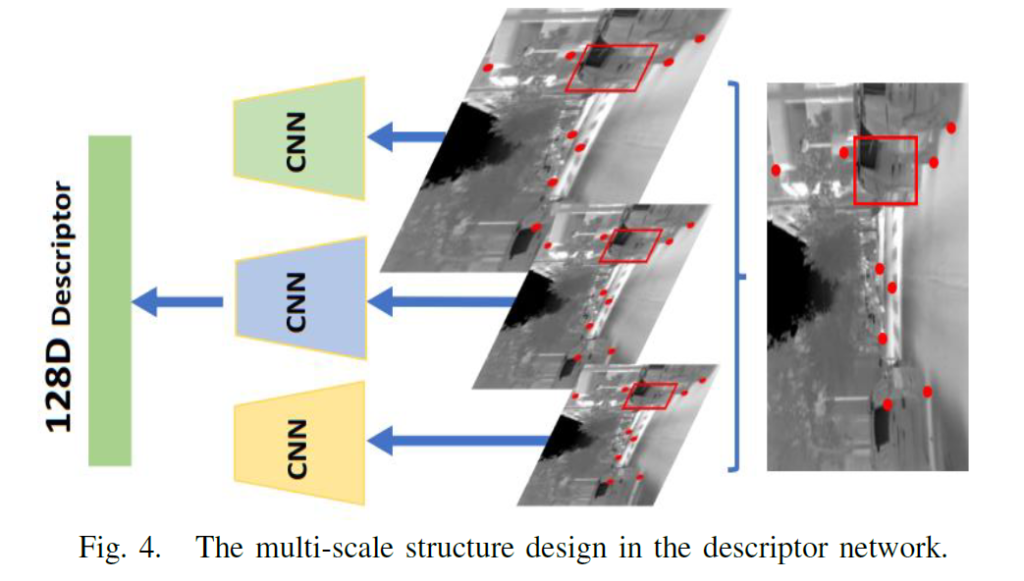
Descriptor Learning은 일단 8개의 CNN layer와 그 뒤에 batch normalization, ReLU를 붙인 일반적인 네트워크 구조입니다. CNN layer를 다 통과하면 그 뒤에는 fully-connected layer가 존재하는데, 해당 layer는 16 × 16 input patch를 128 차원의 normalized vector로 변환해주는 역할을 합니다.
또한 Fig 4 보시면 multi scale 형식으로 구조가 설계되었는데, 이를 통해 scale 및 viewpoint 변화에 더욱 강인하다고 합니다.
또한 raw intensity image에 추가로 Canny edge map을 추가함으로써 descriptor 후보군을 더욱 늘릴 수 있었는데, 이는 기존 Thermal 영상에서 올바로 대응되는 descriptor가 너무 적어 성공적으로 검출 및 매칭되기 어려운 단점을 보완해주게 되었습니다.
아래 그림은 edge map을 추가했을 때와 안했을 때의 feature detection 및 description의 수를 비교한 것입니다.

해당 학습과정에서는 크게 identity loss와 descriptor loss로 총 2가지의 loss를 사용하게 됩니다.
먼저 identity loss란 대응되는 패치로부터 나온 두개의 descriptor들이 서로 유사해지게끔 최적화하는 loss를 의미합니다. 더 자세히 말하자면, 이 loss는 검출된 interest point를 원본 영상에서 pair 영상으로 warping시킨다고 합니다.
즉 warping된 patch에서의 descriptor를 d_{i} , 그리고 그와 대응되는 patch의 descriptor를 \tilde{d}_{j}라고 한다면 Mean Square Error를 통하여 둘 사이가 유사해지게끔 강제하는 것입니다.
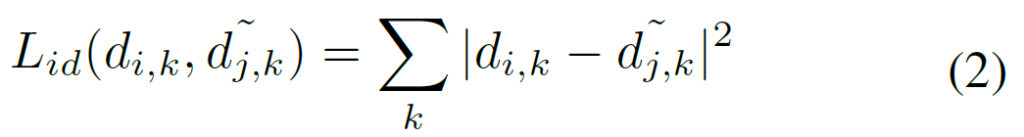
위에 식에서 k는 영상 내 keypoint의 순서를 의미합니다.
Descriptor loss는 매우 간단합니다. 해당 loss는 triplet loss와 유사한 positive와는 가깝게, non-matching candidates(negative)와는 멀게끔 설계된 loss로 아래와 같습니다.
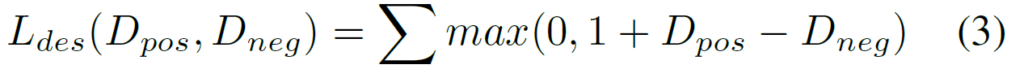
loss값이 작아지기 위해서는 D_{pos}는 작게, D_{neg}는 커져야만 하며 이는 positive는 가까이 negative는 멀리 되게끔 학습하는 목적과 적합한 모습입니다.
Experiments
평가에 대한 내용은 추후에 자세하게 보충할 예정이며 지금은 정량적 table과 정성적 결과만을 올리도록 하겠습니다.



‘enhancement network를 통해 Thermal 영상의 고질적인 문제(textureless, low resolution 등)를 최대한 보완한다’라고 하셨는데 enhancement network를 통해서 low resolution은 해결하는걸 알겠는데, textureless는 정확히 어떻게 해결한다는 건가요? 따로 이미지 자체의 textureless를 보완하기보다는 Descriptor 추출과정에서 Canny Edge등을 사용한 점이 textureless를 보완하는건가요?
좋은 질문 감사합니다.
댓글의 말씀처럼 enhancement network에서는 low resolution을 해결하고자 하는 네트워크가 맞고, thermal image 의 textureless는 edge map을 통해 보완하였습니다.
Thermal 영상의 고질적인 문제에 대해 적다보니 어쩌다가 enhancement network에서 low resolution과 textureless를 다 해결하는 것처럼 글을 작성해버렸네요 허허.
https://ieeexplore.ieee.org/document/9359356 에 논문이 개제되었으므로 해당 리뷰 글을 공개합니다.